







编辑 |ScienceAI
随着全球糖尿病患病率的逐年攀升,糖尿病已成为全球范围内极具挑战的公共健康问题。据统计,全球约有 10% 的人口受到糖尿病的影响。到 2045 年,全球糖尿病患者人数l a @ [预计将攀升至惊人的 7.83 亿。
然而,由于糖尿病医j I o U I j \生短缺、医疗资源分布不均以及患者自我管理能力的不P # B h \ Z n U足,糖尿病的管w r l 0 ! A f S e理和治疗仍面临重重困难。如何高效、智能化地管理糖尿病,已成为当前# k ( 4医学界; j – p和科技界共同关注的重要课题。
为应对这一挑战,上海交通大学清u k Q P + = E源研究院 MIFA 实验室与复旦大学附属中山医院# T b g y l * :内分泌科组成的研究团队,联手开发出一款名为 Diabetica 的糖尿病专用大模型。
Diabetica 能够为糖尿病患者提供个性化的医疗支持,并为医生提供更加高效的医学教育和p # A v u D Q b临床辅助工具。
糖尿病a A U s 6 , 9 8管理的挑战与机遇
糖尿病作为一种需要长期管理的慢性疾病,其复杂性不仅体现在患者需要持h # 4 U续控制血糖水平,还需要长期面对并u o ( m ( {发症的风险。此外,糖尿病的有效管理还需要患者、医疗团队、公共健康部门7 # , 3 – K :等多5 ; % W 5方的协同合作。然而,现有的医疗系统面临着诸多挑战:
1. 专业医师短缺:全球范围内,糖尿病专科医生数量远远不能满足日益增长的患者需求,医学教育和人才培养任重道远。
2. 医疗资源分配不均:优质医疗资源往往集中在大城市和发达地区,导致许多患者无法获得及时、有效9 @ @ J r # 4 ]的诊断和治疗。
3. 患者自我管理能力不足:由于缺乏专业知识和持续的指导,许多患者难以有效地进行自我管理,导致血糖控制效果不佳。
面对这些挑战,人] T 3 P工智能技术的快速发展为解决问题带来了新的可能。近年来,AI在医疗领域的应用日益广泛,涵盖了诊断辅助| T k \ j % z @、药物推荐、医学教育等多个方面,正在逐步成为医. C ` q w疗体系的重要补充。
然而,现有的AI工具多为单一任务导向,缺乏对自然语言的深入理解,难以在复杂的医疗环境中实现广泛应用。
大语言模型的出现,特别是专门E k 1 $ + T Z +针对特定疾病领域优化的模型,有望改变这一现状。
Diabetica} P ? 的诞生,正是为了应对糖尿病管理的复杂挑战,通过结合大模型的强大语言处理能力与糖尿病领域的专业知识,为医生、患者以及医疗教育提供全方位的智能支持。
Diabetica:为糖尿病管理量身打造的大模型
Diabetica 是一个专为糖尿c 2 # % , & l J病领域设计的大语言模型。研究团队通过对大量的医疗数据集进行预处理、优化和增强,最终构造了高质量的糖尿病数据集用于训练得到 Diabetica。
该模型不仅能够理解复杂的医学术语,还可以为不同层次的用户(A _ v k包括患者、医务人员等)提供个性化的建议和帮助,展现出了出色的糖尿病任务处理能力。

论文地址:https://arxiv.org/pdf/2409.13191
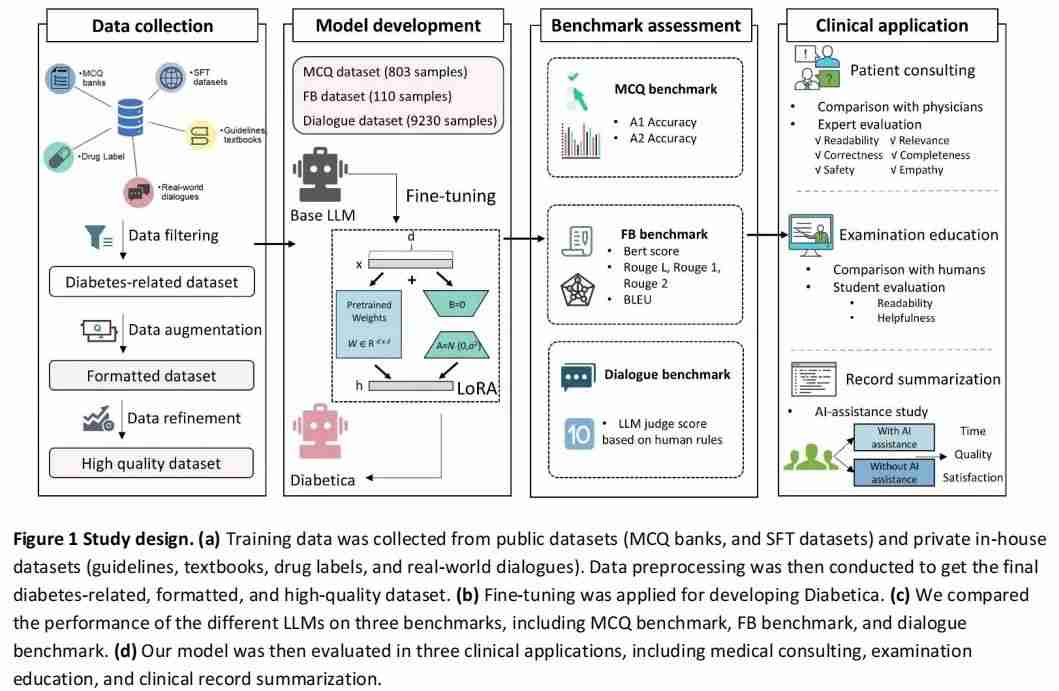
开发 Diabetica 的过程中,研究团队面临的首要挑战是如何构建高质量的糖尿病专业Q % J V数据集。为此,团队建立了一个完; C 7 S h P 8整的数据处理流程,包括如上图所示的几个关键步骤:
数据收集
团队从多个A d R y \ _ o v /来源收集数据,包G / k ,括公共数据源(如考试题库、开源医学对话数据集)和内部数据源(如糖尿病H = U S指南、教科书、药品说明书以及真实医疗对话)。
数据过滤
团队对收集到的原= , # V c始数据进行关键词筛选,以h X _ X A确保只选择真正与V | ( c糖尿病相关的数据。除此之外,为了避免重复数据对模型训练的影响,团队使用了「SemDeDup」中的去重方法,该方法利用预训练词向量模型生成的词向量进行聚类,在每个类里面识别并排除语义重复的数据点。
数据增强
为了构造指令对话数据,团队首先对糖尿病指南和教科书等数据集中的长o _ q p x P $ P文本,根据知识点进行分段,然后使用 GPT-4 生成基于每个A C } Z e d段落的对话数据。
对于考试题库的数据,团队利用 GPT-4 生成问题的链式推理过程和解答作为训练样本,保证了模型能够学到解题思路和答案背后的医学逻辑。
数据优化
为了提升数据质量和0 S S r | 0训练稳定性,团队还使用了一种自蒸馏方法实现数据优化。
如下图所示,该方法分为两个步骤:待训练的模型首先根据训练数据集中的每个指令生成一个初始回答。这个初始回答包含了模型原有的知识H V m 6 4 ) [ W,与模型内部分布一致。
之后,模型基于原始数据集中的指令和标准回答来修正它的初始回答,q P p b从而获得蒸馏后( ) J的回答。这个蒸馏步骤让模型生成一个与自己内部分布更加一致并且准确的答案。
最终,模型自蒸馏后的回答取代原始回答,n P F ^ j =用于该模型的微调阶段。该方法能8 Q E $ * % N e够减少j # % e _ @ u m i模型内部知识与新数据之间的分布m # o , & C x差异,使模型在训练过程中更加稳定。
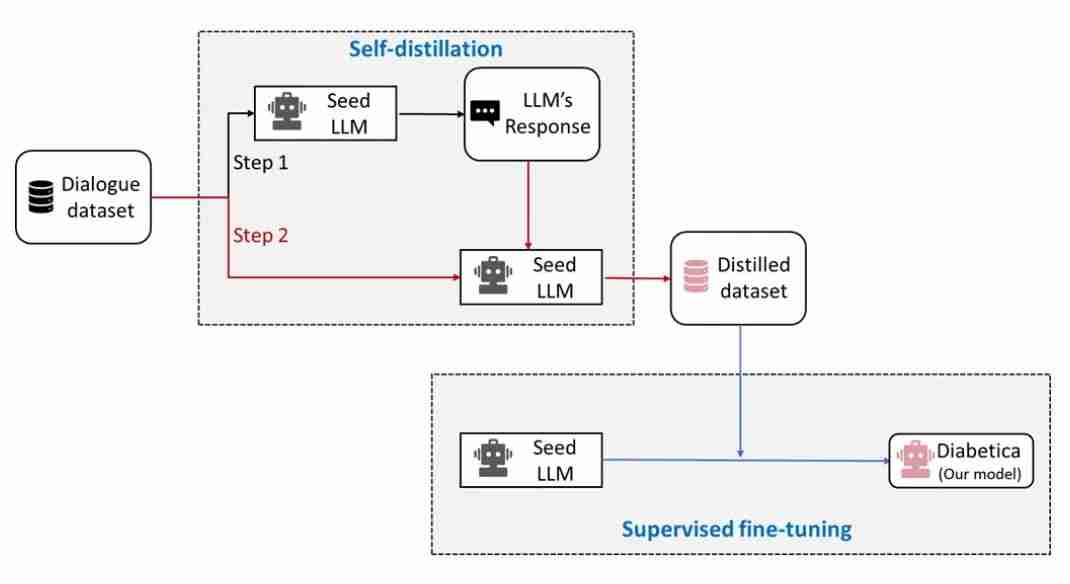
通过这一系列严格而精细的数据处理步骤,研究团队成功构建了一个高质量的糖尿病领域数据集。
在模型开发方面,团队采用了开源大模型 Qwen2: S t 1 z ) ]-7B-0 g + D { a l 6 OInstruct 进行微调。为了全面评估 Diabetica 的性能,研究团队设计并构造了多个针对糖尿病领域的评估基准,包括多项选择题测试、填空题测试和开放式问y ] L & ; f ^答测试。
对于开放式问答,团队中的医学对每道题事先制定了详细的回答准则,如准确性、完整性、同理心等。之后团队参考 LLM-asM n d O-Judg2 k ?e,使用 GPT-4 和 Claude-3.5 作为评审,给出不同模型回答的评分。
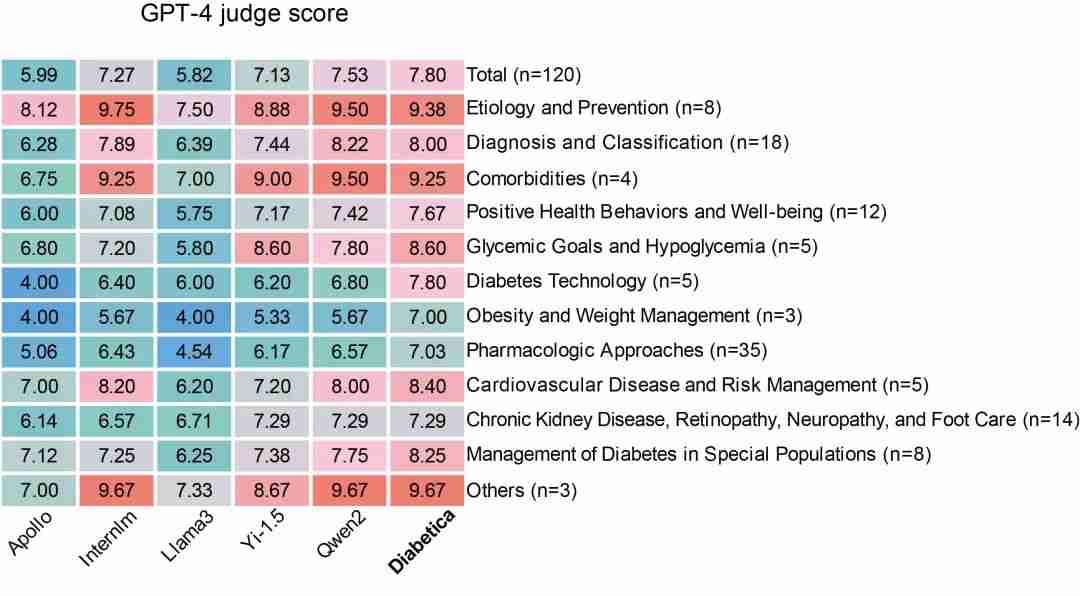
通过这些基准测试,团队详细比较了 Diabetica 与其他模型(包括开源和闭源模型)的表现。
下图的实验结果表明,Diabetica 不仅在所有任务中超越了其他开源模型,甚至在某些任务上表现超过了 GPT-4o、Claude-3.5-sonnet 等闭源商业模型,展示了其在糖尿病任务中的领先表现。

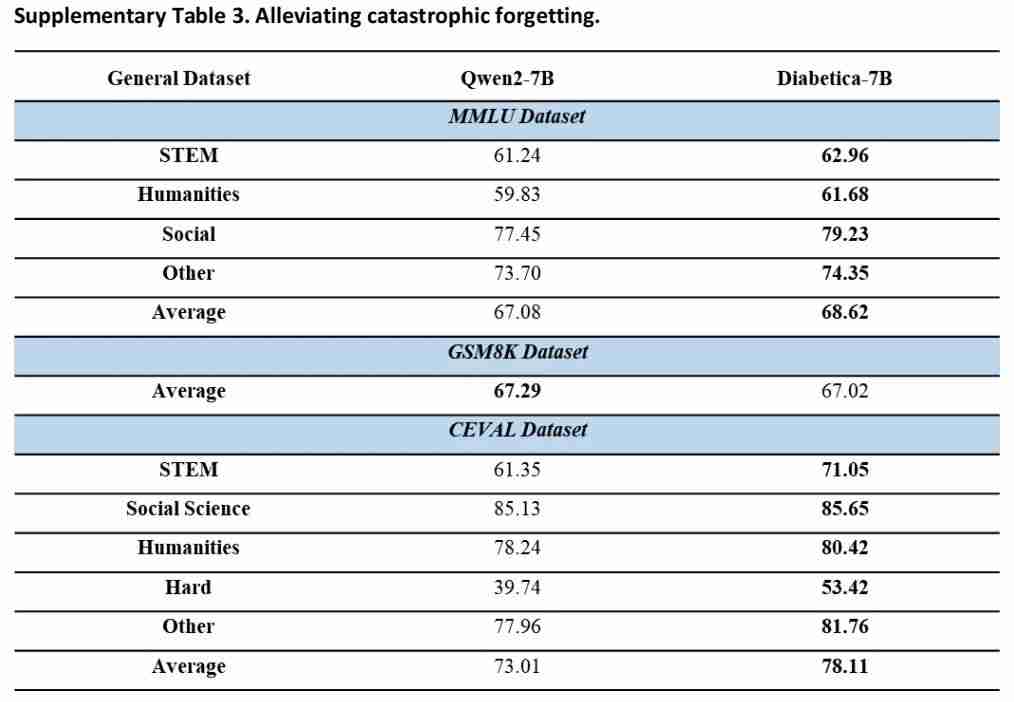
通过引入O w y l , X自蒸馏技术,团队还有效缓解了模型在微调过程中可能出现的「灾难性遗忘」问题,即模型在学习新任务时可能会遗忘之前学到的知识。
如下图所示,团队的实验结果发现,与训练之前相比,Diabetica 在 GSM8K 的分数仅下降 0.27 分% = + s h ` v,在 MMLU 和! : N Z C-Eval 上甚. d 5 5 o至还有所提升。这种自蒸馏的训练方法使得 Diabetica 不仅w f u – 2 e I n {加深了对糖尿病专业知识的理解,也极大程度地保留了基础模型的通用语言理解能力。
Diabetica 的全方位临床应用
研究团队对 Di/ u y ` s ; . 5 Mabetica 的能力进行了广泛的临床评估,验证了其在多种实际任务中的有效性。
医疗咨询
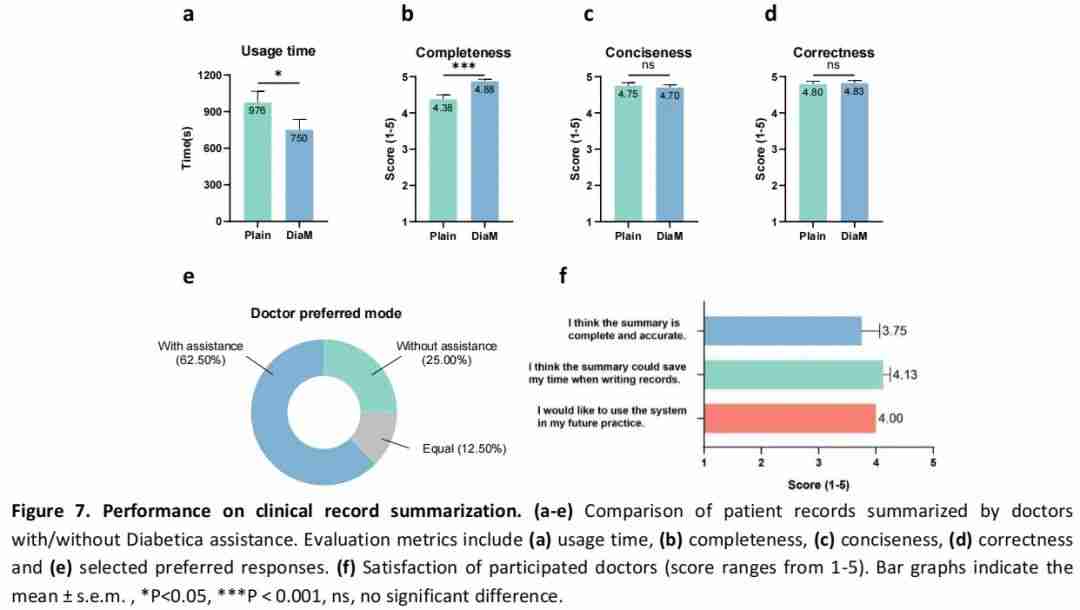
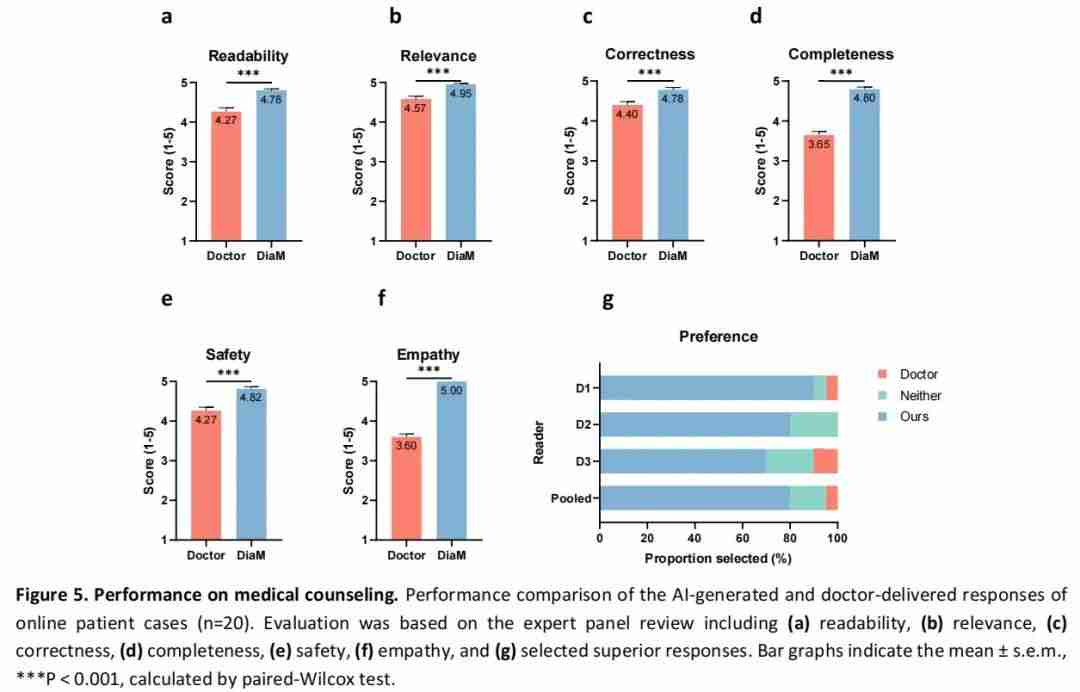
Diabetica 在医学咨询任务中展现出强大的自然语言理解和生成能力。研究团队选取了 20 个真实的在线糖尿病患者咨询案例,让专家评审组对 Diabetica 和人类医生回答进行评估。
结果显示,Diabetica 的回答在可读性、相关性、准确性、完整性、安全性和同理心等多个维度的表现均超过了人类医生的回答。
值得一提的是,在同理心维度上,Diabetica 获得了专家评审组的一致好评,甚至达到了满分。这一结果显示了大模型在情感交流方面的巨大潜力。
医学教育
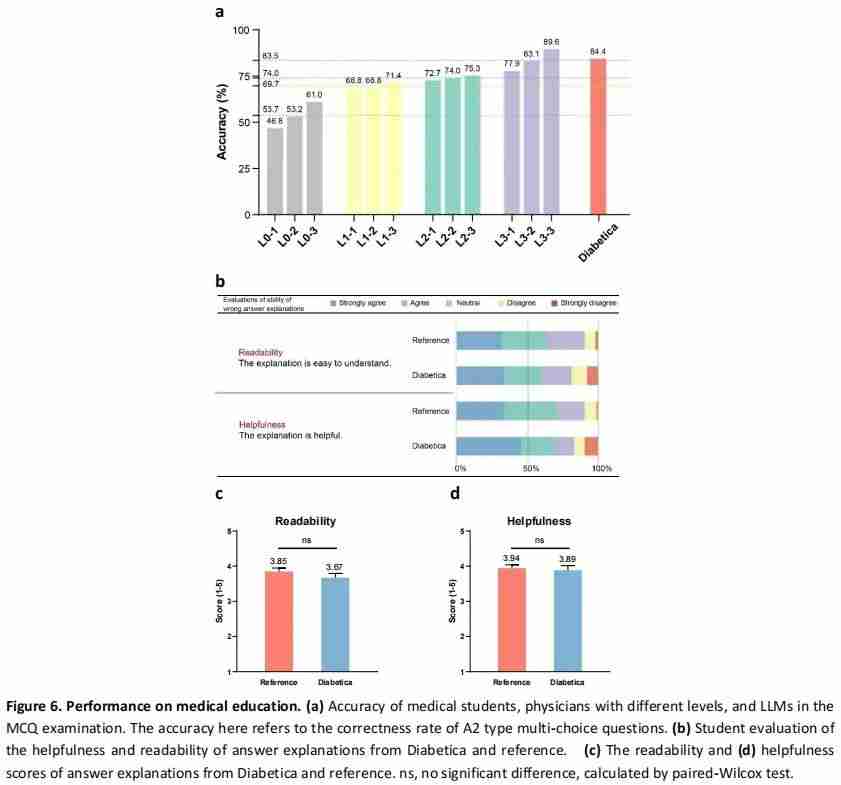
在医学教育领域v ` F t # = q 5,Diabetica 展现出了超越人类的潜力。研究团队设计了一系列多项选择题测试,内容涵盖糖尿病h – O 5 d v V的诊断、治疗和管理等方面。测试对象包括医学学生、初级医生、高级医生以及 Diabetica 模型。% n . t –
结果显示,Diabetica 在这些测试中的准确率达到了 84.4%,不仅超过了医学生和初级医生,甚至略高于高级医生 83.5% 的正确率。这一结果充f y W u } c 7 5 7分证明了b x U s C \ + m z Diabetica 在糖尿病专业知识掌握方面的卓越能力。
同时,Diabetica 不仅能够给出l , G g正确答案,还能为每道题目提供详细的解释。研究团队将模型生成的解释与标准教科书的解释m N , x ( m : H进行比较,发现 Diabetica 的解释在可读性和帮助性方面与教科书相当。
临床记录总结
在繁忙的临床工作中,医生们常常需要花费大量时间整理和总结病历。Diab$ 2 vetica 在这一领域展现出了出色的应用价值。
研究团队设计了一项AI辅助的交叉研究,比较U j w 8 q A B ) c了使用 Diabetica 辅助和不使用 AI 辅助两e } X V S S I种情况下医生撰写病历的效率和质量。
研究团队发现,使用 Diabetica 协助撰写病历的医生,完成病历的时间平均缩短了约 23%。同时,在病历的完整性评分上,使用 Diabetica 辅助的病历显著高于未使用模型的\ } ` e情况。
Diabetica 能够快速分析患者的详细病史,并将其整理为结构化的摘要,包括病程、症状、体征、血糖水平、并发症以及既往治疗信息等关键内容。这不仅大大提高h | 2 E R了医生的工作效率,还确保了病历的全面性和准确性。
Diabetica 家族
除了 7B 的大模型之外,Diabetica 家族还– – +包括一个小模型版本,即 Diabet} \ s , % n } Fica-1.5B,适用于计算资源有限的场景。
例如,Diabetica-1.5B 可以在配置较低的笔记本电脑上运$ v 2 3 # * K + r行,而 Diabetica-S f |7B 则适V o w G合更高性能的 GPU 设备。
同时,Diabetica-1.5B 在多个糖尿病评估数据集上也超越了 Llama3-8K y 7B 等大模型。
研究团队已经将代码和模型开源。
以上就是上交大、复旦中山团队开发糖尿病专用大语言模型,助力个性化糖尿病管理1 s | D ` N S _ c的详细内容!
 微信扫一扫
微信扫一扫 












{kind=link}