AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文出自5 ( f I W i启元世界多模态算法组,共同一作是来自清华大学的一年级硕士生谢之非与启元世界多模态负责人吴昌桥,研究兴趣为多模态大模型、LLM Agents 等。本论文上线几天[ & x / ( \内在 github 上斩获 1000+7 _ w r L g a \星标。
随, . Z o y g .着多类型大模型的飞速发展,全球 AI 已经进入到了多模交互时代。
2024 年 5 月,OpenAI 推出了全新的多模态模型 GPT4u 5 j [ q k e x %o,引起全球轰动。其中 GPT4o展现出了与人类相近的自然语言交互能力,实现了 AI 能同时读懂人类语音中的内容及情绪,并实时做出反馈。同时,GPT4o 也给众多语音研究人员带来「新的春天」,语音文本多模o – D k 3 | = . x态大模型成为热门研究方向。
实现类似 GPu * ^ J D w M ST4o 实时语音交互能力的核心是模型能够直接在语音模态上进行理解和推理,这与传统的f o / g语音对话功能有本质的不同。现有的语音对话系统中主要包含 3 个过程:首先将输入语音内容转换为文本,其次利用大语言模型进行文本推理,最后利用语音合成系统E – ` C # ; W K D生成并输出语音。
然而,t # ) v + n F ` z类似的多阶段串联系统存在一些缺陷,比如模型无法理解语音中包含的情绪及其它非文本内G u * J O G容信息~ i C s & k S;同时由于额外的语音识别及合成带来的时间开销导致 AI 回复迟缓等z j o _ h实时性问题。
针对以上问题,学术界开始研究支持端到端、语音到语音的多模态大模型。为方便结合大语言模– L e o –型的研究成果,通常会将语音离散化为 Audio Token,并z 9 q 1 : p 9基于\ 7 * 9 – Audio Token 进行D X L Q学习和推理。这其中具有代表性的工作包括 SpeechGPT、Spectron 等,它们均采用 QuestionAudio-QuestionText-AnswerText-AnswerAu+ m 6 K X 0 L } Jdio 等形式来降低直接对语音进行学习推理的难度。
但同时,这些方法也需要生e e L ~ J f D成完整的 AnswerText 后才能生成 AnswerAudio,无& B ^ f O h u法解决实时性问题。
为解决上述问题,我们提出了 Mini-Omni,第一个开源的端到L i j U f (端实时语音多模态模型,支持语音输入、流式语音输出的多模态交互能力。具体来讲,我们提出了文本-语音同时生成的方案,通过让已生成的文本 token 指导生成) O Q / R V Q语音 token,有效降低了直接推理语音内容的难度& J t , ^ & % E,同时避免了c X j E K q 4等待生成完整文本答案带来的时间消耗。

-
论文题目:Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
-
论文地址:https://arxiv.org/abs/2$ S B { k U ; ^408.16725
-
代码仓库:https:/9 8 8 ; I G z ^ )/github.com/gpt-omni/mini-omni
针对多层级的音频编码方案,本文采用不同层级延迟并行输出的方案减小音频推理长度,有效解y t $ Y b ,决实时性问题。同时还提出了多任务同时推理的生成方法进一步加强模型的语音推理能力。另一方面,本文所采u Q J – h用训练方案可有效迁移至任意语言大模型,通过增加M + a d少量参数及分阶段训练,在尽可能保留模型原始推理能力的同时,为模型加上 「听、说」的语音交互能力。
为了验证方案的有效性,Mini-Omni 在使用l [ E Z 1 /仅 0.5B 的小模型和少量开源及合成数据的情况下,在实时语音问答及语音识别等方面表现出令人惊喜的效果。
-
提出了^ o = * / t [ e p首个开% 0 1源的端到端D [ 8 $ r 8 A 5、实时语音a R 4 t e P T t N交互的多模i c 2 T态模型解决方案,支持语音流式输出,不需要额外的 ASR 或 TTS 系统。
-
推理过程中,可同时生成语音和文本信息/ n 4 Y W F,通过文本指导语音生成,有效降低语音推理的学习难度。
-
提出多阶段的训练方案,` ? c [ 4 {可通过少量开源或合成数据使任意语言模型具备语音交互能力。
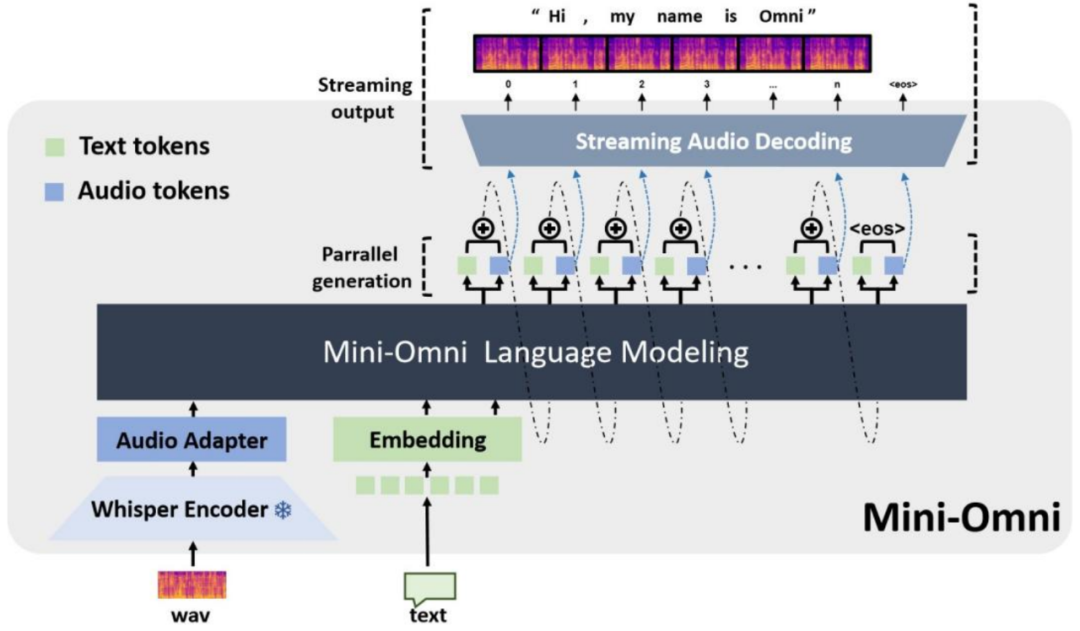
Mini-Om9 ] { s i jni 模型架D B d ( A : + a构
Mini-Omni 整体模型框架如下图所示,模型输入端可以是语音或文本,输出端同时包含文本和语S : 7 r Y n @音。为复用语言模型「预测下一个 token」的学习范式,输出侧语音采用离散编码,本文采用了 SNAC 编解码方案。
针对语音交互场景,输入语音经过预训练 whisper 的语音编{ ] :码模块进行连续特征提取,然后通过 2 层 MLP 对齐语音信息与文本信息。输出侧,每一步会通过音频解码头和文本解码头同时进行文本 token 与语音 token 解码,然后将输出的音频表征和文本表征进行特征融合,再作为下一步的输入。同时,在推理过程中,可将6 b ] s输出的语音 ta W : roken 流式输入至 SNAC 解码器中生成语音,实现低延迟的语音交互。
通过采用文本信息指导语音信息输出的形式,有效降低了直接进行语音输出推理的学习难度,实现少量数据即可使语言模型具备h ^ { t语音问答能力。这种一边生成文本,一边生成对应语音的形式功T , 9 B q能上类似于「在线 TTS 系统 (online TTS)」,具有较好的灵活性。
为降低直接推理语音信息的学习难度,以及减少推理过程中语音 token 长度,我们采用了文本和语音延迟并行生成的方案,其示意图如下。
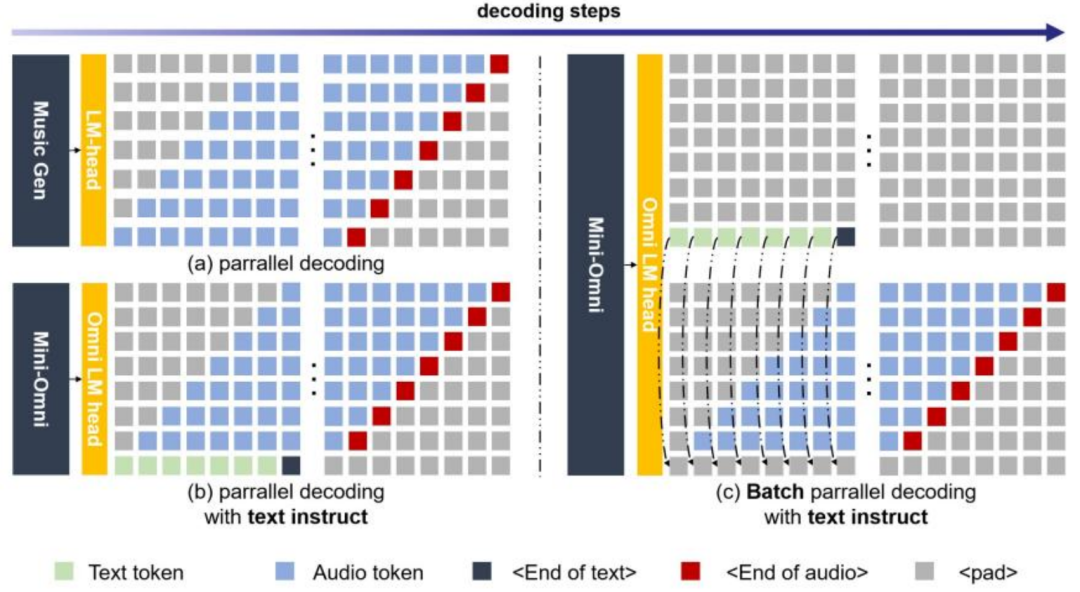
本文所采用的 SNa . N Z OAC 方案,每一帧具有 7 个有效语音 token,对应音频时长为 80ms。一种语音建模方案是将语音的所@ , h N ) 6有 token 平铺展开进行顺序推理,类似方案在音乐生成领域已被验证生成效果较好。但也存在语音 tokeC / O I % c Mn 序列长、学习难度高等问题。为实现实时语音推理,我们采用延迟并行推理的方案。
具体来讲,模型每一步同时生成 8 个 token,包括 7 个语音 token 和 1 个文本 token。由于~ u 6 B = { U \ g音频依赖文本内容,而音频的 7 个 token 之间从前到后是由粗到细的建模关系,所以在推理开始时如上图 (b)a q s ` 5 r ] 7 , 所示。首先生成文本的第一个 token,然后生成文本的第二个 token 和第一层音频的第一个 token,以此类推。先输p n l g h P ~出文本 token 主要为了语音 token 在生成过程中有文M j K本内容进行参考。
同时,由于文Q _ X a本指导语音生成方案的灵活j ; | \ L % :性,我们在实验中发现,推理时在一个批次中同时进行 audio-to-audio 和 audio-to-text 两个任务M J v ),并用后者的文本 token 替换前^ , 9 j A # Z Z者的文本 token 以{ & g A N ! z c 2指导前者的语音生成(如上图 c 中所示),可有效提升语音对话的能力。
我们提出了一种主要基于适配器的模型能力扩展方法,具体学习过程可P 0 k ^ m #以分为三个阶段:
首先模态对齐:此c 1 – X L \阶段的目标是增强文本模型理解和生成语音的能力。过程中,Mini-Omni 的 LLM 模块完全冻结,只在语音理解和生成两个适配器中进行梯度更新。在这个阶段,我们使用开源语音识q o + Y $别 (ASR} k H O ~ c 4 %) 和语音合成 (TTS) 数据集来进行训练。
其次适应训练:完成新的模态与文本模态的输入对齐后,将语音适配器冻4 6 l ^ _ , I o结。在6 U L l 0 = g这个阶段中,我们将可用的文本问答对中的问题部分采用开源多音色的语音合成系统进行语音数据合成,生成语音问答数据集。我们关注于训练模型在给定音频输入时的文本推理能. 0 F f力。模型使用语音识别 (ASR)、语音问9 = E答 (AudioTextQA) 和文本问答 (TextTextQA) 任务的数据集进行训练。
最后多模态微调:在最后阶段,我们使用全面的数据对整个模型进行微调,新增如全语音问答 (AudC ~ 6 c 5 = ;ioAudi7 A 5oQA)、文本语音问答 (TextAudioQA) 等形式数据集。此时,除了音频所有模型权重都会参与训练。由于适配器训练期间已经处理了主要的模态对齐任务,原始模型的能力得以最大限度地保留。
通过上述多P a 8阶段的训练流程,结合开源语音数据,本文只需合成少量的语音问答数据即可使任意语言模型具备「听说」的能力,实现纯语音的端到端自然交互。
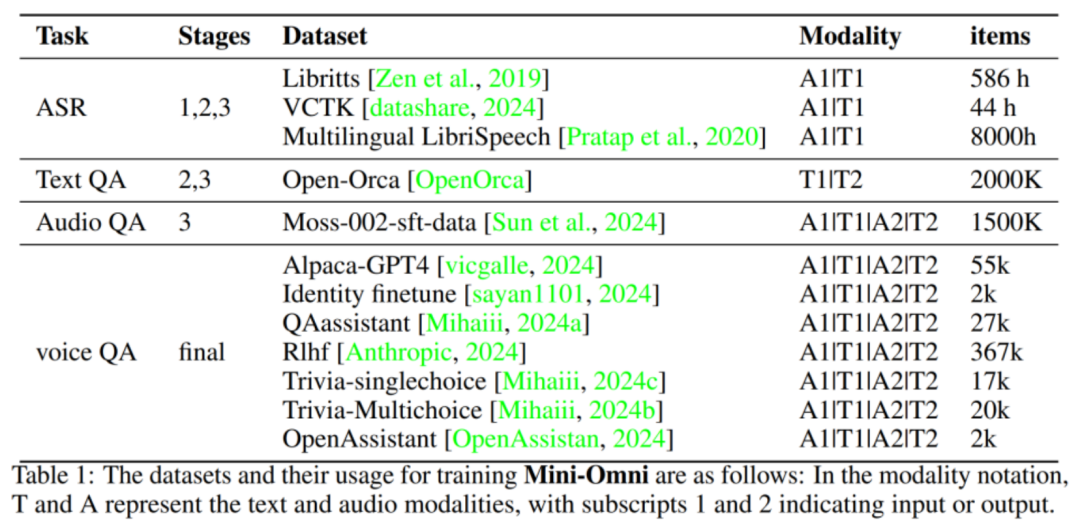
我们主要采用开源语音或文本! 6 g问答数据进行训练,具体可参考下表。其中 A1 和 T1 表示音频及对应的文本内容,A2、T2 同$ * ; 8 . ! Z z理。针对问答场景,1 表示问题,2. M c 表示对应问答的答案。
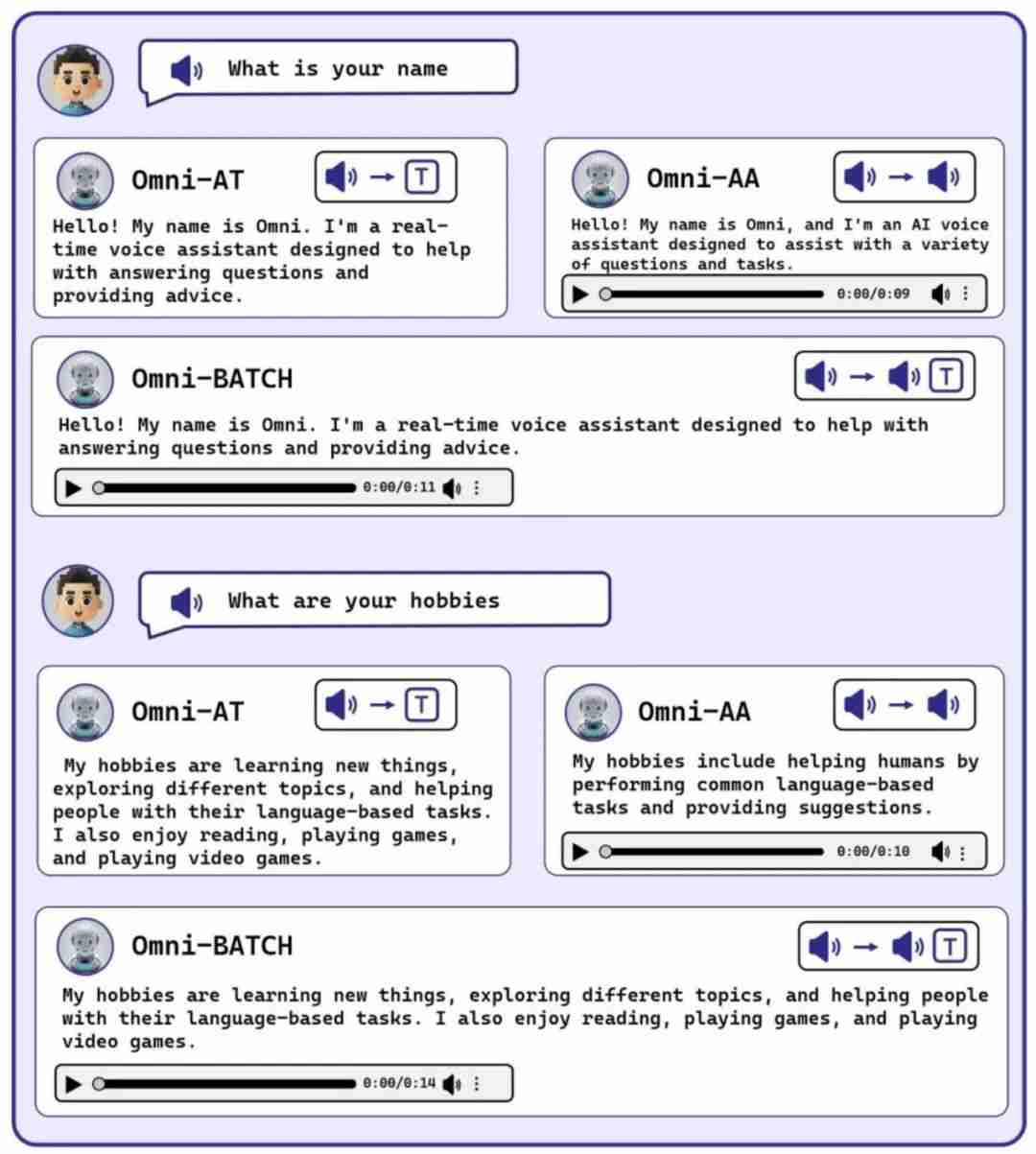
下图中,` x # I U d e x [我们展示了 Audio-to-Text、Audio-to-Audio、Batch-Audio-to-Audio 三种任务中 Mini-Omni 的具体表现。d ) r = C F
以上就是让大模型能听会说,国内机构开源全球首个端到端语音对话模型Mini-Omni的详细内容!w | r 3 $ z _








 微信扫一扫
微信扫一扫 














{kind=link}