







AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作n w 8想要分享` O . ~ p A,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoD h \ I d Wyunfeng@jiqizhixin.com
本文作者来自于中国科学技术大学,上海人工智能实验室以及香港中文大学。其中第一作者黄启栋为中国科学技a E v术大学三年级博士生,主要研究方向包括多模态大模型(MLLM)和可信 / 高效 AI,师从张卫明教授。
是否还在苦恼如何[ . / – 9 d :评估自己预训练好的多模态 LLM 的性能?是否还在使用并不靠谱的损失 Loss,困惑度 Perplexity(PPL),上下文 In-Context 评估,亦或是一遍遍地通过有监督微调(SFT)之后下游测试基准的分数来判断自己的预训练是否有E a y % u y F &效?
来自中科大等单位的研究团队共同提出了用来1 z s } 9 Q有效8 : ) ; i &评估多模态大模型预训练质量的评估指标 Modality Integration Rate(Mi i k / i S n ? IIR),能够快速准确地评Q h ] } X 1 P估多模态预训练的模态对齐程度。

-
标题:Deciphering Cross-MoL g 3 x 5 cdal Alignment in Laj 6 6 \ Vrge Vision-Language Models with Modality Integration Rate
-
论文:https://arxiv.org/abs/2410.07167
-
代码:https://github.com/shikiw/Modality-Integration-Rate
研究背景
预训练(Pre-tr\ $ 6aining)是现有多模态大模型(MLLM)在训练过程中一个不可或缺的阶段。& k G不同于大型语言模型(LLM)的预训练,多模态预训练的主要目标聚焦G e \于不同模– N F y y 7 k态之间的对齐。随着近两年的发展,多模态预训练已经从轻量级图像 – 文本对的对齐,发展为基于广泛多样的多模态数据进行深层次模态集成,旨在构建更通用的多模态大模型。
然而,多模态预训练的评估对于业界仍然是一个未被充分解决的挑战。现有最常用的评估手段为通过进一步的有监督微调(SFT)来测试在下游基准上的模型能力,但是其k Z ^ |伴随的计算成本和复杂性不容忽视。另外有一些方法通过借用 LLM 的预训练评估指标,包括损D q 2 3 L h失值 Loss、困惑度 PPLO C L 和上下文 In-Context 评估等方式,在多模态预训练评估中都8 7 q a被证明是不3 R r稳定和不可靠的。
研究者们通过在不同规模的高质量预训练数据上预训练 LLaVA-v1.5 的 7B 模型,用上述不同的方法评估其预训练质量,并与有监督微调之后在下游测~ \ # \ t /试基准上的得分进行对照。0 ( / – ^ L j如下图所示,损失值 Loss、困惑度 PPL、以及上下文 In-Context 评估都无法准确的对应 SFT 之后在下游测试基准上的模型性能,而本文提出的模态融合率 MIR 则能完美对应。
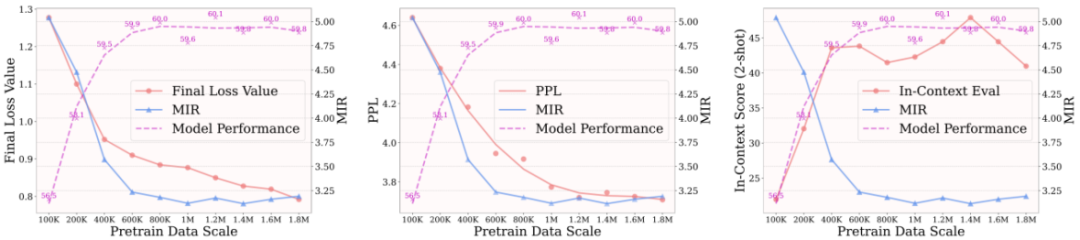
实际上,PPL 等指标的不适用主要由g j S _ M u 1于 LLM 与 MLLM 在预训练目标上的差异。LLM 预训练主要学习建模语言的基本模式,而 MLLM 预训练则侧重于缩小不同模态之间的差距。如果用多个不同来源的图像和文本数据,并在 LLaVA-vL M u1.5 的大模型输入层去可视化它们的特征分U X : ? $ 7 6布,会发现尽管图q S . 9 \ 2 ]像或文本内容多样,但在每种模态内,它们的分布相对均匀,而模态之间则存在明显F @ E t ]的分布差距,如下图(左)所示。
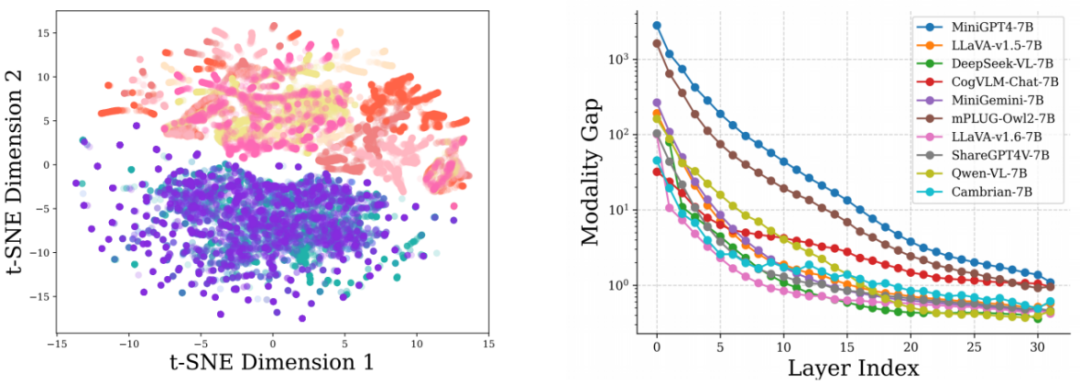
如上图(右)所示,通过进一步计算现有 MLLM 的在大模型不同层中的模态差距,会观察到浅层的时候仍然有较大差距,但当到越来越深的层,这一差距逐渐缩小,这表明 MLLM 在训练过程中仍需要学习对齐不同分布,以理解新h a 6 ? Y x h C引入的模态。
技术方案
本文提出模态融合率 MIR,能够用于评估多模态预训练的3 b g ] : Q 0 { =跨模态对齐质量。该指标能准确反映各种预训练配置(如数据、策略、训练配方和架构选择)对模型性能的影响,而无需再进行有监督微调 SFT 并于下游测试基准上评估。
对于一个预训练的多模态大模型 M = (E, P, D),其中T # 3 E 表示视觉编码器,P 表示视觉语言+ U G 0 $ O映射模块,D = (D_t, F) 表示包含分词器 D_t 和 K 层 transforme~ S o m # 0r 的底座大模型 F。当输入] ( 5 c U d ) J一组 “图像 – 文本” 对 {v_n,( ] \ j S L + t_n}, n = 1,…, N 给模型,会从大模型第 k 层 F_k 得到该层关于数据对 {% . 9 q 5 l Rv_n, t_n} 的视觉 toku h k P { + i G #en 特征 f_k^{v_n} 和文本 token 特征 f_k^{t_n},即

研究者们将多个样本的特征 f_k^{v_n}= U C 合并到一起得到 f_k^v,同理 f_k[ y O^{t_n} 可以合并得到 f_k^t,并且定义 f_{k, i}^v 为第 i 个视觉 token 特征,f_{k, j}^t 为第f M x z q – q j 个语言 token 特征。
文本中心归一化
由于越深层的 token 特征在数值绝对尺度上明显比浅层的大,并且不同模态特征间在绝对尺度上存在差异,直接使用 Frechet 距离等度量. G ~ & O函数、或是把所有 token 特征统一归一化后再使用度量函数~ ` $ R 4都是不合适的。为此,研究者们设计了一种文本中心的归一化方法,对于 f_k^t 中的总共 s 个文本 tokJ + m ] ] K 9 aeo T h i F 8 N 1 .n 特征,计算尺度因子:

然后对第 k 层对应的视觉特征和文本特征都使用该因子进行放缩,在保证跨层对比合理性的同时,保持模态间绝对尺度带来的差异。
离群值筛除
许多工作如 Stream, F P j N |LLM [1]、Massiv1 – { G 1 B Pe Activations [2] 都提到,有极少部分绝对数值异常大的 token 会用来在注意力模块的 SoftMax 计算中使总和填充到 1。为了避免此类离群值对整体统计分布的影响,Z N i _ & Y这里使用 “3-l E : o g ksigma” 的准则对于所有 f_k^v 和 f_k^t 中的离群值进行筛除。以下用 omega 表示这个操作。
模态融合率
在经过文本中心归一化以及离群 token 筛除之后,模态融合率 MIR 可以通过累和大模型逐层的模态域间距离来得到:
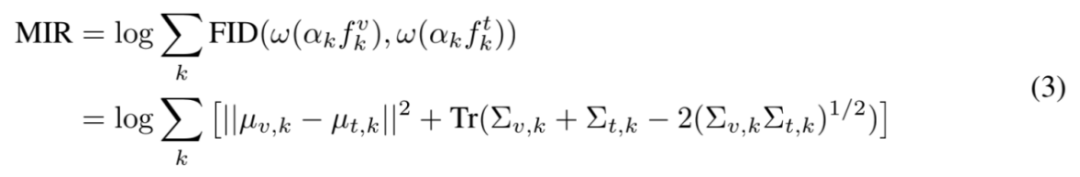
其中,mu_{v, k} 和 mu_{t, k} 分别~ % P是处理后视觉 token 特征和文本 token 特征的均值,而
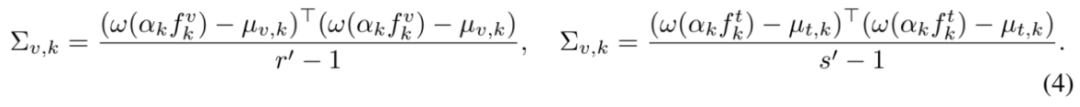
对应于各自的协方差计算。最后的平方根项通常在 PyTorch 中计算缓慢,这s l x s T D ! o \是由于大模型的特征维度普遍较高。因此研究者们使用 Newton-Schulz 迭代近似的方式估计该项,在大大提高计算速度的同时,保证实践中误差不超过 1%。总体上来看,越低的 MIR 代表着越高的预训练模态对齐| b p T e质量。
可学习模态校准
在对 MIR 的探究推导过程中,证明了底座大模型在训练过程中展现出的在浅层逐渐缩& h Z 6 s 7 E J小模态间差距的倾向。这促使研究者们重新思考多模态大模型中^ V * A一些继承自大型语言模型的设计是否不利于促进跨模态对齐。为此,研究者们提出了 MoCa,一个可插拔_ N W R轻量级的可学习k _ , &模块,来. _ c 3 W 8 0 C i促进跨模态对齐。简单来说,即对于每一层的视觉 token 特征单独进行一个可学习的缩放和偏移:

其中缩\ O z 1 ?放向量 u 初始化为全一向量,偏移向量r h d y j v 初始化为全 0 向量,两者随着模型一起训练,但是基本不增加额外参数量。
实验探究
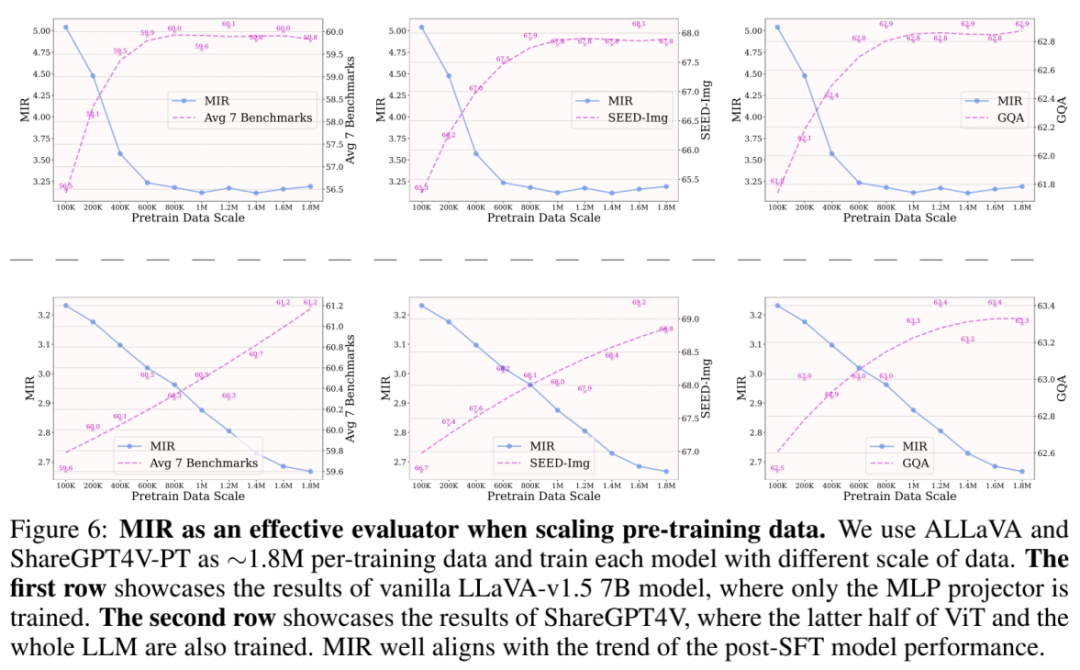
研究者们首先展) } o T _ g 4 4 0示了 MIR 在在扩大预训练数据规模时衡量预训练质量的有效性。这里采O G B用两种预训练策略:1) 仅训练 MLP 投影模块;2) 解锁视觉编码器后半部分和整个 LLM。在第一种策略下,SFT 后的性能在 800K∼1M 数据规模时逐渐改善但趋于饱和。而在使用第二种策略时,即使在 1.8M 数据规模下,性能仍持续显著提升。该结果说明了了 MIR 在扩大预训练数据时的有效性,也说明了适当地放开视觉编码器或 LLM 在大规模数据上有持续改善预训练的效果。
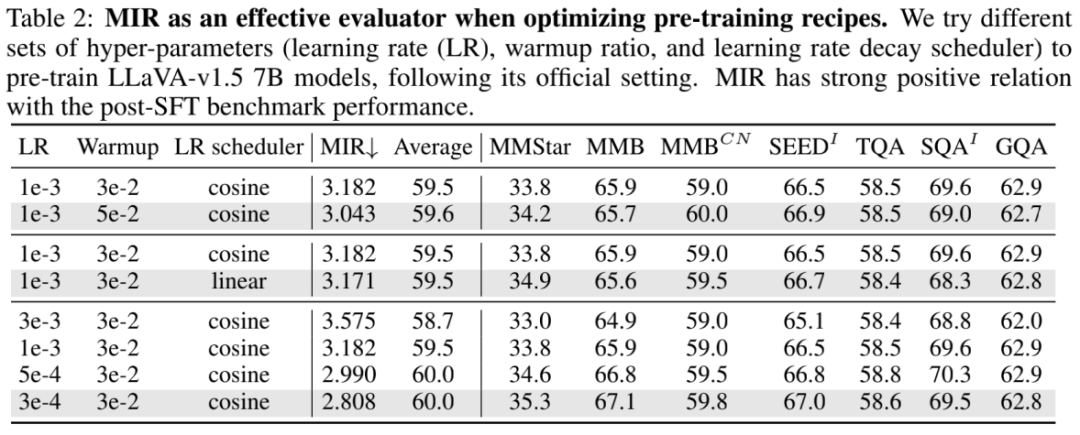
研究者们也探究了2 y $ l $ MIR 在超参数调整、预训练策略选择上的有效k U t 8性。在超参数调整方面,研究者们发现 MIR 与 SFT 后下游测试基准性能之间存在正相关,这说明 MIR 直接反映不同训练超参1 0 F数= i m & ; h对于在预训练质量的影响,以后对照 MIR 就可以实现预训练调参炼丹!
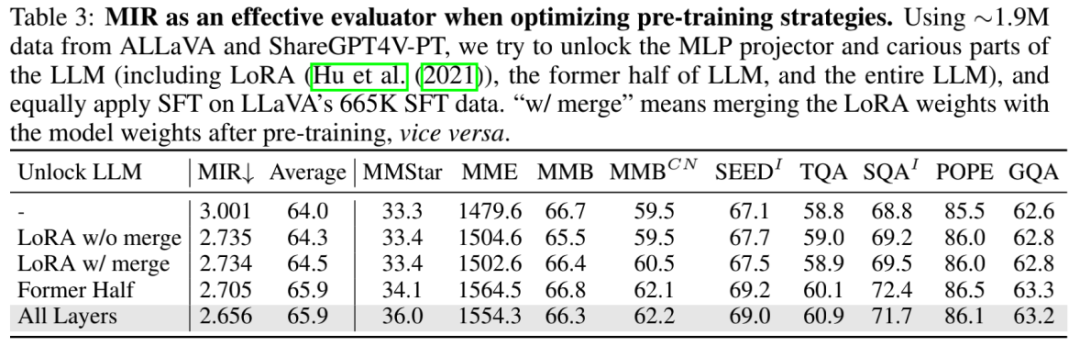
在训练策略方面,研究者们探讨了 MIR 如何指导选择有效的预训练放开策略。结果显示,放开 LLM 显著降低了 MIR,且显著增强下游基准上的表现。
同时,MIR 也可以帮助选择一些有利于跨模态对齐的模块设计。如下图所示,当使用不同的视觉; E j i N B J H l语言投影模块结构时– / m K,MIR 可以很准确的对应到 SFT 之后的测试基准性能。

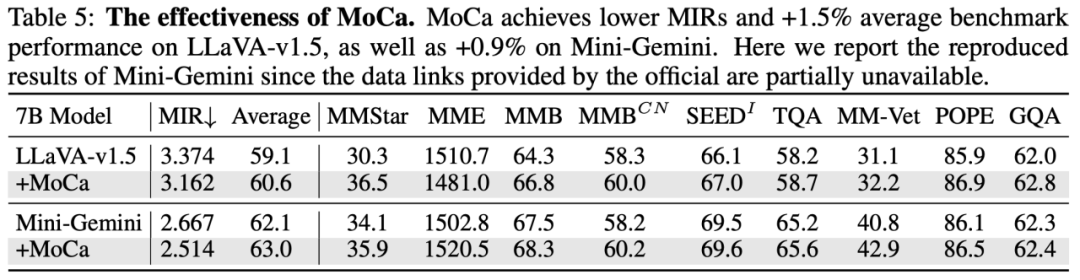
同样,所提出的可学习模态校准 MoCa 也可以有效帮助不同模型在下游测^ a q o G 5 G f试基准上涨点,并取得更低的 MIR。
本文仍有较多其他方面的实验和探索,有兴趣的同U w B 1 M g |学可以参考原文!
参考文献:
[1] Xiao et al. Efficient Streaming Language Models with Attention Sinks. ICLR, 2024.
[2] Sun et al. Massive AcX w { O D Jtivations in Large Language ME + i = X h hodf z 2 s ~ z D \els. COLM, 2024.
以上就是高效评估多模态预训练对齐质量,中科大提出模态融合率MIR的详细内容!` = R
 微信扫一扫
微信扫一扫 













{kind=link}