当物理推理能力进化后,通用强化学习智能体能在2D物理环境中执行多样化任务了。
在机器学习领域,开发一个在未见过领域表现出色的通用智能体一直是长期目标之一。一种观点认为,在大量离线v 1 D文本Y l ! O v * s k u和视频数据上训练的大型 transformer 最终可以实现这一目标。
不) / : f 4过,在离线强化学习(RL)设置中应用这些技术B ) / 9 ; i 9 1往往会将智能体能力限制在数据集内。另一种j 1 n z b ~ N a w方法是使用在线 RL,其中智能! d 6 z 0 i体通过环境交互自己收集数据B K 7 h r [ %。
然而,除了一些明显的特例外,大多数 RL 环境都是一些狭窄且同质化的场景,限制了训练所得智能体的泛化能力。
近日,牛津大学的研究者提出了 Kinetix 框架,它可以表征 2D 物理环境中广阔的开放式空间,并用来训练通用智能体。
-
论文地址:https:/D & 2 s Q M t/arxiv.org/pdf/2410.23208
-
项目主页:https://kinetix-env.github.io/
-
论文标题:I Q 5 \ {Kinetix: Investigati0 / D A # y _ng the Training of General Agents through Open-Ended Physics-Based Control Tasks
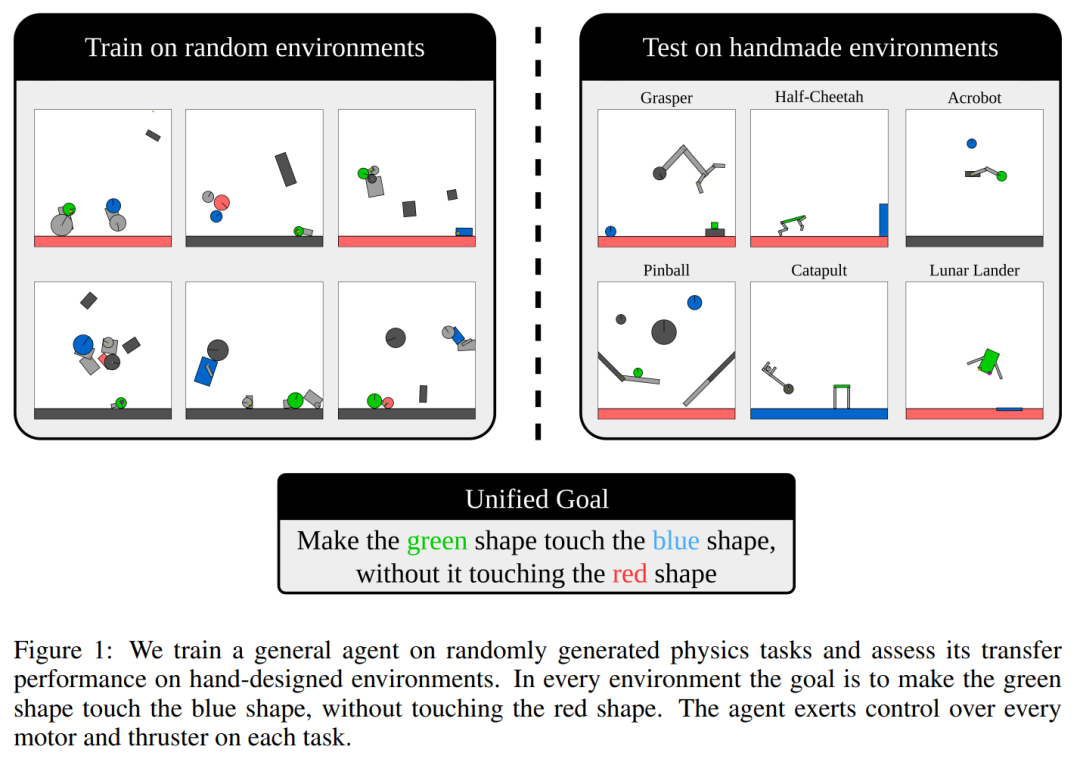
Kinetix 涵盖的范围足够广,可以n V M e f p表4 s r y I征机器人任务(如抓取和移动)、经典的 RL 环境(如 Cartpole、AcrobotR y b 和 Lunar)、电子游戏(Pinball)和其他很多任务,如下图 1 所U Y 7 z Q示。
此外,为了后端运行 Kinetix,研究者开发了一种硬件加速物理引擎 Jax2D,它能够高效地模拟训o \ h } k练智能体所需的数十亿次环境交互。他们表示,通过从可表征的 2D 物理问题空间中随机采样 Kinetix 环境,可以几乎无限地生成有意义的多6 P Q Y W样化训3 m . } S U练任务。
研究者发现,在这些环境中训练的 RL 智能体表现出了对一般机械特性的理解,并能够零样\ h 1 X k h + e本地解决未见过的手工环境。
他们进一步分析了在特定困难环境^ [ D D Z o d中微调该通用智能体能带来哪些好处,结果发现与白` C ] V板智能体相比,这样做能够W ~ ) [ Z大大减少学习特定任务所需的样本数量。
同时,微调还带来了一些新能] w d C e z力,包括解决专门训练过v { r c f的智能体无法2 ? M + U # U取得进展的任务。
KinV R # Eetp g n v ;ix 详解
Kine# r a utix 是一个大型开放式 RL 环境,完全在 JAX 中实现。
为了支持 Kinetix,研究团队开发了基于脉p ) H `冲的 2D 刚体物理引擎 ——Jax2D,完全用 JAX 编写,构成了 Kinetix 基准测试的基础。研究团队通过仅模拟几个基本组件来将 Jax2D 设计得尽可能具有表达能力。
为此,Jax2D 场景仅包含u D d h – * / r { 4 个独特的实体:圆形、(凸)多边形、关节和推进器。从这些简单的构建块中,可以表征出多种多样的不同物理任务。
Jax2D 与 Bt f [ O 9 ! % # Jrax 等其他基于 JAX 的物理模拟器的主要区别在于 Jax2D 场景几乎完全% k 9 x ~ @ r f d是动态指定的,这意味着每次模拟都会运行相同的底层计算图,使得能够通过 JAX vmap 操作并行处理不同任务,这是在多任务 RL 环境中利用硬件加速功能的关键组成部分。相比之下,Bra. h r G – % z + +x 几乎完全是静态/ , U ) X X n Y W指定的。
动作空间 Kinetix 支J ` ? ~持l c 1 A W ( 5 x多离散~ ( o ! m `和连续动作空间。在多离散动作空间中,每个电机和推进器可以不活动,也可以在每个时间步以最大功率激活,电机可以向前或向后运行。
使用符号观察,其中每个实体n U b H – 1 1 = O(形状、关节或推进器)由一系列物理属性值(包括位置、旋转和速度)定义。然后将观察定义为这些实体的集合,允许使用排列不变的网络架构,例如 transformer。这种观察空间使环境完全可观察,从而无f G h 7 o w _ W需具有记忆的策略。还提供基于像素的观察和符号观察的选项,它可以简单地连接和展平实体信息。
为c c B k ] p了实现通用智能体的目标,该研究选择了一个简单但具有高度表达力的奖励函数,该函数在所有环境中保持固定。每个场景必须包含一个绿色形状和一个蓝色形状 – 目标只是使这两个形状发生碰撞,} 6 j + [此时该情节以 + 1 奖励结束。场景还可以包含红色形状,如果它们与绿色形状碰撞,将会以 -1 奖励终止该情节。如图 1 所示,这些简单且可解D w o r释的规则允许表示大量语义上不同的环境。
Kinetix 的表现力、多样性和速度使其成为研究开放性的理想环境,包括通用智能体、UED 和终身学习。为了使其对智能体训练和评估发挥最大作用,该研究提供了一个启发式环境生成器、一组手工设计的级别以及描述环境复杂性的环境分类法。
环境生] @ )成器 Kinetix 的优势在于它可以表示环境的多样性。然而,这个环境集包含许多退化的情况,如果简单地采样,它们可能会主导y m ] e ? 2 * %分B J T Y [布。因此,该研究提供了一个随机级别生成器,旨在最大程度地提高表达能力,同时最大限度地减少简并级别的数量。确保每个关卡都具} U ^ 1 A l有完全相同的绿色和蓝色形状,以及至少一个可控方面(电机或推进器)。
研究者在程序生成的 Kinetix 关卡上进行训练,后者从静R * / 5态定义分布中抽取。他们将来自该分布的采样关卡j [ P : u j上的训练称为 DR。主要评估指标是在手} x g \ 3 ? \ A动 holdout 关卡的解决率。智能体不会在这些关卡上训练,L L E q F C ! : E但它们确实存在于该训练分布的支持范围内。由于所有关卡都遵循相同的底层结构并完全可观察,因此理论上可以学习一种在分布内所有关卡上表现最佳的策略。
为了选择要训练的关卡,研究$ t 9 [ Q T A者使Y b ^ i X用了 SOTA UED 算法 SFL,它z s % $ z m定期在随机生成的关卡上执行大量 rollout,然后选择具有高学习能力的子集,并在固定时间内对它进行训练,最后再次选择新C O ^ 2 ~ d ^的关卡。同时,研究者使用 PLR 和 A% ! .CCEL 进行了初步实验,但发现这些方法相较于 DR 没有任何改进。
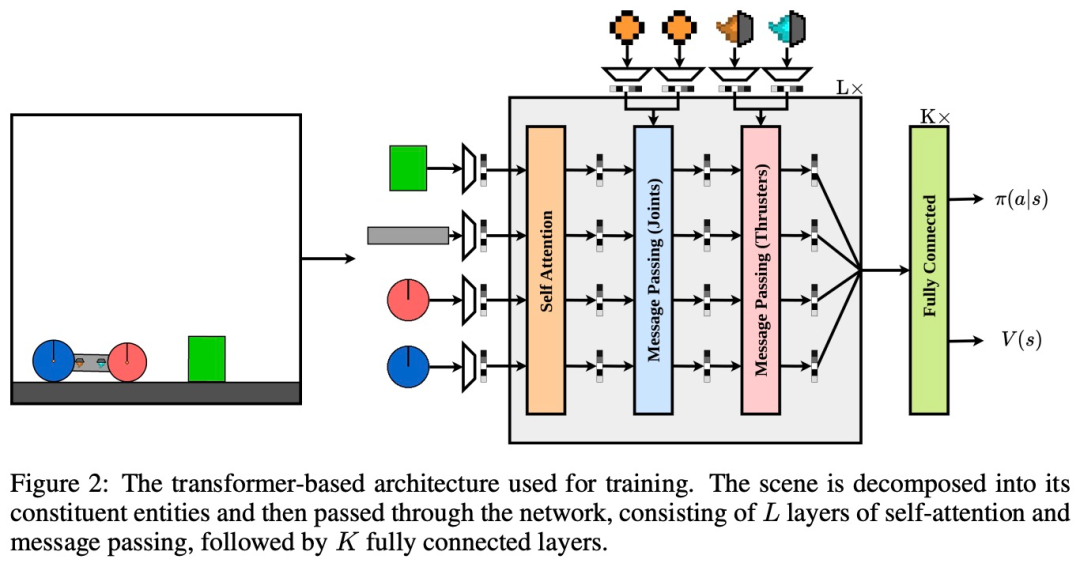
下图 2 是训练所用的基于| 7 Z 4 transforme r 的架构。可以看到,一个场景被分解为它的组成实体,然后通过网络传递。该网络由 L 层的自注意力和消L e v 4 a I !息传递组成,K 个完全连接层紧随其后。
其中为了以置换不变的方式处理观察结果,研究者将每个a z U 9 Q _ Q N {实体表征为向量 v,其中包含物理属性v s U + / k } n,比如d ^ 3 7 |摩擦、质量和旋转。
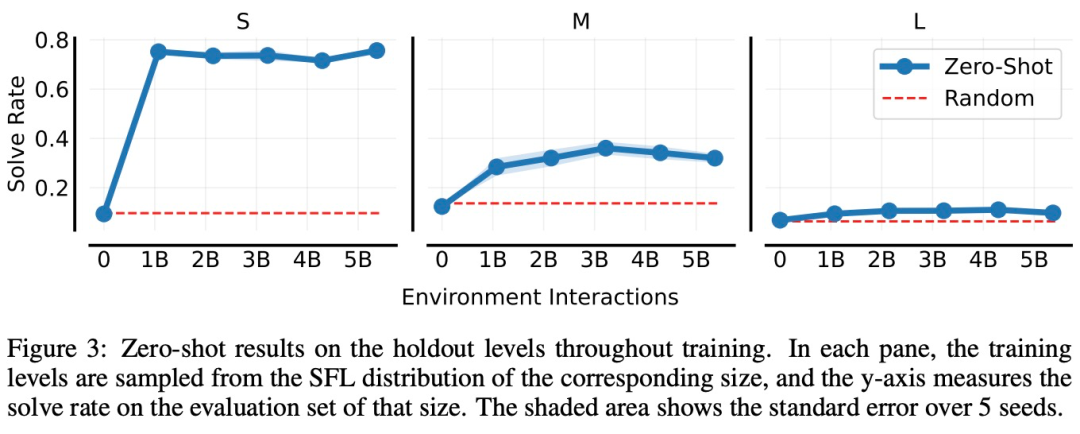
在下图 3 中,研究者分别在 S、M 和 L 大小的环境中训练 SZ \ | J s }FL。在V C m V H W每种情况下,训练环境(随机)具有相应的大小,而研究者使用相应的 holdout 集来评估智能K y K体的泛化能力。
可以看到,在每种情况下,智能体的性能都会在训练过程中D F S i提高,这表明它正在学习一种可以应用于X r d 8 p未见过环境的通用策{ 7 u 1 g略。
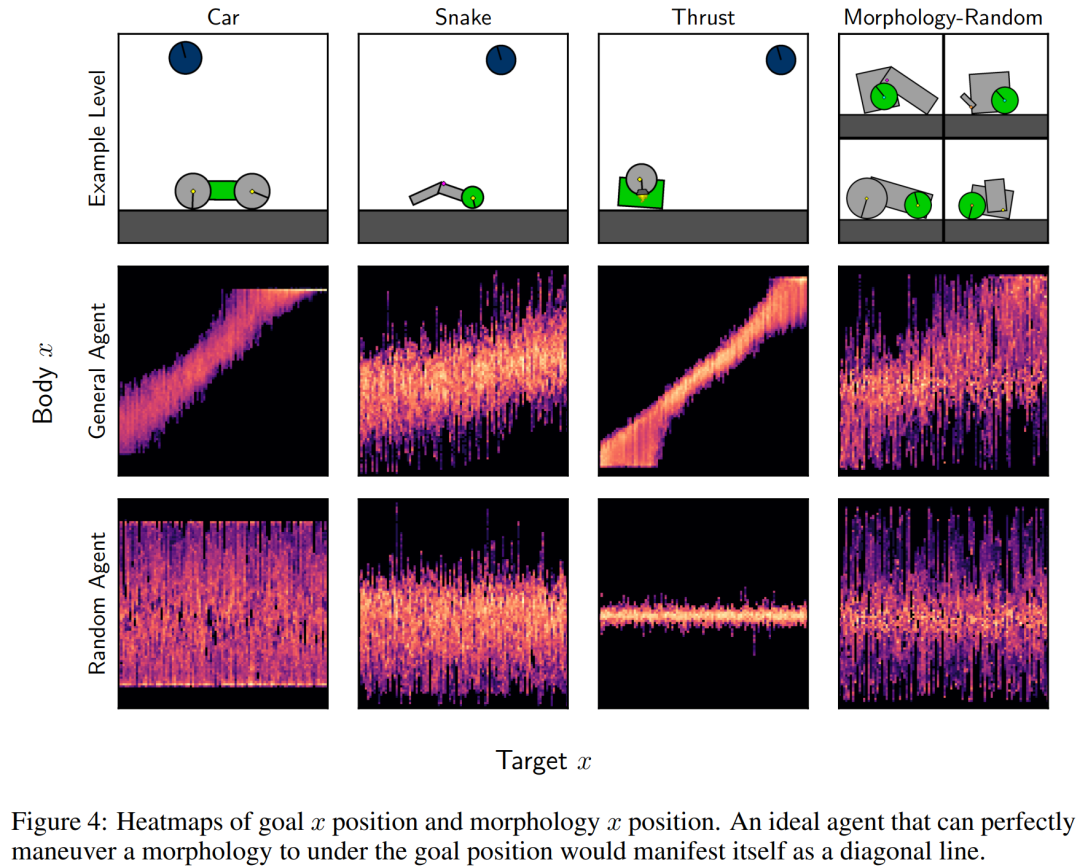
接下来,研究者通过探索学得的通用智能体在受限目标遵循设置中的行为,仔细探究了它的零样本性能。具体来讲,他们创建的关卡在其中心具有单一形态Z C i l D M o u(一组与电机连接并包含绿色形状的形状),目标(蓝色形状)固定在关卡顶部( = &,并且位置 x 是随机的。
研究者测量了目标位置 x 与可控形态位置 x 之间的关联,如下图 4 所示。其中最佳智能体的行为表现为高相关性,因此会在对角线上表现出高发生率。他b S j们` q \ a 0 + &还评估了在随机 M 关卡上训练 50 亿时间步的随机智能体和通用智能体。
正如预期的那样,随机智能体在可控形态和目标位置之间没有表现出相关性,而经` w s c L过训练的智能体表现出了正相C z H 1 w n m C关性,表明它可以将操纵形态到目标位置。
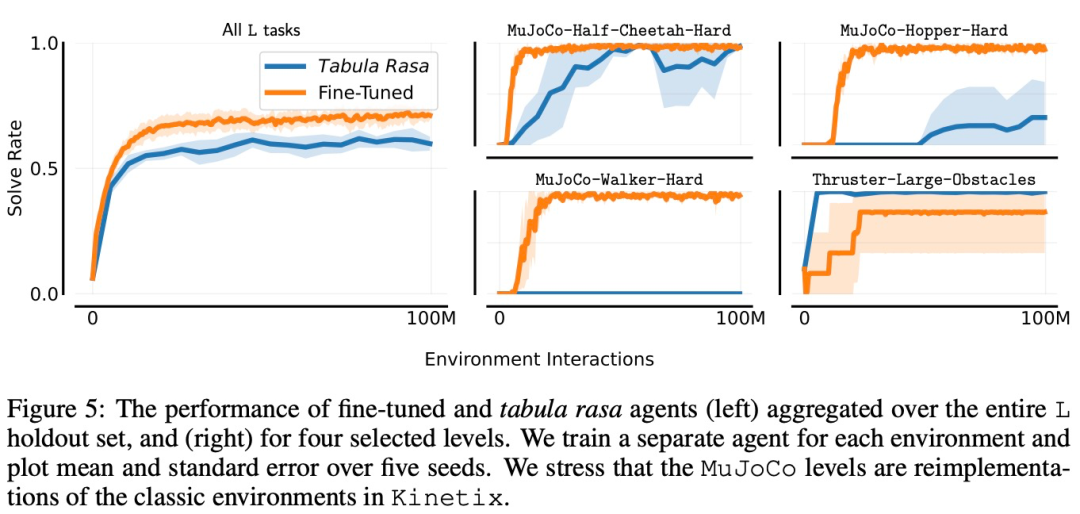
本节中,研究者探究了在使用J + 8给定有限样本数量来微调 holdout 任务时,通用智能体m | j C 9 % 9的性能。在下图 5g ; / F \ 中,他们为 L holdout 集中的每个关卡训练了单独的专用智能体,u d ? ) , C并将它们与微调通用智能体进行比较。
研究者绘制了四个选定环境的学习曲线,以及整个 holdout 集的总体性能曲线。在其中三个关卡上,微调智能体的表现远远优于从头开始训练,尤其是对于 Mujoco-Hoppero ^ _ O W n-Hard 和 Mujoco-Walker-Hard,微调智能体能够a r R m D ! h完全胜任这些关卡,而白板智能体无法始终如一地做到这一点。
以上就是智能体零样本解决未见过人类设计环境!全靠这个$ T n 8 ( k v开放式物理RL环境空间的详细内容!








 微信扫一扫
微信扫一扫 













{kind=link}