昨晚,DeepSeek 上线了全新的推理模型 DeepSeek-R1-Lite-Preview ,直接冲击 OpenAI o1 保持了两个多月的大模Z = 9 | y 7 p A !型霸主地位。
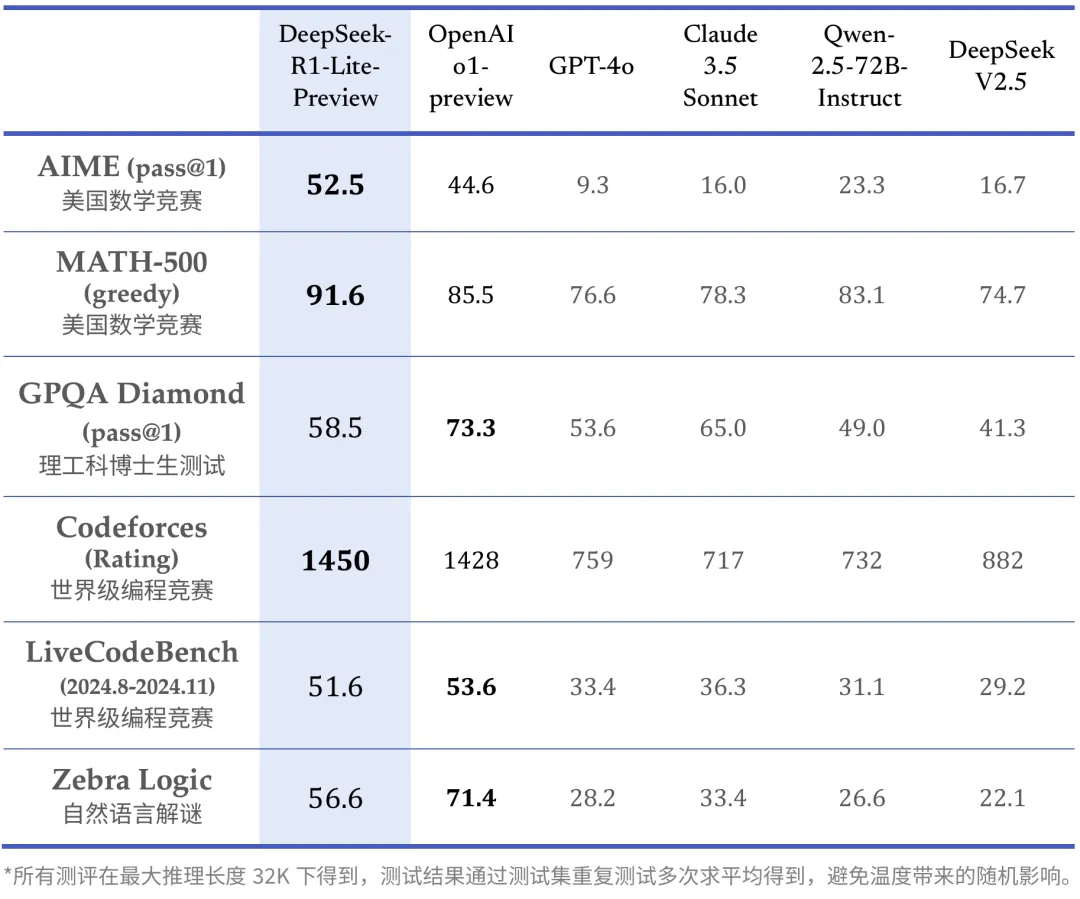
在美国数学竞赛(AMC)中难度; / S I等w O # @ / G A 5级最高的 AIME 以及全球顶级编程竞赛(codefo– 5 , $ y .rces)等权威评测中,DeepSeek-R1-Lite-Preview 模型已经大幅超越了 GP+ R w 7T-4o 等顶尖模型,有三项成绩还领先于 OpenAI o1-preview。
背后的秘诀,就是「深度7 9 L & R 4 \ | ^思考」。
更多的强化学习、原生的思维链、更长的推理时间,能让大模型的性能更强,这在领e e s V m域内已经是广泛共识。这种模式其实非常像人类大脑的深度思考。
与 OpenA^ A = I w H (I o1 有点不一样的是,DeepSeek-Q = x ^R1-Lite-Preview 会在回复中展示「思路链」推理G M O c,也就是响应查询和输入的不同链或「思路」,并解释它在做什么以及为什么这样做。
就像是解题时,有人喜欢将每一步骤都详尽地写在卷子上,而 DeepSeek-R1-Lite-Preview 更进一步:把内心 OS 也都写出来了。
DeepSeek 官方表示,DeepSeek R1 系列模型使用强化学习训练,推理过程包含大量反思和验证,思维链长度可达数万字。已经发布的 DeepSeek-R1-Lite-Preview 使用的是一个较小的基座模型,尚未完全释放长思维链的潜力。
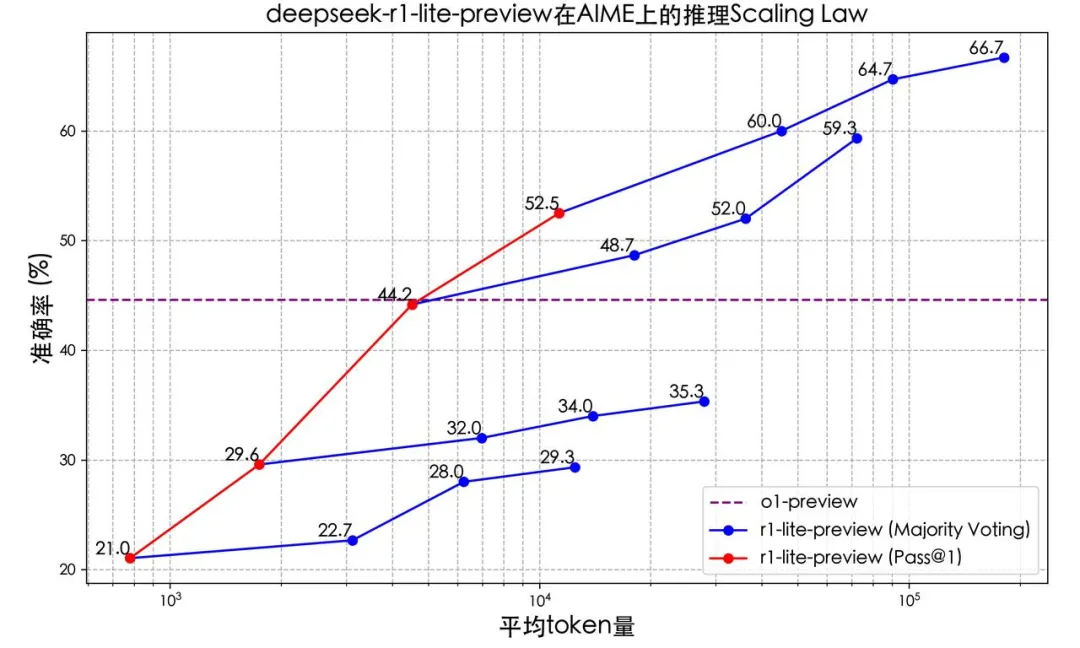
对于用户的 Prompt,DeepSeek-R1-Lite-Preview 会有n U n l e J n一个很长的推* w d ^ r ` 8理过程。如上图中的红色实线所示,模型所能达到的准确率与所给定的推理长度呈正相关。且相比于传统的多次采样 + 投票(Majority Voting),模型思维链长度增加展现出了更高的效率。
最惊艳的是,发布即上线:所有用户均可通过官网开启与 DeepSeek-R1-Lite-Preview 的对话,但注意要先在输入框中打开「深度思考」模式,每天限制 50 次使用。
体验地址:http://chat.deepseek.com/
不得不说,对 o1 直接发起/ O k冲击的 DeepSeek,着实让国内 AI 社区振奋了一把:
图源:https://www.zhihu.com/question/4689435060/answer/36575793425
由于 DeepSeek-R1-Lite-Preview 目前仅支持网页使用,没有发布完整代码供独立第三方分析或基准测试,也没有通过 API 提供 DeepSeek-R1-Lite-Preview 以进行同类独立测试,也没有解释 DeepSeek-R1-Lite-Preview 是如何训练或构建的博客文章或技术论文,大家心中其实还有许多Q I \ B 9 ]的「问号」。
但 DeepSeek 已经表示,正式版 DeepSeek, D ; v 4 1 = / *-R1 模型会完全开源,还会公开技术报告,部署 API 服务。
图源:https://www.zhihu.com/quesm z l 6 4 A v Btion/4689435060/answer/36604051127
回想起上一次,DeepSeek-V2 的开源和 API 降价,直接引发了国产大模型厂商的降价浪潮。同样的力度再来一波,不知道大家如何顶住。
与 OpenAIH } : k 4 U 2 o1 相同的是,根据问题的复杂程. t p U A k ~ 3 y度,它也需要「思考」数十秒后再回答。
虽然有些过程中的思路在人类看来可能毫无意义,甚至是错误的,但据初步测评,DeepSeek-R1-Lite-Preview 回复的最终整体准确率还是比较高的。
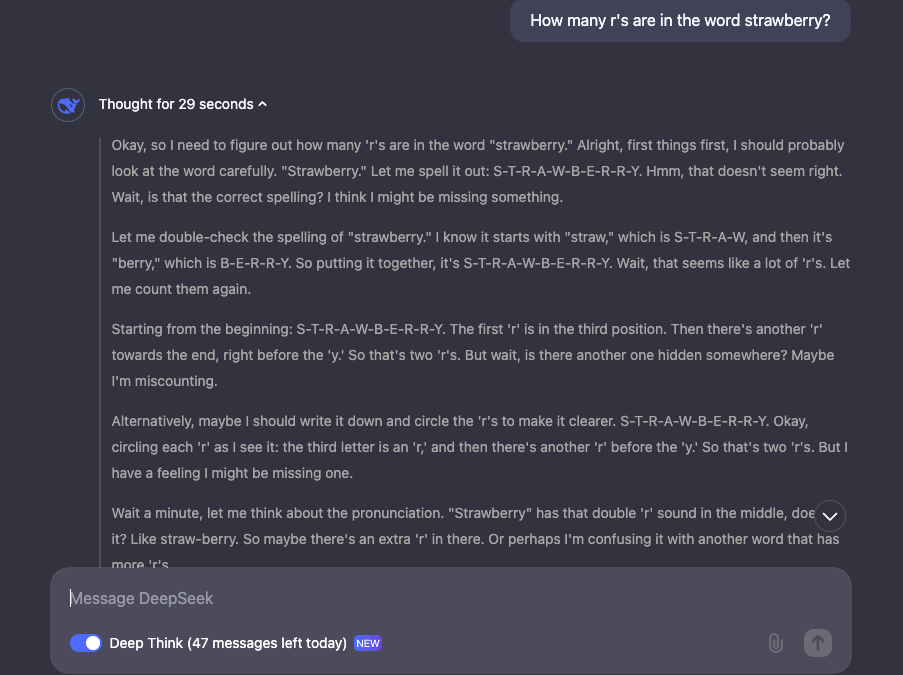
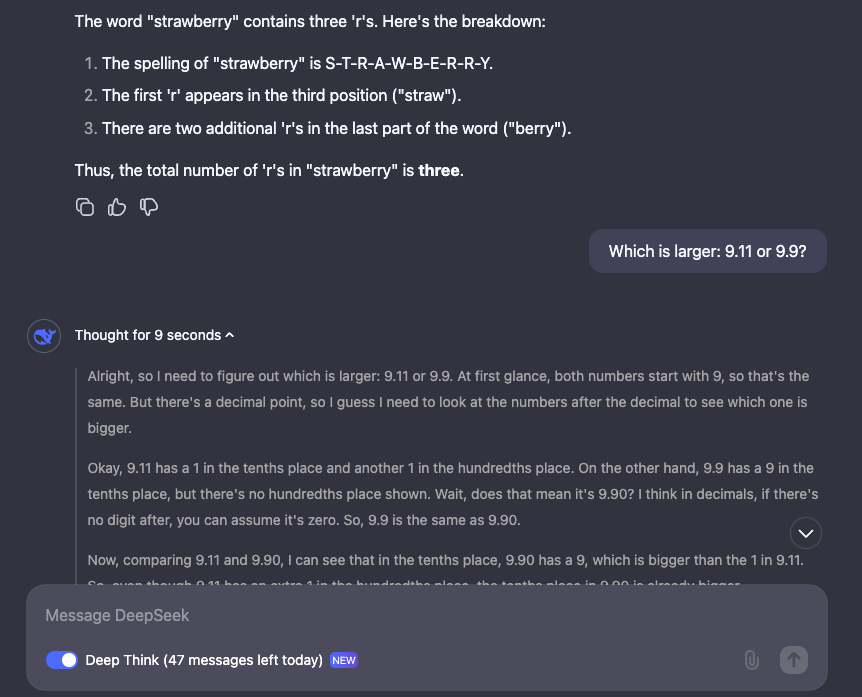
比如它可以回答 GPT-4o 和 Claude 系列都翻车过的问题R J F ] H —— 经典陷阱题「Strawberry 这个词中有多少个字母 R?」和「9.1y i 3 ? b1 和 9.9 哪个更大?」。
有用户在 DeepSeek Chat 上使用这些 Prompt 进行测试,回复结果和思考用时情况如下:
Strawbert ( @ U !ry 这个词中有多少个字母 R?用时 29 秒。n L G
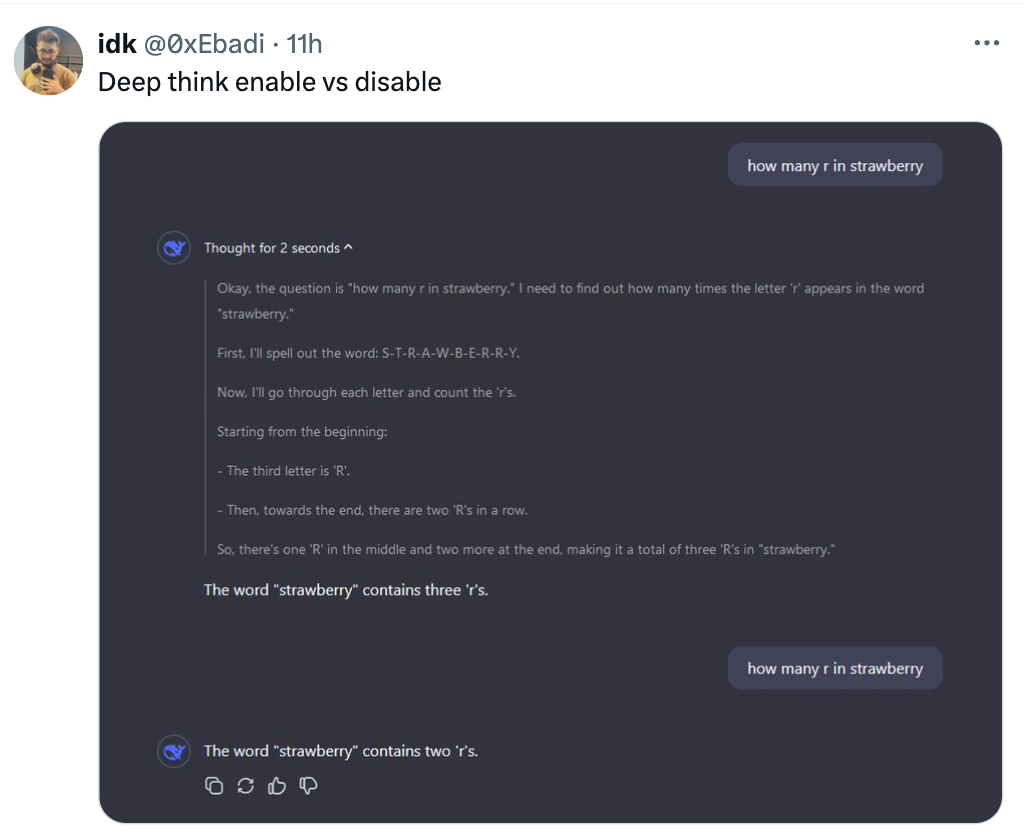
不过在数草莓的问题上,R1-Lite-Preview 有时也会困惑,数出「只有 2 个 r」的答案:d I 5 ( c Q
本站也实测了一把,似乎对于中文B ? * y K ` [,R1-Lite-Preview 的准确率更高:
对于需要动脑的问题,R1-Lite-Preview 的表现也可圈可点,比如它可以破解行e c ( s l Y y K测题; A n的逻辑陷阱:
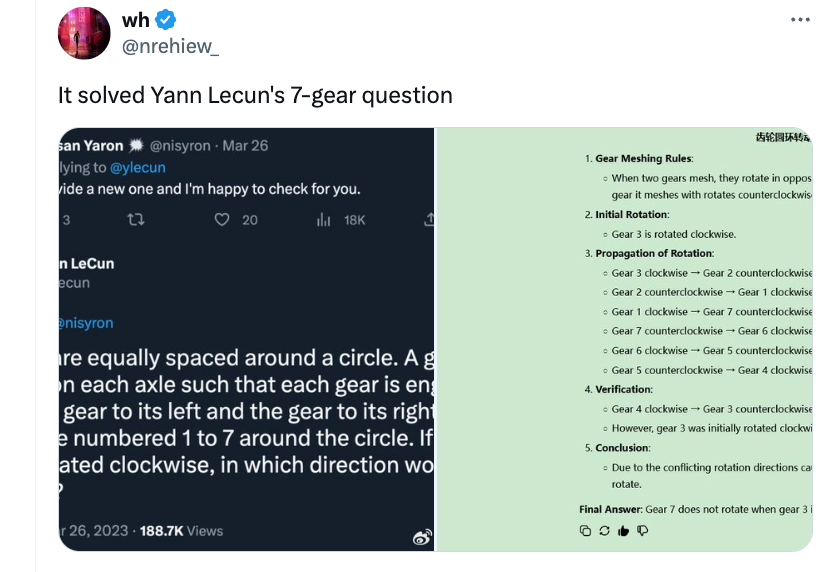
由 LeCun 提出的物理题:a J b 3 ? n W X圆周T j 1 s R Z & b上均匀分\ 8 . E i布了 7 根轴,每根轴上都有一个齿轮。每个齿轮都与其左边和右边的齿轮啮合。齿轮从 1 到 7 编号,依次沿圆周排列。问题是:如果齿轮 3 顺时针旋转,问齿轮 7 会沿什么方向旋转?
接下来,给 R1-Lite-Preview 上点强度,看看它能否笑对大学物理的噩梦:《电磁学千题解》。
在 34 秒内,它根据题意列出了对应的公式,得到了正确答案:
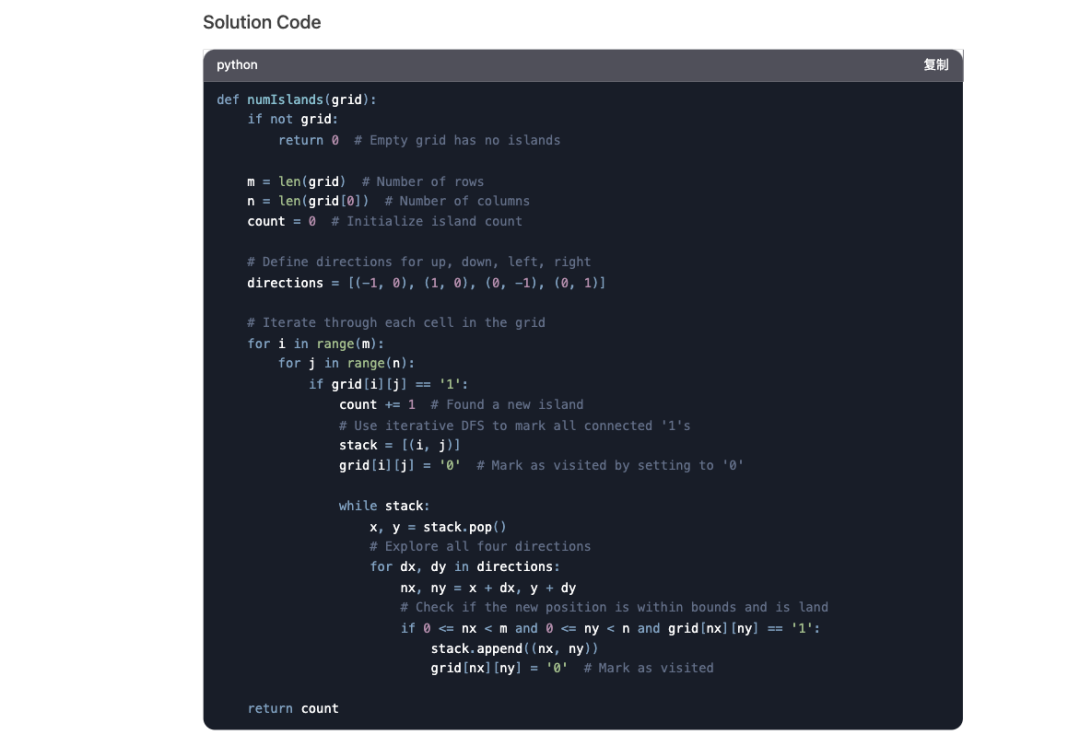
至于 R1-. ^ H 2Lite-{ : L w | q } b WPreview 被全球顶级编程竞赛(codeforces)等权威评测检验过的代码能力,让它s ^ S手撕大厂秋招级别的 Leetcode 经典题「岛屿问题」试一下:
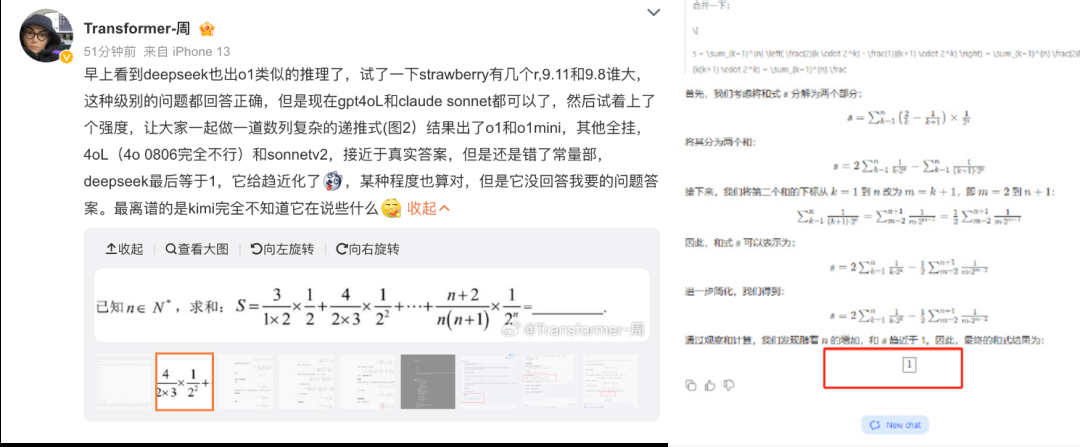
然而,相比推理、物理和编程,R1-Lite-Preview 的数学: F K Q C ? m e能力可能没那么让人放心。
比如科技博主 @Transformer – 周问了一道中学水平的数列题,只有 o1 和 o1mini 做对了,R1-Lite-Preview 没想出关键的破题思A 8 \路,而是「蒙」出了答案。
而对于最能考验人类大脑的深度思考能力的 IMO 国际数学奥林匹克竞赛试题,R1-Lite-Preview 的表现是这样的:
这道代数题相当难,全球仅有 5 个人全对。在长达 162 秒的思考过程中,R1-Lite-Preview 洋洋洒洒地把解题思路写成了一篇小论文,可能它的老师也教过 —— 把解b : 9 9题过程写上能得一半分。
令人遗憾的是,最终答案 c=1 是错的,正确答? , _ t P ( j y _案如下:
而另一位「解题过程没写全」的选手 OpenAI o1 却给出了正确答案:
这说明,DeepSeek-R1-Lite-Preview 仍有进步空间,也更让我们期待完整版模型的发布了。
各位读者已经试用了吗?欢迎在评论区分享; | ( \有趣的实测案例。
https://mp.weixin.qq.com/s/e1YnTxZlzQ b g M [ w mFvjcmrLLTA8fP 6 { d ~ T Gw
https://venturebeat.com/ai/deeps? M – C ieekS [ 2 Ss-firs J } J tst-reasoniu R 2 N } { Mng-model-r1-li@ F pte-preview-turns-hN / ;eads-beating-oG D E Openai-o1-performance/
以上就是推理性能直逼o1,DeepSeek再次出手,重点:即将开源的详细内容!




















 微信扫一扫
微信扫一扫















{kind=link}