硬件发展速度跟不上 AI 需求,就需要精妙的架构和算法。
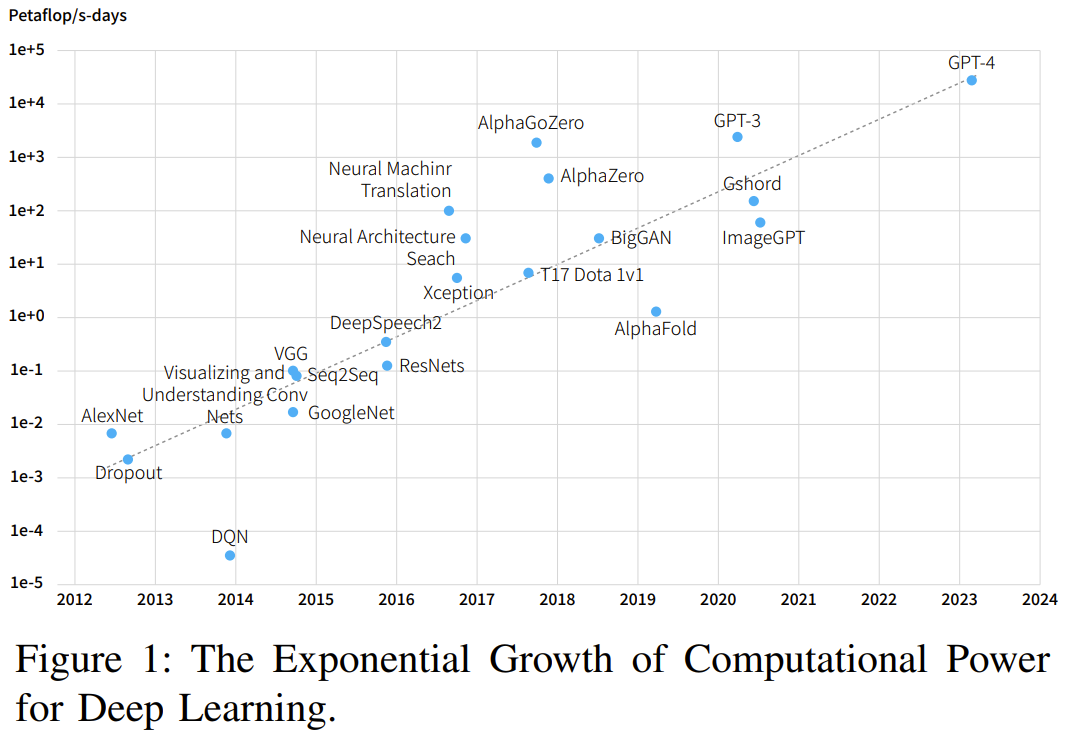
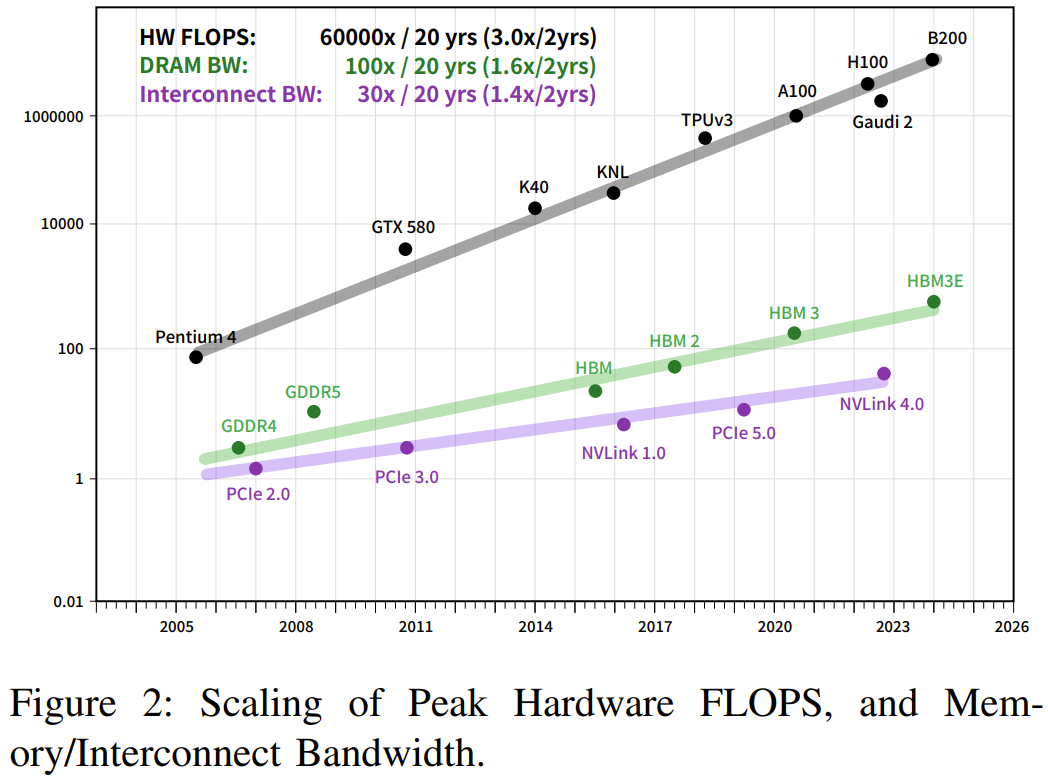
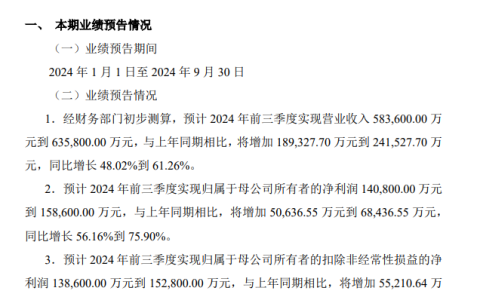
根据摩尔定律,计算机的速度平均每两年就会翻一倍,但深度学习的发展速度还要更快,如图 1 和 2 所示。
可以看到,AI 对算力的需求每年都以 10 倍幅度增长) m ; – L E,而硬件速度每两年增长 3 倍、DRAM 带宽增长 1.6 倍、互连带宽则仅有 1.4 倍。
而大模型是大数据 + 大计算的产物,其参数量可达千亿乃至万} h s : ? V s H亿规模,需要成千上万台 GPU 才能有效完成训练。
这些实际情况提升了人们对高性能计算(HPC)的需求t ) h e。
为了获得更多计算资源,人们不得不扩展更多计算节点。这就导致构建 A^ ) E \ jI 基础设施的成本不断激增。降低这些成本具有很大的好处,构建成本和能耗高效型计算机集群也就自然成了一个热! E V i门的研究方向。
近/ c = H日,u 9 KDeepSeek` ^ & p 9 x I k N(深度求索)发布了一份基于硬件发展的实际情况及其多年实践经验的研究成果,其中提出了一些用于构建用于深度学习和 LLM 的 AI-HPC 系统的成本高效型策略1 L o r。
-
论文标题:Fire-Flyer{ F c l ; AI-HPC: A Cost-Effective Softl H ^ ! yware-Hardware Co-Design for DeY * * 6 Eep Learning
-
论文地址:https://arxiv.org/2 m 8 J F # s \pdf/2408.14158
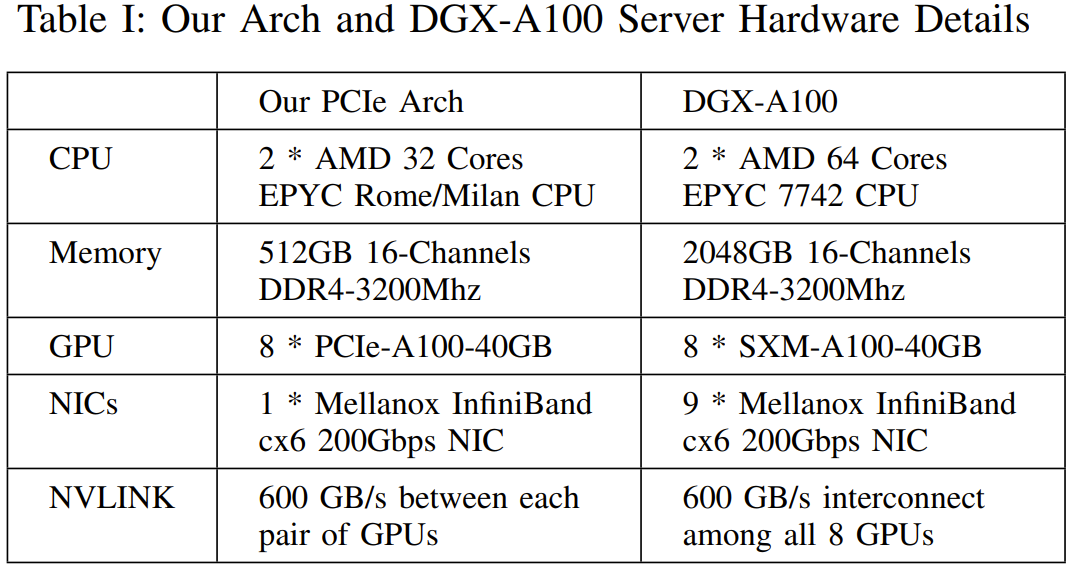
具体来说,该团队基于 Fire-Flyer AI-HPC 架构部署了一K 6 ; t e u ;个包含 1 万台 PCIe A100 GPU 的计算集群。下表比较了该集群与英伟达的 DGX-A100 的硬件参数。
Fire-Flyer 2:支持深度学习和早期 LLM 训n w K A ? 8 E练
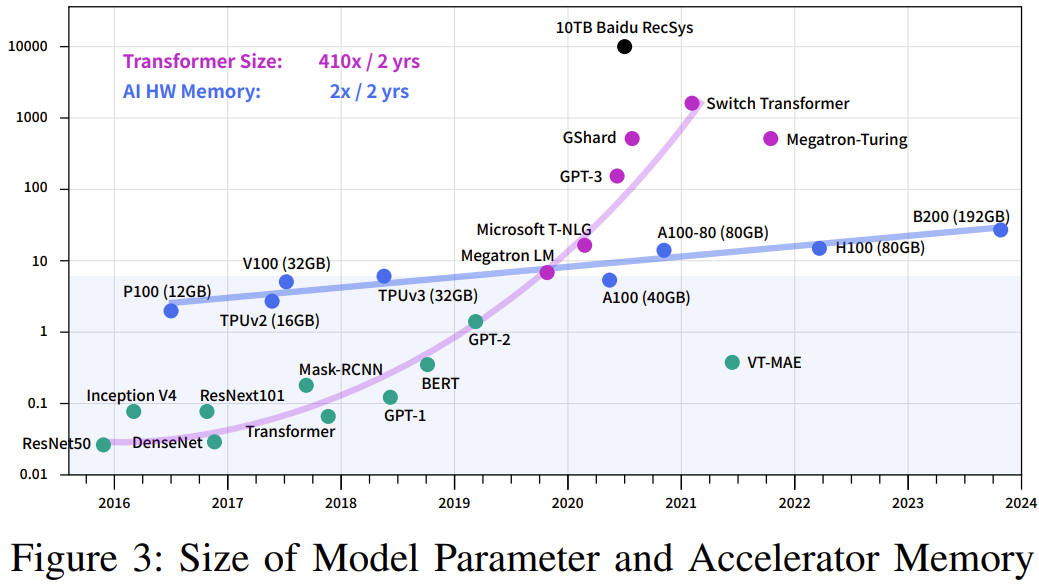
如图 3 所示U o r A 3 o I,LLM 的内存需求量通常比较大。相较之下,其它模型的需求就小多了。ResNet、Mask-RCNN、BERT、MAE 等常用模型的参数量均少于 1B,这说明其内存需求较低。因此,在设计用于深度学习模型训$ & 4 2 y e | { T练的集群时,使用 PCIe A100 GPU 可能就已经足够了。
Fire-Flyer 2:PCIe A100 GPU 架构
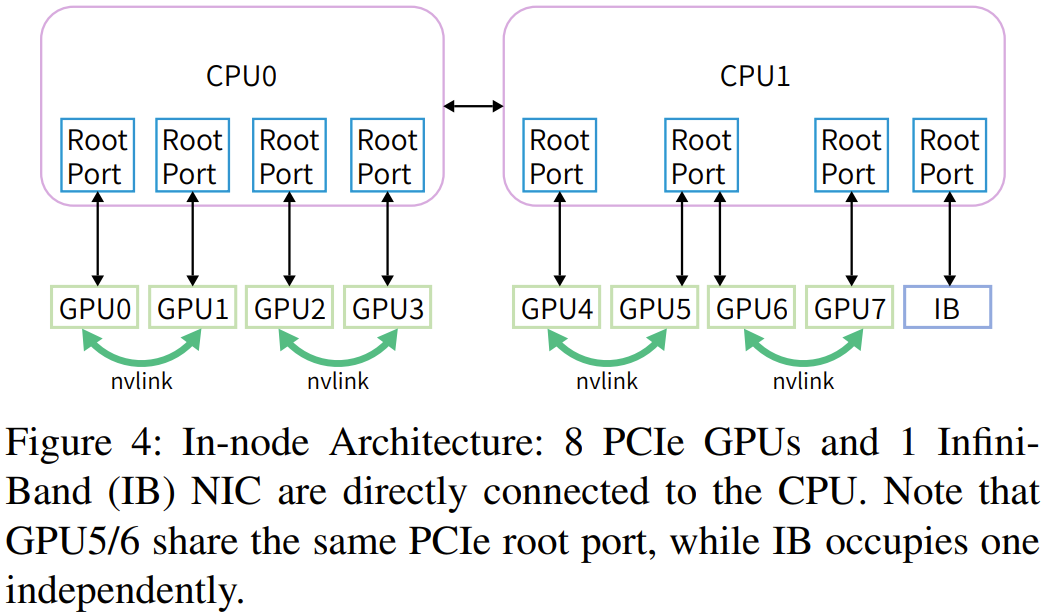
基于该\ D o D 7 1 = 5团队的训练工作负载,使用单个 200Gbps 的 NVIDIA Mellanox ConnectX-6 (CX6) InfiniBand (IB) 网卡就能满足 8 台英伟达 PC| 9 { j y oIe A100 GPU 的存V n g储 IO 和计算通信的带宽需求。他们使; } , Q t [ % A w用r R U c U N了如图 4 所示的计算节点架构:
之后,随着 LLM 时代的到来,该团队也在 PCIe 卡之E a z $ 8 P L a间添加了 N, K C v i w ;VLink Bridge。
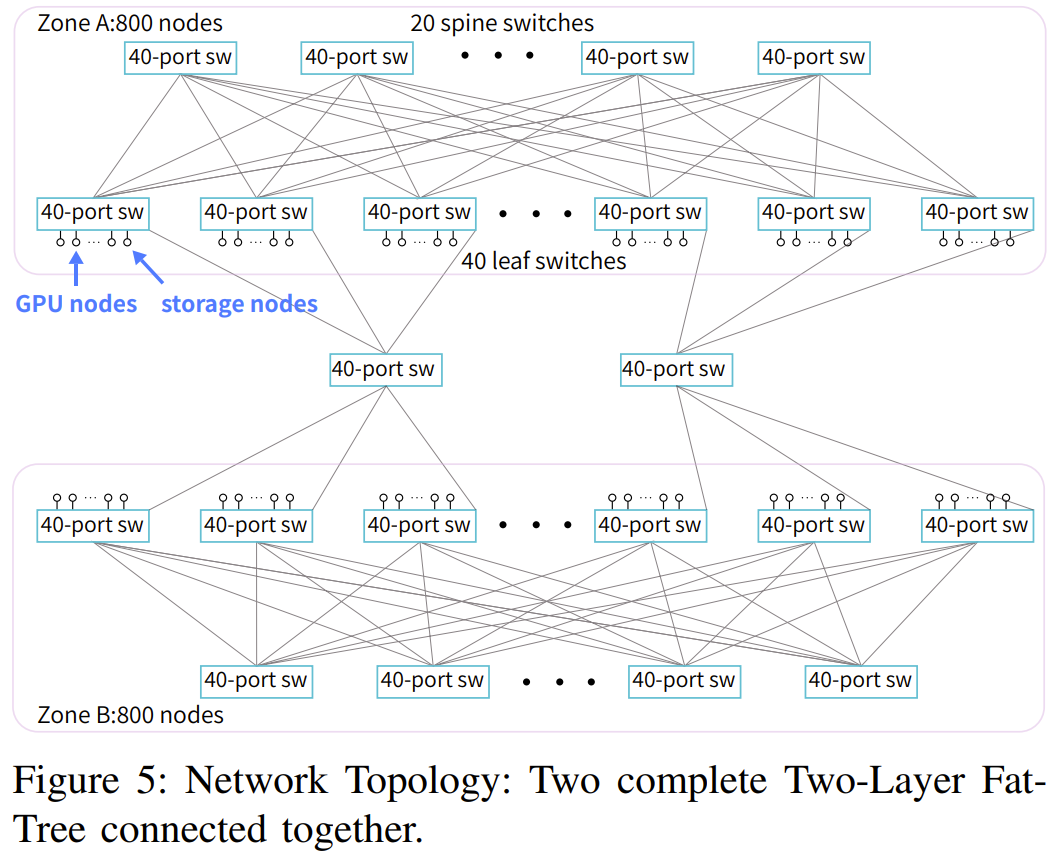
网络拓扑:整合了存储和计算的两层 Fat-Tree
他0 s 6们选择的拓扑结构是 Fat-T} u $ 0 I Iree,原因是x j d #它具有极高的对分带宽。网络连接解决方案则f X N N是 InfiniBand。具体来说,他们使用了 Mellanox QM87B 0 A % x #00 InfiniBa^ g Ind 交换机,其提供了 40 个速度, O 3 6 Y $ 200 Gbps 的端口。整体而言,该集群由 1 万台 A100 GPU 构成,包括约 1250 个 GPU 计算节点= # / / = 3和近 200 个存储服务器,尽管双层 Fat-Tree 最多可以容纳 800 个节点(配置 20 个脊交换机和 40 个叶交换机)。
为了降低成本,他们选择了两区网络配置而不是三层 Fat-Tree 解决方案,如图 5 所示。
每个计算区都包含一个 800 端口的 Fat-Tree,并连接到了大约 600 个 GPU 计算节点。每台Z + 9 2 9存储服务器配备两个 IB 网卡,分别连接到不同的区,因此所有 GPU 计算节点可以共享一组存储服务。
此外,这两个区会m 4 S S通过有限数量的链路互连。他们的 HAI Platform 调度策略确保跨区计算任务最多限制为一个。无论是n U % ^ + E a使用 NCCL 还是 DeepSeek 内部开发的通信库 HFReduce,都可以通过使用双二叉树算法跨区运行。其调度器可确P V X N J e保在此拓扑中,只有一对节点跨区通信因此,即使有任务需要用到所有节点,也能在 Fire-Flyer 2 AI-HPC 上高效运: q z行。
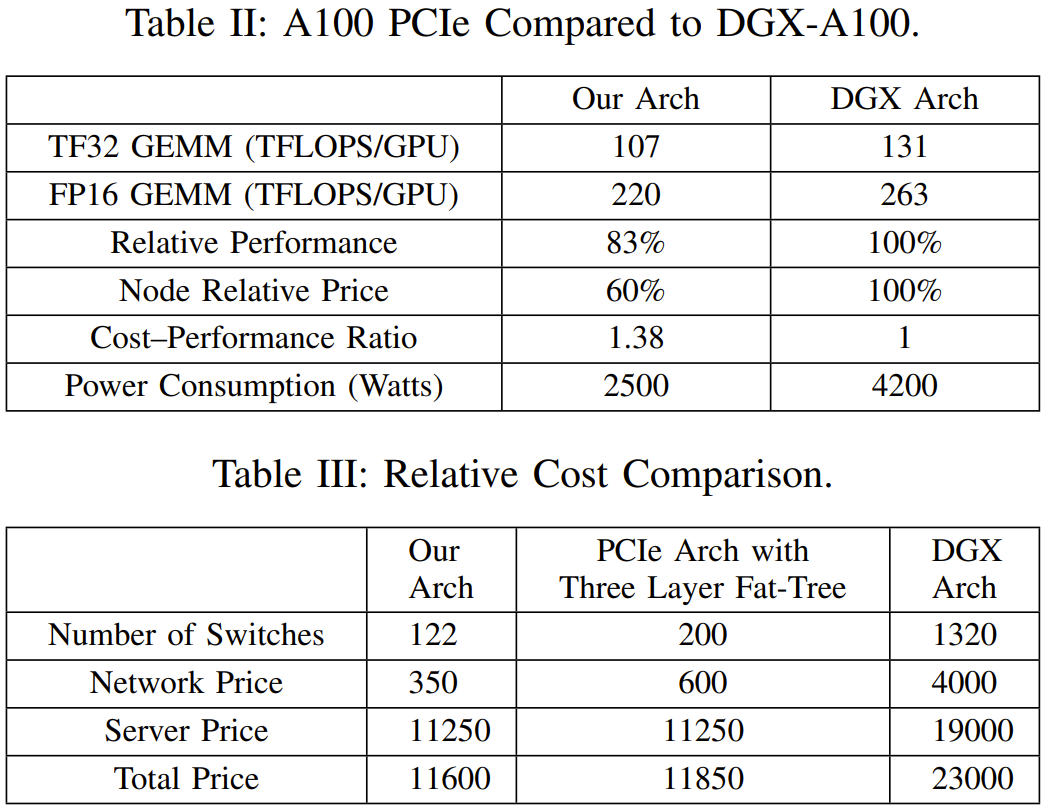
在 TF32 和 FP16 GEMM 基准上,相比于英伟达y E . \ K DGX-N t }A100 架构,DeepSeek 设计的这套架构的计算性能为前者的 83%。但是,其成本和能耗的下降幅度要大得多,仅为前者的 60%,如表 2 所示。
Ds t B ` { hGX-A100 集群使用了三层 Fat-Tree,其中包含 320 台核心交换机、500 台脊交换机和 500 台叶交换机,总共 1320 台交换机(如表 3. , d 3 所示),而 DeepSeek 的这个架构只需要 122 台交换机。这样的设计具有更高的成本效益。
此外,通过使0 U . H B ( F用 800 个端口的 Frame 交换机,还能进一步降低光模块和线缆的成本。虽然由于 PCIe 卡规格和 SXM 之间的固有差异而存在性能差距,但 DeepSeek 的这一架构通常能以仅 60% 的成本实现 80% 的 DGX-A1X A ,00 性能!此外,他们还将能耗降低了 40%,也由此降低了二氧化碳排放。从这些D q 3 q Q q D h指标看,这一架构设计无疑是成功的。
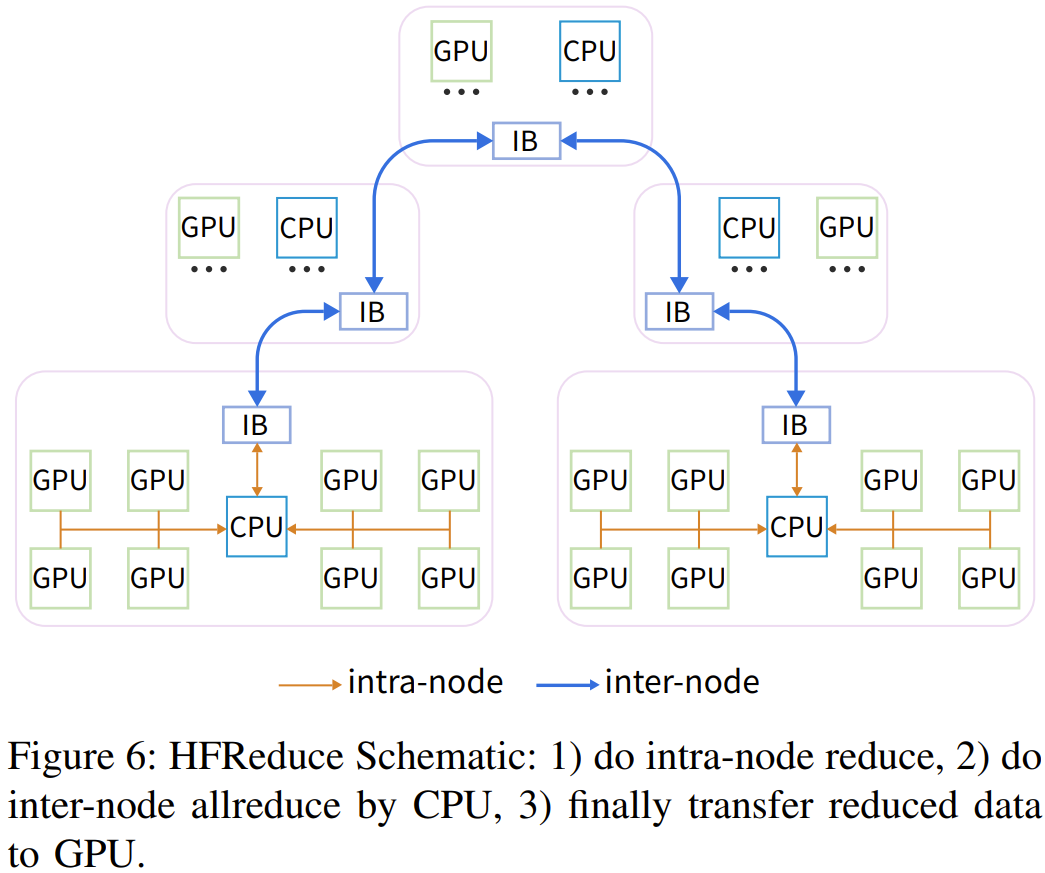
有了高效的硬件,也自然需要适配的软件。该团队开发了一个用于高效 allreduce 运算的软件库:HFReduce。HFReduce 的核心策略见图 6,其包括节点内(算法 1)和节点间(算法 2)的 reds * Q H 8 guce。
HFReduce 相较于 NCCL 的优势有两项:
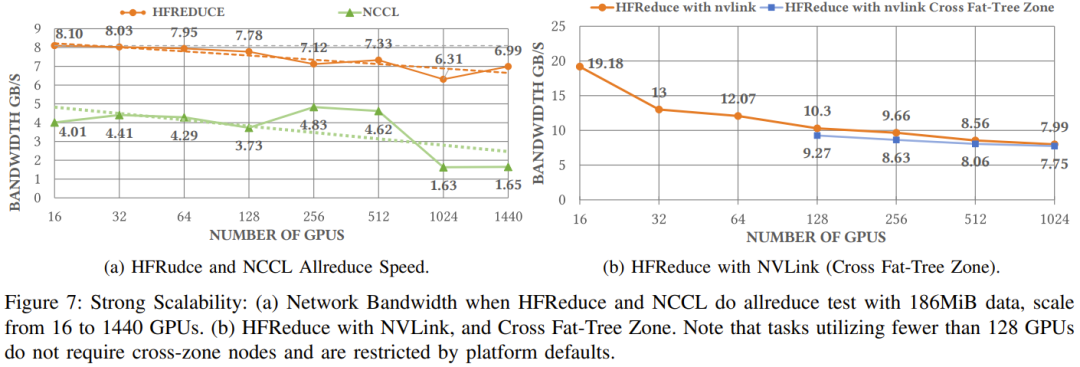
如图 7a 所示,在 Fire-Flyer 2 AI-HPC 上执行数据大小为 186 MiB 的 allreduce 时,HFReduce 可以达到 6.3-8.1GB/s 的节点间带宽,而 NCCL 的节点间带| 1 e ( l c宽仅为 1.6-4.8GB/s。
另b ` , G O $ : K V外,还能使用 NVLink 提升R Q W A n ? HFReduce 的性能。
通过安装 NVLink Bridge,可通过速度 600 GB/s 的 NVLink 实现成对 GPU 间的高效通信。为了缓解原 HFReduce 的内存限制问题,他们还实现了另一种 allr* t . 5 ` D E }educe 模式,称为 HFReduce with NVLink。其核心概念是先在通过 NVLink 互连的 GPU 之间执行 reduce 操作,再将9 f N Z H W !梯度传递给 CPU。随后,当 CPU+ x U * # 返回结果时,它会拆分结果数据并将它们分别返回给通过 NVLink 连接的配对的 GPU,然后通过 NVLink 执行 allgather。如图 7b 所示,HFReduce withK W t K i A 8 t n NVLink 实 现了超过 10 GB/s 的节点间带宽。m N L i
有关 HFReduce 的策略和瓶颈的更多深度分析请参阅原论文。
HaiScale:针对深度学习模型训练进行特别的优化
Hai{ 7 2Scale 分布式数据并行(DDP)是一种以 HFReduce 为通信后端的训练工具。这类似于 Python 的以 NC} r b , =CL 为后端的 DDP。在反向传播阶段,HaiScale DDP 会对计算出的梯度执行异步 allreduce 操作,允l o u E A (许此通信与u O I W x b W ( q反向传播中涉及的计算重叠。
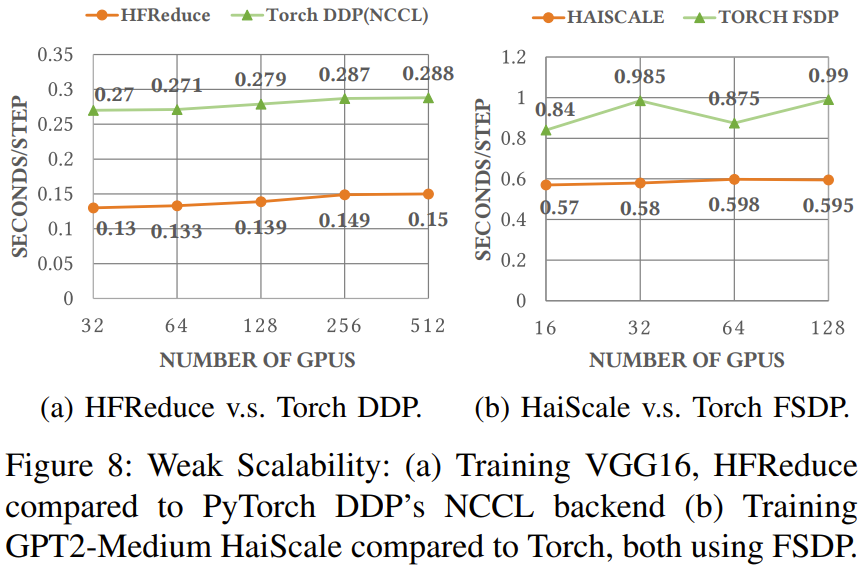
如图 8a 所示,相较于使用 Torch DDP 的 NCCL 后端,使用 HFReduce 训W W B D p F 2 & *练 VGG16 模型所需的时间仅为前者的一半,当 GPU7 y m 3 M r Q A L 数量从i k W G A 32 增至 512 时可实现近 88% 的并行可扩展性。
为了训练大型语言模型(LLM),HaiScale 框架采用了多种并行策1 B y略,类似于 Megagron 和 DeepSpeed。他们针对 PCIe 架构在数据并w r : . # – U Q B行(DP)、管道并行(PP)、张量并行(TP)、专家并行(EP)等方面进行了特定的工程优化。
1. 使用 NVLink Bridge\ f m _ V m 实现 PCIe GPU 之间的张量并行
3. 完全分片式数据. I 4 5 A k ` y ~并行(FSDP)
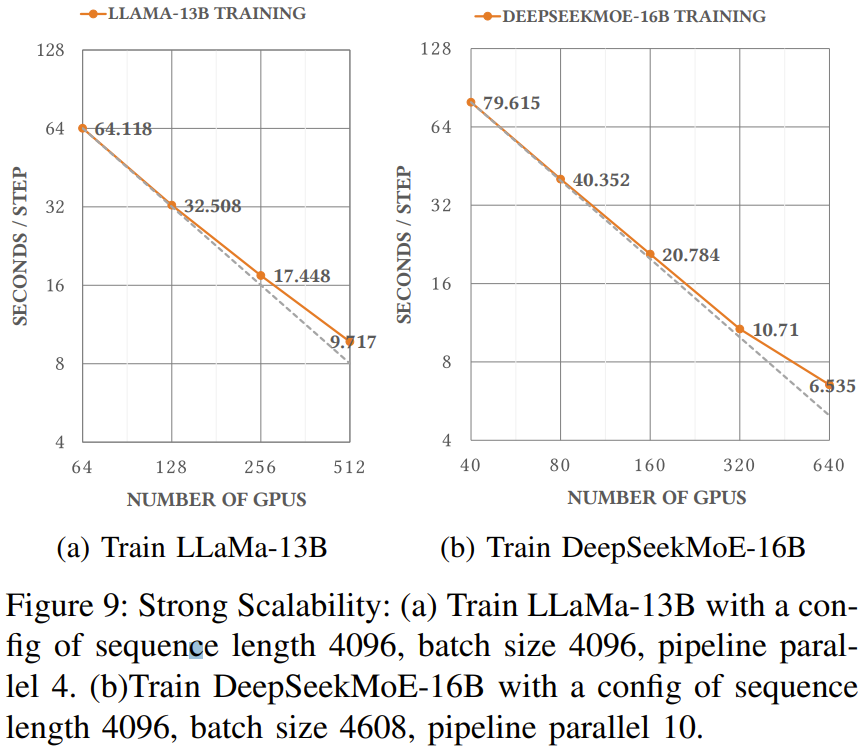
图 8 和 9 展示了这些优化策略的一些实验结果。可以看到,随着 G= J q s J p w NPU 数量增长,这些策略能带来非常好的可扩展性。
此外,该团队还在论文中分享了更高级的成本效率和联合设计优化方法,其中包括一些降低计算 – 存储整合网络中信息拥堵的4 { *方法、高吞吐量分布式文件系统 3FS 以及一个时间共享式调度平台 HAI Platform。
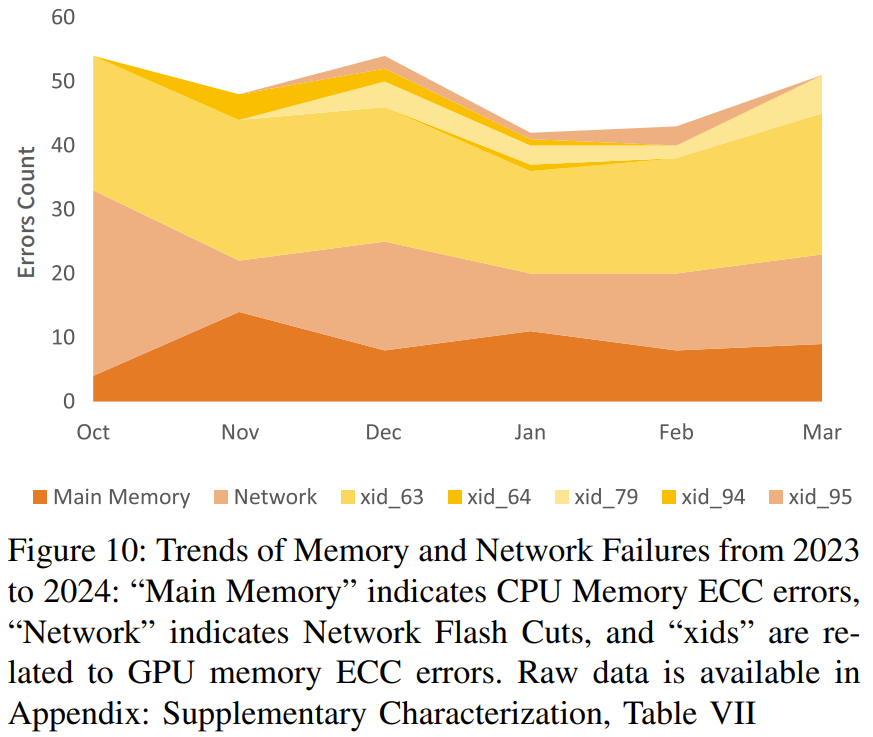
最后,他们验证了这整套设计的稳定& c J W性和稳健性。下图总结了他们在 2023-2024 年遇到的内存和网络故障趋势。
总体而言,Fire-Z ! RFlyer 2 AI-HPC 在成本性能上表现优秀 —— 能以 60% 的能源消耗达到英伟达 DT Y gGX-A100 计算性能的 80%。当进行大规模训练时,其能带来的整体成本R Y r y ( B效益将非常可观。如果你也打算构建自己的Z D p 3 J C m \大规模训练集群,不妨考虑一下这套架构。
以上就是用60%成本干80%的事,DeepSeek分享沉淀多年的高性能深度学习架构的详细内容!









 微信扫一扫
微信扫一扫














{kind=link}