







AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交W * t p流与传播。如果您有优秀的工作想要分B 0 I P Q g享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
论文第一作者林宏彬来自香港中文大学 (深圳) Deep Bit 实验室,导师为李镇老师。实验室专注于利用人工智能技术进行跨学科研究,例如自动驾驶的三维感知、医学成像和分子理解的多模态数据分析和生成等。研究领域涵盖计算机视觉、机器 / 深度学习和 AI4Science。感兴趣的同学可以在主页上获取更多信息htu 4 7 b !tps:O O 5 J \//mypage.cuhk.edu.cn/academics/lizhen/

-
论文链接:https, p X 3://arxiv.org/pdf/2405.195 k F + O682 -
GitHub:h\ ? 1 = y 8 Yttps{ l V ? V K://github.com/Ho` L U f Pngbin98/MonoTTA

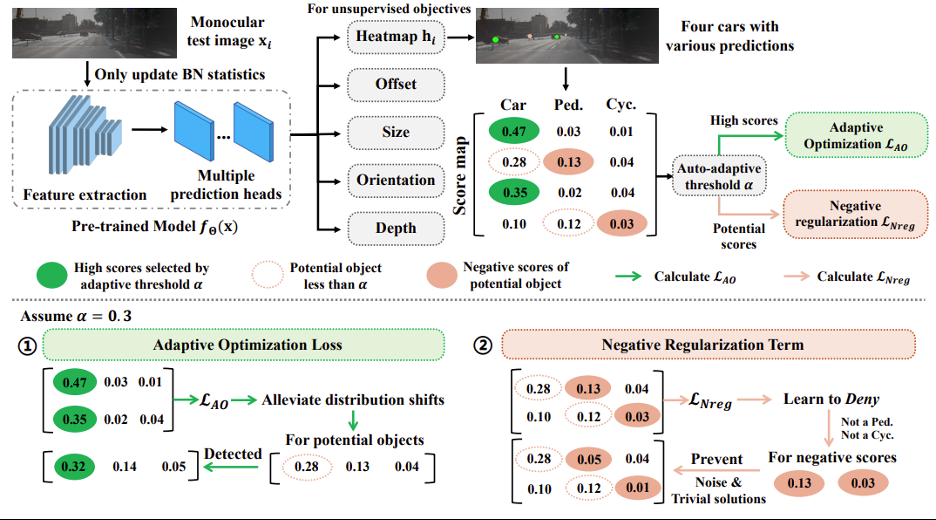
 来利用可靠物体对象子集进行模型适应,从而缓解域外分布的测试数据检测分数下降问题,并挖掘出更多潜k w ) J ) u在对象:
来利用可靠物体对象子集进行模型适应,从而缓解域外分布的测试数据检测分数下降问题,并挖掘出更多潜k w ) J ) u在对象:
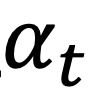 是在迭C { K ` U 7 p v代伦次 t 下的自适应阈值,这是考虑到实际测试场景的分布差2 e j C异是未知的,因此开发了一种自适应策略,e V . \用于在测试图像中自动识别可靠的高分对象。
是在迭C { K ` U 7 p v代伦次 t 下的自适应阈值,这是考虑到实际测试场景的分布差2 e j C异是未知的,因此开发了一种自适应策略,e V . \用于在测试图像中自动识别可靠的高分对象。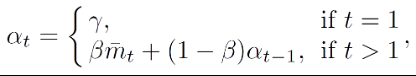
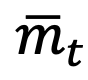 为所有检测到的物体对象的平均分数, 是衰减系数,而 则是遵循原方法的预定义物体检测阈值。B 为批量大小,
为所有检测到的物体对象的平均分数, 是衰减系数,而 则是遵循原方法的预定义物体检测阈值。B 为批量大小,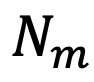 为单张图片下的最大检测物体对象数目,
为单张图片下的最大检测物体对象数目,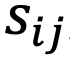 则对应每个检测物体的z c q m w ~具体分数^ 8 u i 4 a | |值。
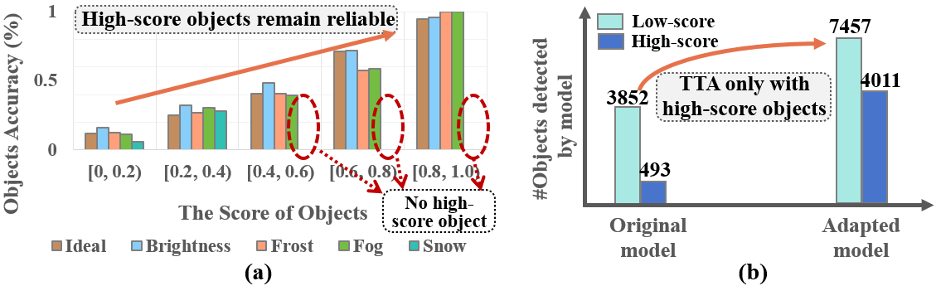
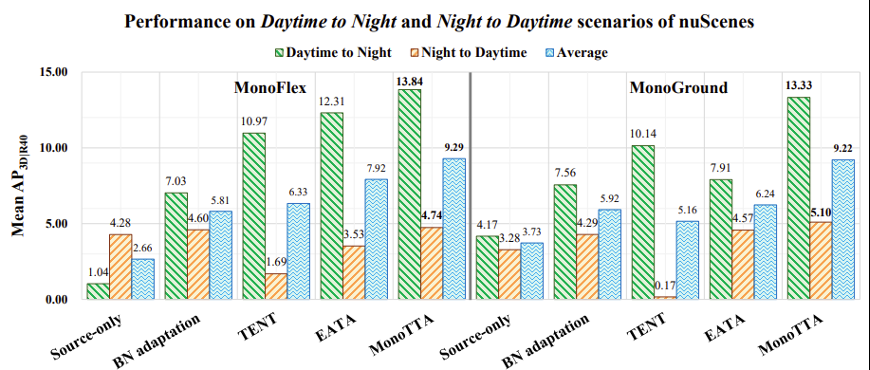
则对应每个检测物体的z c q m w ~具体分数^ 8 u i 4 a | |值。基于负标签优化的伪标签噪音缓解:虽然通过 的优化,模型能有效缓解漏检问题。但像我们先前讨论的,一种极端情况是数据分布差异还会导致高分对象的极度稀缺,如上图 4(a)中的雪天场景,此时大+ ! J ? G –多数对象呈现低分,无法利用高分样本以W A | g Y m i Q u优化模型。为此,学者们开发了一个负标签正则化项,以合理利用众多低分物体对象以~ t h v进行~ v p Y b B – 6负标签学习。一方面,负标签正则化项
的优化,模型能有效缓解漏检问题。但像我们先前讨论的,一种极端情况是数据分布差异还会导致高分对象的极度稀缺,如上图 4(a)中的雪天场景,此时大+ ! J ? G –多数对象呈现低分,无法利用高分样本以W A | g Y m i Q u优化模型。为此,学者们开发了一个负标签正则化项,以合理利用众多低分物体对象以~ t h v进行~ v p Y b B – 6负标签学习。一方面,负标签正则化项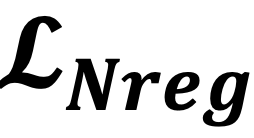 允许模型通过众多存在噪声的低分对象进行模型适应,从而I S r P a 8 F H使得模型在缓解分布变化后获得更多高分物体? . ` : . u B ]对象;另一方面,这一正则化项也防止了模型过度拟合噪声和简, j m )易解,例如给一个对象的所有类别分配高r 3 g分。
允许模型通过众多存在噪声的低分对象进行模型适应,从而I S r P a 8 F H使得模型在缓解分布变化后获得更多高分物体? . ` : . u B ]对象;另一方面,这一正则化项也防止了模型过度拟合噪声和简, j m )易解,例如给一个对象的所有类别分配高r 3 g分。
 的物体对象,基于每个类别的k l / . O具体频率
的物体对象,基于每个类别的k l / . O具体频率 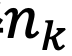 ,求和得到最终损失值:
,求和得到最终损失值: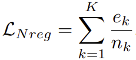
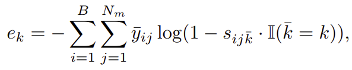
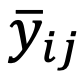 是常数权重p / 4 1,
是常数权重p / 4 1,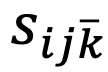 则是具体检测物体对象对于l y ) F a I负类别 kt 3 Q D p 下的检测分数S K # 3 8 E。
则是具体检测物体对象对于l y ) F a I负类别 kt 3 Q D p 下的检测分数S K # 3 8 E。 会在模型适应中扮演了更重要的角色。因为它可以通过只利用低分数的对象(即否定负面类别)来缓解分布偏移,换句话说,使得模型在极端场景下仍然能够减轻分布偏移并获得更多相对高分的对象,从而为的计算奠定了关键基础。
会在模型适应中扮演了更重要的角色。因为它可以通过只利用低分数的对象(即否定负面类别)来缓解分布偏移,换句话说,使得模型在极端场景下仍然能够减轻分布偏移并获得更多相对高分的对象,从而为的计算奠定了关键基础。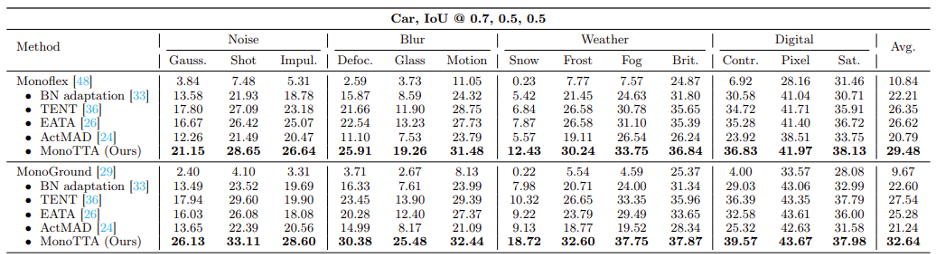



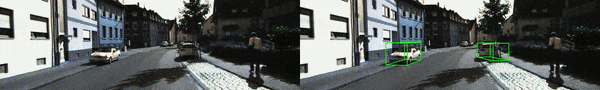
以上就是单目三维检测实时泛化,纯视觉自动! W E X b h _ y *驾驶鲁棒感知方法入选ECCV 2024的详细内容!
 微信扫一扫
微信扫一扫 













{kind=link}