







AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhL b q q Lixin.com;zhaoyunfeng@jiqizhixin.com
对于人[ o R类而言,一旦掌握了 “打开瓶盖” 的动作,面对 “拧紧螺丝” 这样的任务通常也能游刃有余,因为@ Z P y 8 & J v这两者依赖于相似的手部动作。然而,对于机器人来说,即使是这样看似= 9 v ` ; 2简单的任务转换依然充满挑战。例如,换成{ S 8 x另一种类型的瓶盖,机器人可能无法成功打开。这表明,目前的机器人方法尚未充分让模型学习到任务的内在执行逻辑,而只是单纯的依赖于数据拟合。
针对该问题,来自中山大学和华为诺亚等单位的研究团队提出了一种全新的原语驱动的路径点感知世界模型,借助 VLMs 作为机器人的大脑,理解任务之间的动作关联性,并通过 “世界模型” 获取对未来动作的表征,从而更好地帮助机器人学习和决策。该方法显著提升了机器人的学习能力,并保持良好的泛化性。

-
论文v ! X 5 U Q地址:https://arxiv.org/abs/241# A O A 5 d Q \ G0.10394 -
项目主页:https://a; ^ J ? 5 S e Ubliao.github.io/PIVOT-R/
研究动机
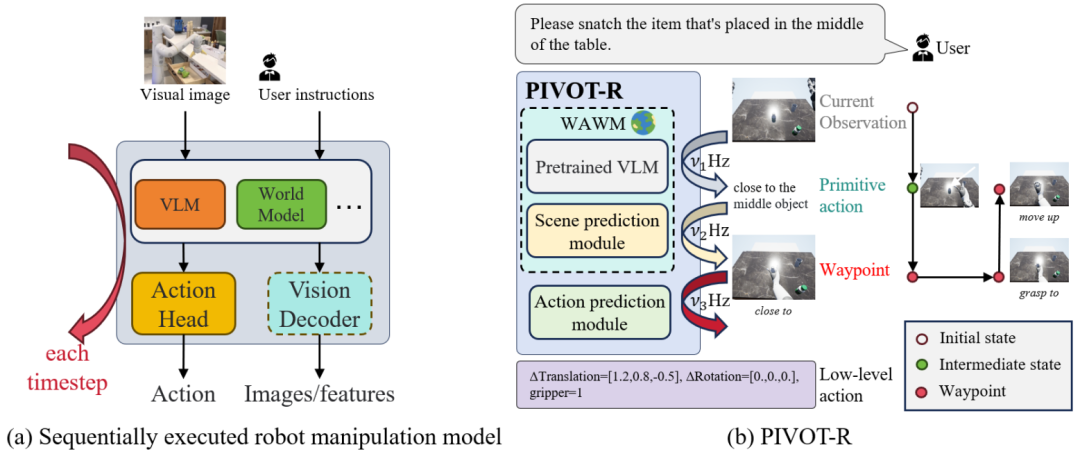
当前,现有机器人操作任务有: _ Q ,两个关键问题:
-
机器人模型在开放世界中表现差且不稳定:许多机器人操作模型虽然能够处理复杂任务,但往往直接J v \ =将用户指令和视觉感知映射到低层次的可执行动作上,而忽略了操作任务中关键状态(路径点)$ % ; r的建模。这种方式容易使模型记住表面数据模式,导致模型在开放环境中表现脆弱。模型缺乏对关键路径点r 4 ! K v的预测,使得每5 Z U q V I K a个动作的随机性可能t J r逐步放大,降低了任务的执行成功率。 -
计算效率低:随着模型的增大(例如 RT-2, RT-H),I M (运行速率随之降低,无法满足机器人任务实时性的需求。
为了解决上述问题,研究团队提出了 PIVOT-R,一种P 9 ( r原语驱动的路径点感知世界模型。如上图所示,对比\ \ = $ } p 0 * 3左图现有的方法,右图展示了 PIVOT-R 通过关注与任务相关的路径点预测,提升机器M J 6 m 6 V人操作的准确性,并设计了一个异步分层执行e f $ Q器,降低计算冗余C L & u d,提升模型的执行效率。
这样做有几个好处:{ # X G $ Q m : T
-
它使得模型可以更好的学习任~ – % N b u ^ @务与动作之间的内在关联性,减少其他干扰因素的影响,并更好地捕捉不同任务之间的相似性(例如,拧瓶盖和拧螺丝的动作是相似的,拿杯子和搭积木都有一个抓住物体的过程),从而使得模型可以在多@ a D u / D任务数据下学习到可迁移的知识。 -
通~ \ t ( b / : , 8过世界模型建模的方式获得对未来关键动作的表征,避免了5 x ! / _文本语言带来的模糊性、不确定性。 -
通过异步执行的方式,确保各模块独立运行、互不阻塞,从而有效避免了大模% ( C 5 / ( p j x型导致的低速率问题。
研究方法
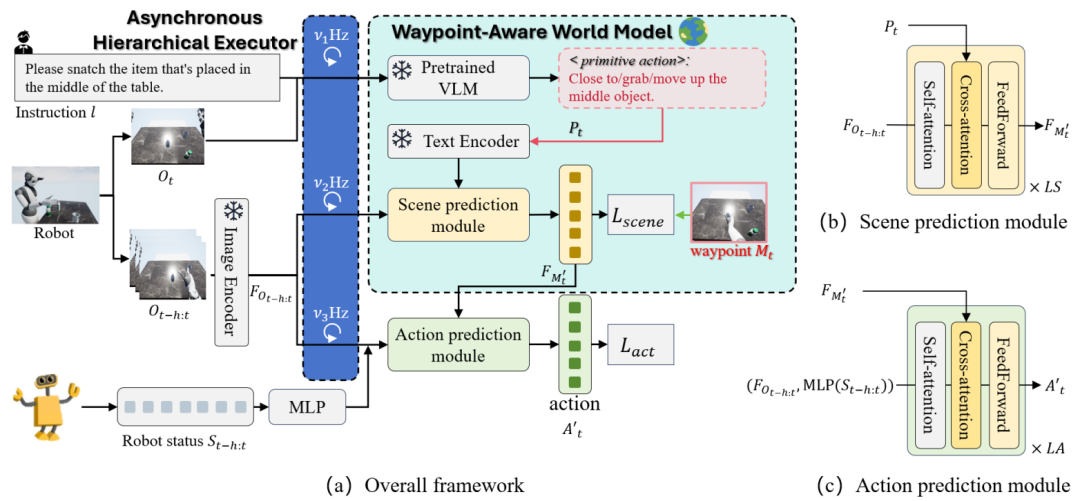
原语动作解析
PIVOT-R 的第一个核心步骤是原语动作解析,这一步通过预训练的视觉 – 语言模型(VLM)来解析用户的语言指令。VLM 可以将复杂的自然语言指令转换为一组简单的原语动作,例如 “靠近”、“抓取”、“移动” 等。这些原语动作为机器人提供了操作任务的粗略路径。
具体流程如下:
-
用户输入的语言指令(\ S d ; M ~ H S例如 “请给我那个杯子”)首先u % P O y . ~ ]被输入到 VLM 中,VLM 会将其解析为与任务相关的原语动作(如 “靠近杯子”、“抓取杯子”)。 -
原语动作作为提示,指导机器人在接下来的步骤中专注于特定的操作轨迹点。这种方式确保机_ A Z ?器人不会被复杂的环境因素干扰,而是明确知道每个动作的目的。
路径点预测
在原语动作解析后,PIVOT-R 的下一步是路径Z | z j点预测。路径点代表了机器7 C o C s w人操控过程中一些关键的中间状态,例p y { ` I L k 7如靠近物体、抓取物体、移动物体等H ( 7 S U + f。通过预测路径点,PIVOT-R 能够在机器人执: B = # &行任务时提供明确的操作指导。具体来说,通过一个 Transformerh _ + V K 架构的模型,预测路径点对应的视觉特征,为后续的动3 y c E s M ? n作预测模块提供指引。
动作预测模块
动作预测模块负责根据预测的路径点生成具体的低层次机器人动作。它以路径点为提示,结合机器人历史状态(如位置、姿态等& ) G g a !),计算下一步应该执行的v k ] v V J G动作。该模块使用轻量级n $ 5 7 v \ p的 Transformer 架构进行动作y G }预测,确保计算效率和性能的平衡。这一模块的设w e T – ] d s计重点在于低延迟和高\ L A精度执行操控任务。
异步分层执行器
此外,PIVOT-R 还引入了一个关键的+ C i U A A执行机制,即异步分层执行器。与以往的机器人模型不同,PIVOT-R 并不对所有模块在每一步都进行同步更新,而是为不同模块设置了不同的执行频率,以多线程的方式进行异步更新,从而提升执行速度。
实验
作者在具有复杂指令的 SeaWave 仿真环~ * p W t ] 0境和真实环境下进行实验。
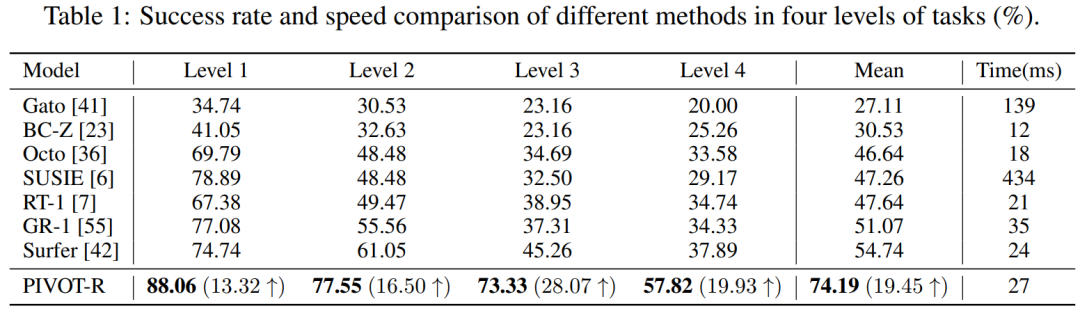
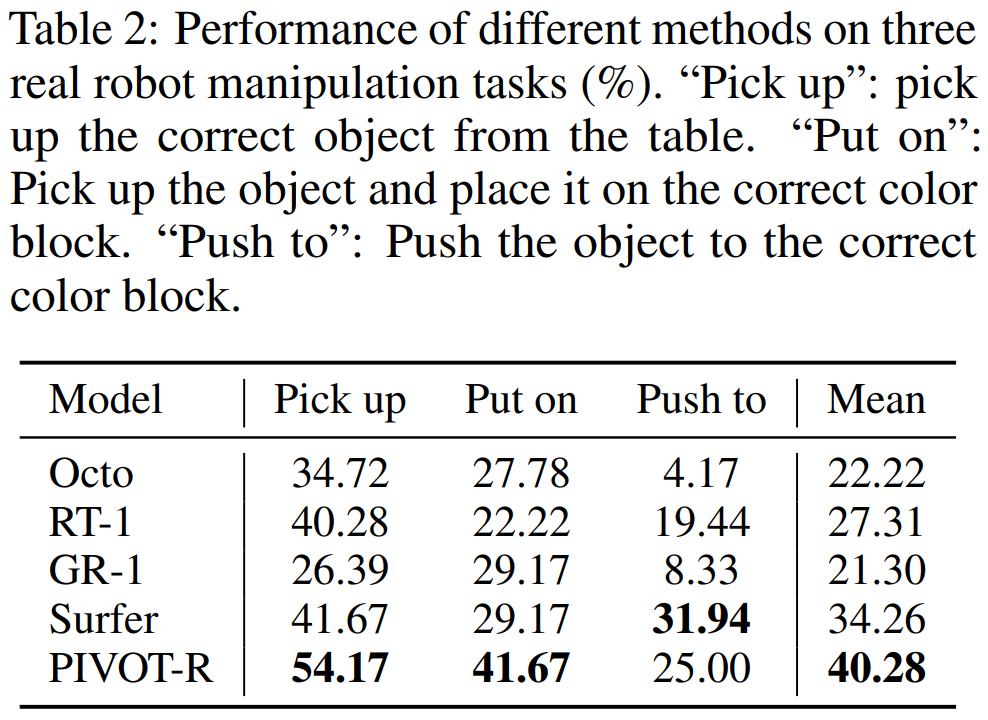
如 Table 1 和 Table 2 所示,PIVOT-R 在仿真环境和真实环境都取得了最优的效果,同时,模型的速度和 RT-1 等方法速度相j P I –近,没有因为使~ E u V R Y ; .用大模型而导致速度变慢。
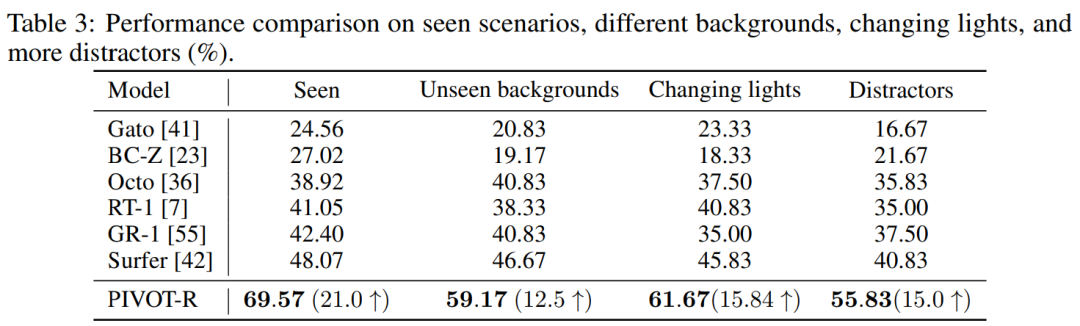
作者也在 SeaWave 上做了泛化性测试,在三种A 0 ? =泛化性测试场景下,PIVOT-R 仍保持远高于其5 ? 5 _ d ! ? F v他模型的成功率。
研究总结
PIVOT-R 通过引入原语动作驱动的路径点感知,显著提升了机器人在复杂操控任务中的性能。该模型不仅在执行效率上具备优势,还能* z E @ G /够更好地应对复杂、多变的环境。该方法: x [ & T = 8 F在仿真环境和真实环境操纵下表现优异Z – g : { N c q _,为机器人学习提供了一个新范式。
以上就是NeurIPS 2024 | 机器人操纵世界模型来了,成功率超过谷歌RT-1 26.6%的详细内容!
 微信扫一扫
微信扫一扫 










![ICLR 惊现[10,10,10,10]满分论文,ControlNet 作者新作,Github 5.8k 颗星](https://img.zhengjiaxi.com/wp-content/uploads/2025/01/173303804188199-480x300.png)



{kind=link}