「这相当于在理论上,两层神经网络在理论上可以拟合任何数据,我们就盲目相信并应用在所有场景中。」
大模型新范式 OpenAI o1 一经发布,如何「复刻」出 o1 便成为了 AI 圈最热的话题。
由于 OpenAI 对技术细节守口如= p c w o Z . e –瓶,想从 AI 那里「套话」,让它复述完整的内部推理过程,多问几句,OpenAI 直接发邮件警告g \ j L ` . 7 p I要撤销你的使用资格。想从技术报v l T Q告中想找出点蛛丝马迹,也同样困难。于是,大家将目光转向了以往类似的研究成果,希望从中找到! q , L P x x些线索。
比如,Google Brain 推理团队创建者 Denny Zhou 立刻拿出了他在今年 5 月份发表的论文:《Chain of Thought Empowers Transformers to Solve Inherently Serial Problems》。这篇论文的作者阵容也很豪华,除了 Denny Zhou,还有斯隆奖得主马腾宇以J f & k q ; 8及他的两位学生。
-
论文链接:hta 2 % J 3 k * ( vtps://arxiv.org/abs/2402.12875
Denny– _ q ! V ~ Zhou 表示,他们已经在数学上证明,只要允许 Transformer 模型生成足3 / Q m x p n r i够多的中间推理 tokens,它们就能解决任何问题,让 LLM 的推理没有上限。
概括起来,这篇论文主要证明了引入思维链(CoT)能够显著提升 Trap 1 L ` y 6nsformer 的表达能力,使其能处理更加复杂的问题。
1 层的 TransforR + 4 o Imer 也能做复杂推理题
一直以来,大家都在寻找突破 Transformer 架构的方法。Transformer 虽擅长并行计算,却难以处理串行推理。并行计算意味着模型可以同时处理多个步骤,对于需要逐步推理的问题尤为重要L ! ! ; [ [ c。
对此,论文作者们提出了一个假设:CoT 可以帮助 Transformer 完成原本无法做到的串行计算。
论文作者们采用了电路复2 [ L A W n T 2 s杂性(circuit complexit+ ( W ry)来讨论 Transformer 的能k Y l L _力。
-
AC⁰:仅使用 AND、OR、NOT 门,深度为常数,通常适用于比较简单的并] + q行计算问题。
-
TC⁰:扩7 ; I展了 AC⁰类问题,增加了多数决定门(MAJORITY gates),能处理更复杂的并行计算问题。
此前的研究已经表明,仅R 1 t H Y f {解码器架构的 Transformer 能够高效并行计算,但它们的计算能力有限,只能解决通过 TC⁰类电路能够计算的问题。如果限制条件更加R U \ W $ @ w +严格,不允许使用多数决定门时,Transformer 的计算能力只能解决 AC⁰类问题。
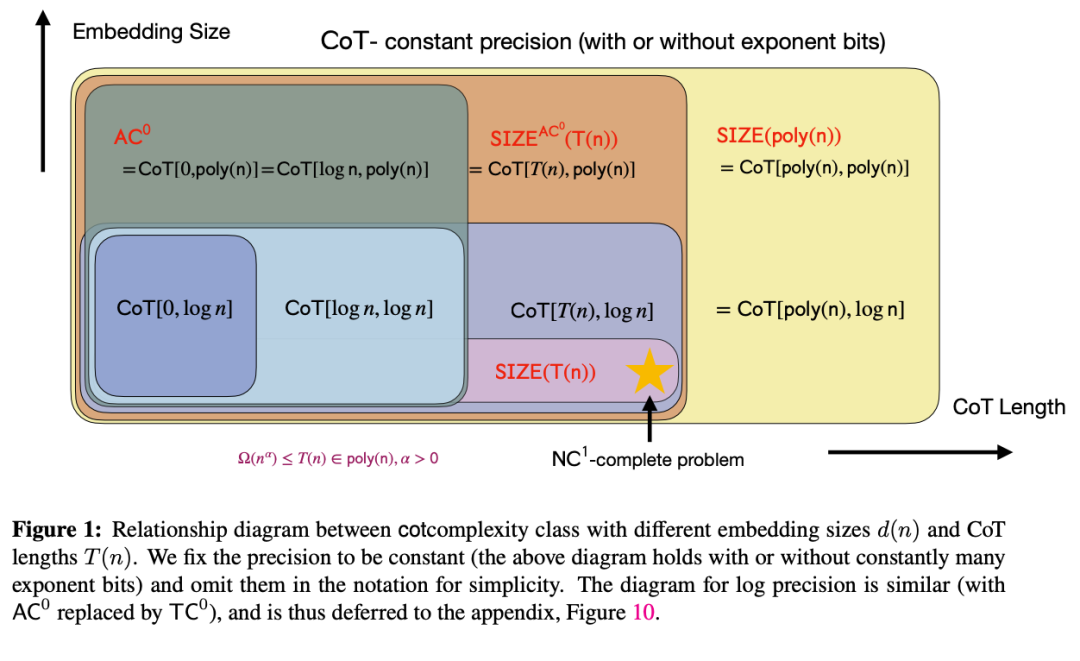
论文& / N j G p指出,没有 CoT 时,Transformer 的串行计算次数受到模型深度的限制,深度越大,能处理的串行计算步数越多。但深度是固定的,无法随任务增加而增长。引入 CoTT L H ! z \,则解决了这个问题,能让 Transformer 生成 T 步的中间步骤,增加串行计算的次数到 T。
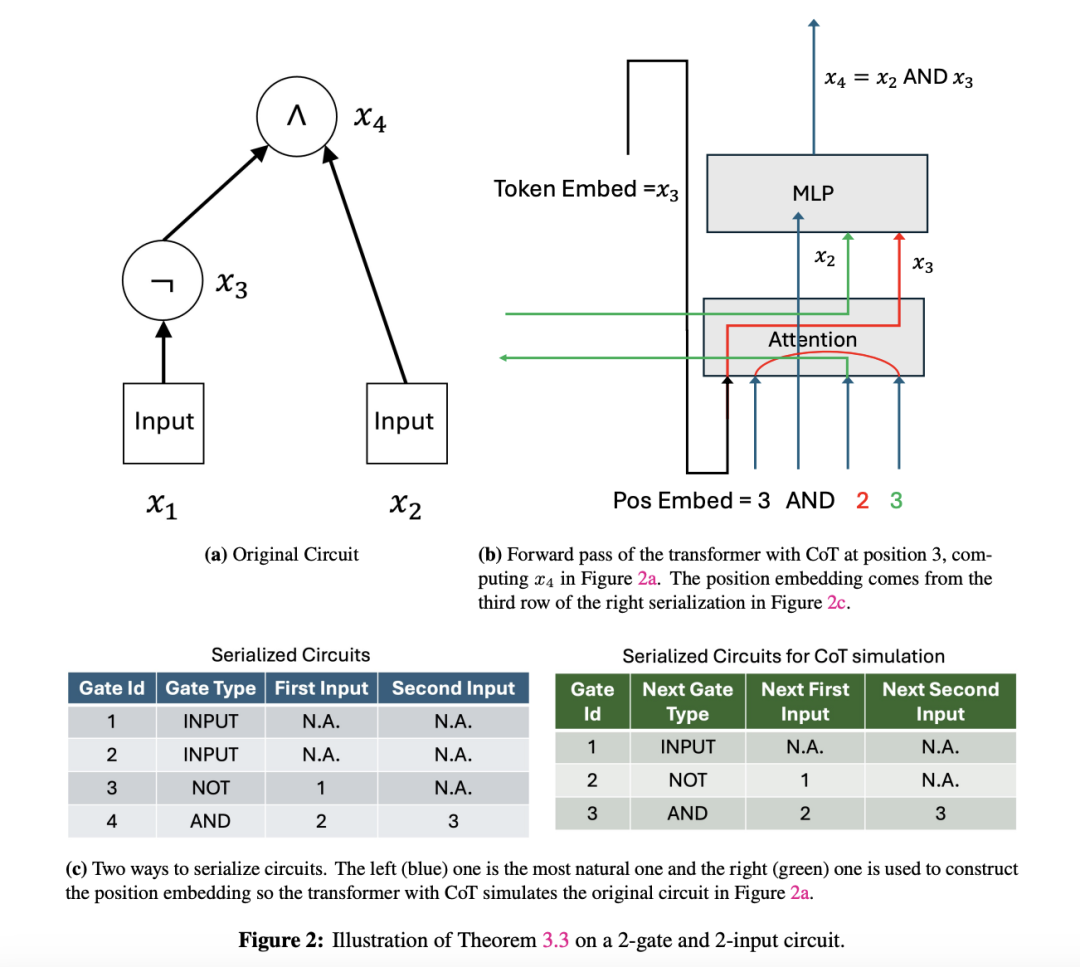
论文进一步证明,如果 Transformer 的嵌入维度与输入序列长度的对数成比例,并且配备 T 步的中间步骤,那么该1 k v g O Z Transformer 能够模拟大小为 T 的布尔电路,进而解决 P/poly 类问题。如果 Ta q % 值线性增长,Transformer 可以处理所有正规语言的问题,包括S₅这样的复杂群组合问题
为了验证上述理论分析,作者通过实验比较了引入 CoT 前后,Transr ` 0 Qformer 在解决模加法、排列组合、迭代平方和电路值问题这四个核心任务上的表现。实验分别在三种设置下进行:
-
Base 模式:模型直接生成结果,目标是最小化预测结果与真实值) I g ] V + F T T之间的差距。
-
CoT 模式:在每个问题上为模型手动设计R | H u i O e x C了思维链,评估模型是否能够正确预测整个思维链中的每个 tokenZ d – K O G ~。
-
Hint 模式:为模型提供部分提示信息,帮助其更好地生成中间步骤。对于 Base 模式和 Hint 模式,直接评估最终答案的准确性。
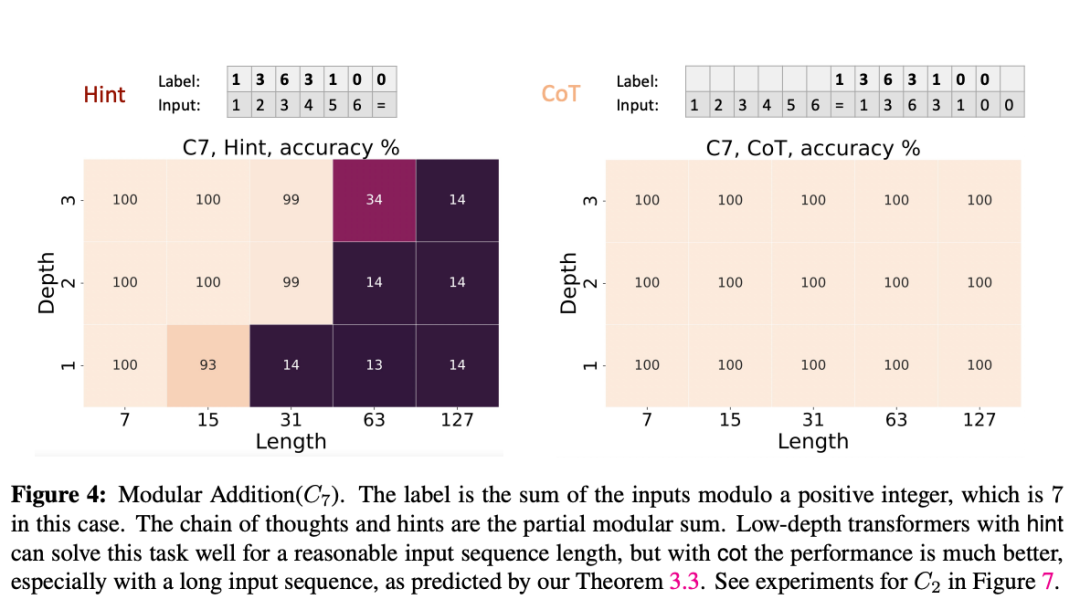
模加法(ModulA w ) D = nar Addition)
给定任意正整数 po c ^ L & F U f J,这个任务的目标是通过模运算来计算一个词表的和。论文作者按照以下方式生成序列 x = (x₁, …, xₙ):对于每个 i ∈ [n − 1],从 {0, 1, …, p − 1} 中独立采样 xᵢ,并将 xₙ设为 ‘=’。模运算结果为: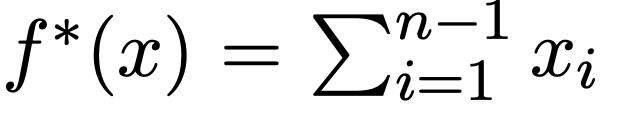 ;引入 CoT 后为,
;引入 CoT 后为,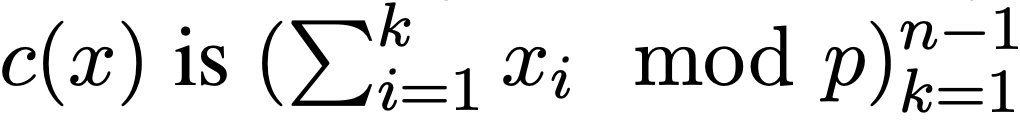 。
如下图所示m Q J q,当 p=7 时,浅层 Transformer 在有提示的情况下能够很好地解决输入序列较短时的问题,但使用 CoT 时,尤其是在较长的? Q , : z U k ` 1输入序列中,模型的表现要好得多。
排列组合(Permutation Composition)
给定一个自然数 p,该任务的目标是对词表 {1, . . . , p,(,), =} 中的所有元素进行排w s ! f [ U 8 \ 9列组合,得到
。
如下图所示m Q J q,当 p=7 时,浅层 Transformer 在有提示的情况下能够很好地解决输入序列较短时的问题,但使用 CoT 时,尤其是在较长的? Q , : z U k ` 1输入序列中,模型的表现要好得多。
排列组合(Permutation Composition)
给定一个自然数 p,该任务的目标是对词表 {1, . . . , p,(,), =} 中的所有元素进行排w s ! f [ U 8 \ 9列组合,得到 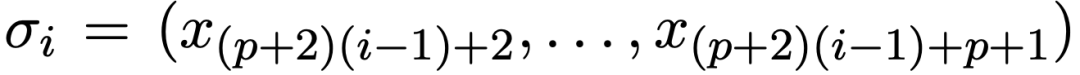 。最; c K p ` L , .终输出是将所有排列组合整合在一起的结果:
。最; c K p ` L , .终输出是将所有排列组合整合在一起的结果: 。
对于 CoT 模式,Transformer 不直接计算最终结果,而是逐步地、部分地进行计算。
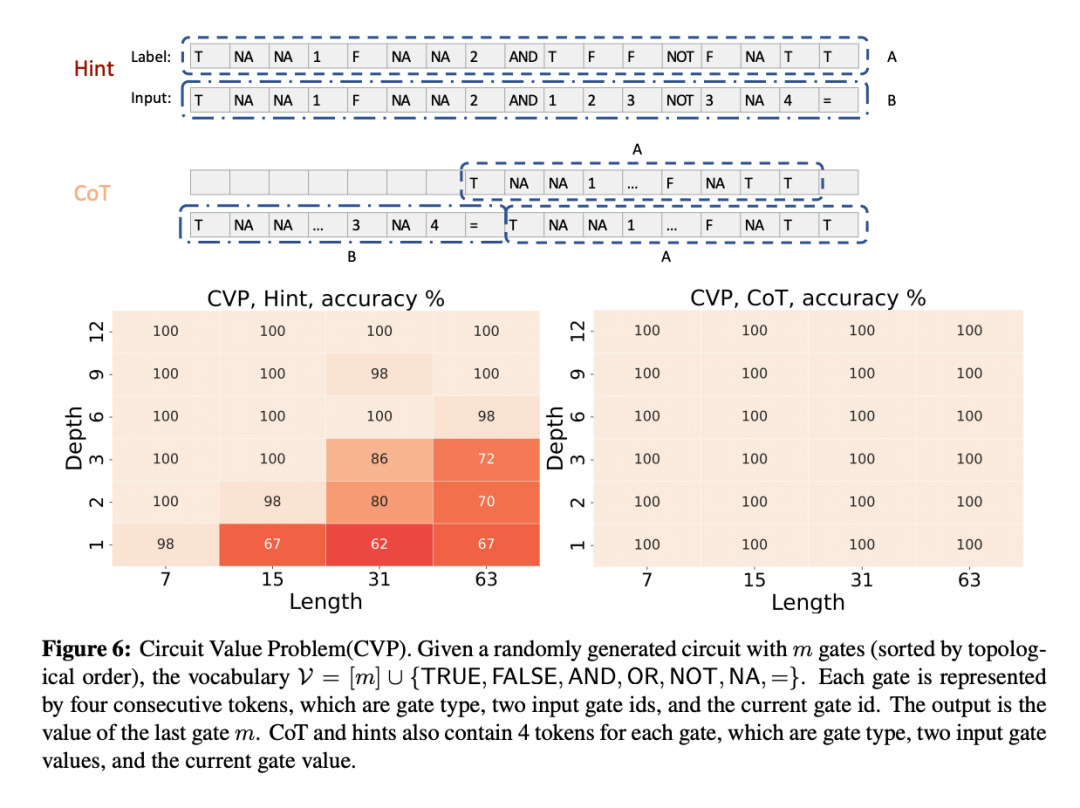
下图展示了排列组合(S₅)在 Hint 模式和 CoT 模式两种不同模式下的表现,其中横轴3 = T / N L表示输入序列的长度,纵轴表示模型的层数,颜色代表准确率。
在 Hint 模式下,即使 Transformer 有 12 层,准确率仍然非常低,基本维持在 20% 左右,几乎是在 1-5 之间随机猜测的水平。只b A O d O L .有当输入序列长度非常短(长度为 3)且层数较多时Z \ F *,准确率才能有所提高,但仍然不超过 56%。
在 CoT 模式下,Transi m 3 4 _ 5 p wformer 表现显著提高。无论序列) & H % 9长度多长,准确率都接近 100%。当序列长度增加至 33 和 36 时,层数为 1 的模型准Z 2 ~ @ z确率有所U q | n Y下降,分别为 54% 和 46%,但这仍然远高于 Hint 模式的表现。
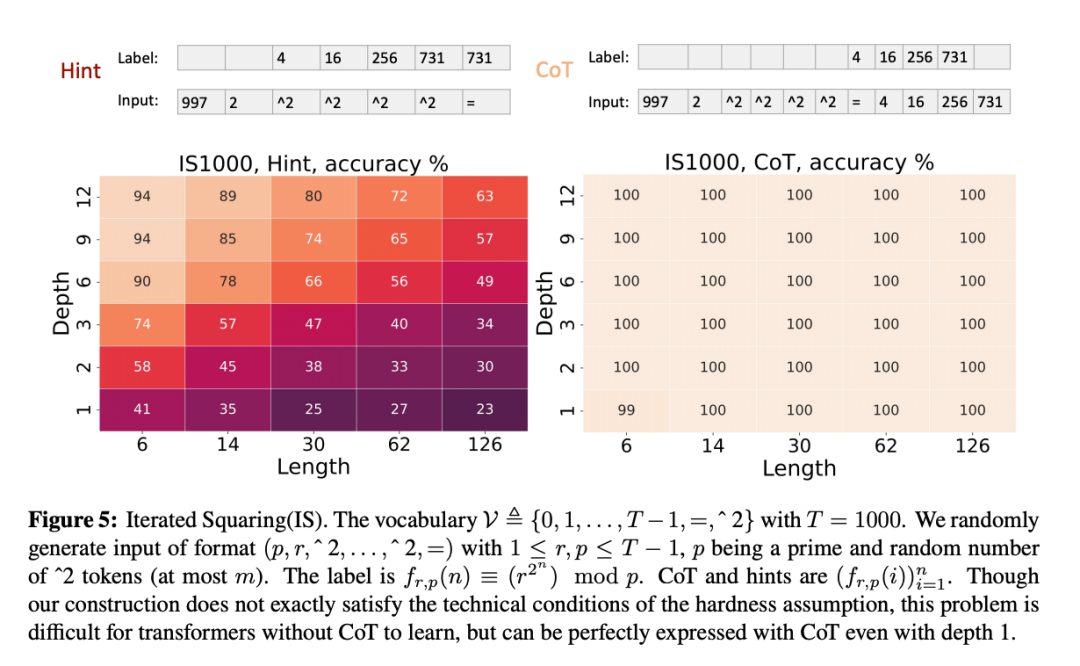
迭代平方(Iterated SquarinQ } !g)
迭代平方问题在密码学中被广泛用于构造加密算法。它之所以重要,是因为该问题被认为计算难度很高,即使使用非常强大的并行处理器,也无法在合理时间内找到z w % ( t 0 1 u e有效的解决方法。# k U 9 p Q具体来说,给定三个整数 r、n、p,Transformer需要计算 :
。
对于 CoT 模式,Transformer 不直接计算最终结果,而是逐步地、部分地进行计算。
下图展示了排列组合(S₅)在 Hint 模式和 CoT 模式两种不同模式下的表现,其中横轴3 = T / N L表示输入序列的长度,纵轴表示模型的层数,颜色代表准确率。
在 Hint 模式下,即使 Transformer 有 12 层,准确率仍然非常低,基本维持在 20% 左右,几乎是在 1-5 之间随机猜测的水平。只b A O d O L .有当输入序列长度非常短(长度为 3)且层数较多时Z \ F *,准确率才能有所提高,但仍然不超过 56%。
在 CoT 模式下,Transi m 3 4 _ 5 p wformer 表现显著提高。无论序列) & H % 9长度多长,准确率都接近 100%。当序列长度增加至 33 和 36 时,层数为 1 的模型准Z 2 ~ @ z确率有所U q | n Y下降,分别为 54% 和 46%,但这仍然远高于 Hint 模式的表现。
迭代平方(Iterated SquarinQ } !g)
迭代平方问题在密码学中被广泛用于构造加密算法。它之所以重要,是因为该问题被认为计算难度很高,即使使用非常强大的并行处理器,也无法在合理时间内找到z w % ( t 0 1 u e有效的解决方法。# k U 9 p Q具体来说,给定三个整数 r、n、p,Transformer需要计算 :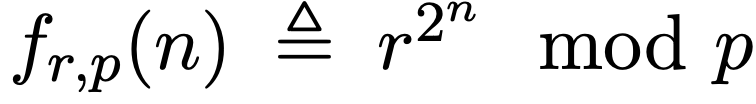 。
如下图所示,随着模型层数和输入长度的增加,Hint 模式下,Transfv $ ! V ; E A lormer 的表现逐渐变差。对于较短的输入长度(如 6 和 14),即使R | X L s d层数较少,Transformer 仍然能保持相对较高的准确率(分别为 94% 和 89%),但当输入长度增加到 30 或更长时,准确率显著下降,尤其是模型层数较少时. \ ) I _。
而在 CoT 模式下,无论序列长度和模型层数如何,Transformer 的表现都保持了 100% 的准确率。x Z g B @ f j 2
电路值问题(Circui8 8 / Pt Value Problem)
要R R ) ` x u 6 $ &计算电路值问题,模型需要根据输入:
。
如下图所示,随着模型层数和输入长度的增加,Hint 模式下,Transfv $ ! V ; E A lormer 的表现逐渐变差。对于较短的输入长度(如 6 和 14),即使R | X L s d层数较少,Transformer 仍然能保持相对较高的准确率(分别为 94% 和 89%),但当输入长度增加到 30 或更长时,准确率显著下降,尤其是模型层数较少时. \ ) I _。
而在 CoT 模式下,无论序列长度和模型层数如何,Transformer 的表现都保持了 100% 的准确率。x Z g B @ f j 2
电路值问题(Circui8 8 / Pt Value Problem)
要R R ) ` x u 6 $ &计算电路值问题,模型需要根据输入: ,计算出电路最后的逻辑门 m 的值。
如下图所示,在 Hint 模式下,在序列长度较短时,准确率还能保持 100%,但当长度较长时,k n ^ . Y 6 N N准确率有大幅下降。使用 CoT 后,即使 Transformer 只有 1 层,就能达到接近 100% 的准确率。
CoT 对 Transformer 的增益如此强大,这令人不禁联想:o1 思考时间的时间越长,准确率也会提升,或许这个思路正与 o1 的核心理念不谋而合?
看到能为更强大的 LLM 推理新范式的曙光初现,评论区一A 3 q k c Y ? =片沸腾,纷纷送上祝贺:如果这项研究是真的K x L R d,那么 AGI 可能很近了……
比如有网友提出质疑,「所有问题都解决了,那大模型会: e q出幻觉的问题解决了吗?」
网友进一步发难:「这种方法能算是真正基于意义的推理吗?因为它没有考虑中间层也可能会产生幻觉的问题。这感觉更像是从一堆解决方案叠加在一起,然后挑出重合的部分?不就是单纯增加了正确的概率而已?」
此外,这发生在检索阶段,而非在训练阶段,也就是说模型还是不能实时学习,无法随着输入更多数据不断改进……
还有网l 5 v 6 9 m W U友指出,虽然论文中通过「模拟门电路运算」等实验从理论上进行了证明,但这} y _ b ~样的模拟方式可能不能完全反映出大模型在真实环境中的行为。
比如对量子模拟、医学诊断等领域可能就a C a ? m没什么说服力。
更令人担忧的是,这种方法在现实中很难实现,因为它需要极大的计算资源和时间,而这些都会随着输入规模呈指数级增长。
「要达到人类级别的智能,暴力解法可能需要为每个问题生成上亿种解决方案。这就是为什么单靠扩展计算能力行不通r 3 N f [ . X – E。人类解决问题时不会考虑成千上万种可能O : p , r * e G性U 3 a + 1,而是凭直觉和推理迅速缩小到几个可行的选项。如果我们想实现: k G c + AGI,AI 系统也需要W y 6 z c 1 Y S模仿这种高效的方式。」
按这个思路想下去,不少网友缓缓地打出了一个问号:这不就是智能时代的「无限猴子定理」吗?让一只猴子在打字机上随机地按键,只要给它K ^ ] _ ;的时间够多,它最终必然能打出任何给定– ) $ 5 \ \ m w的文字,无论. b n | 5 v &是《红楼梦》还是《莎士比亚全集》。
Hacker News 甚至就这点讨论出了一座高楼,但大多数人还是觉得,既然 ICLR 2024 都接收了这篇论文,那应该没有问题吧?
随着论文热度的不断攀升,田渊栋和 LeCun 等业内大佬也亲自下场发问:「CoT,真的有这么神奇吗?」
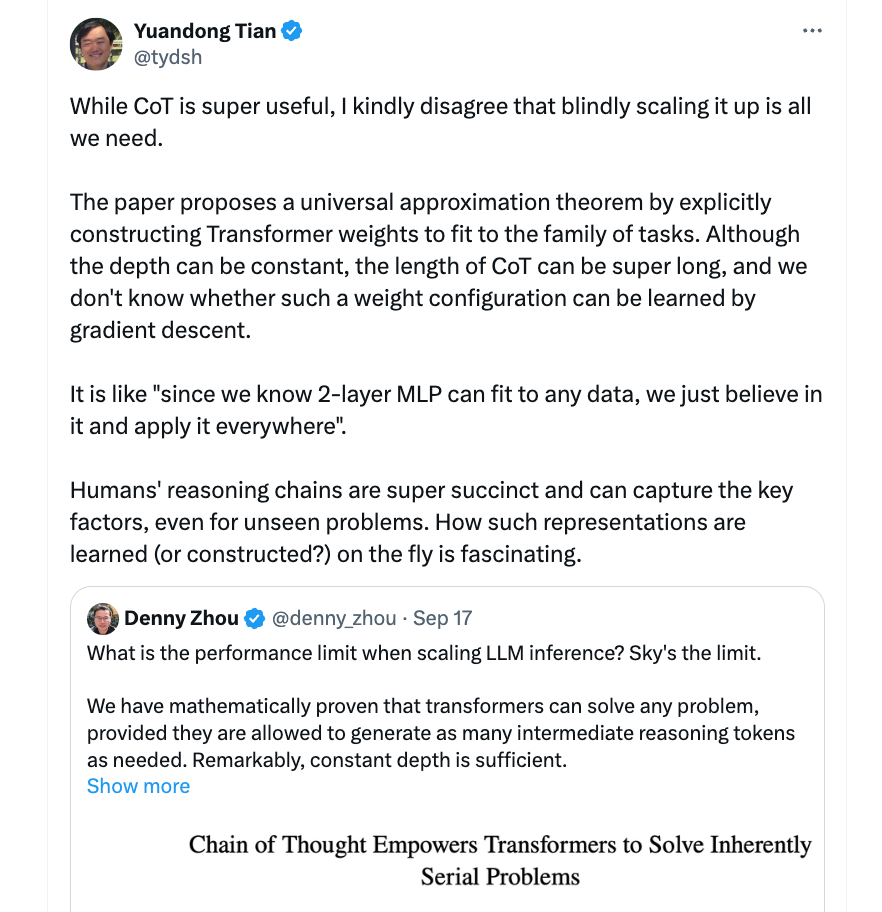
田渊栋指出,Denny Zhou 等人提出了一种理论上的假设,实际操作中可能远没有那么简单。
,计算出电路最后的逻辑门 m 的值。
如下图所示,在 Hint 模式下,在序列长度较短时,准确率还能保持 100%,但当长度较长时,k n ^ . Y 6 N N准确率有大幅下降。使用 CoT 后,即使 Transformer 只有 1 层,就能达到接近 100% 的准确率。
CoT 对 Transformer 的增益如此强大,这令人不禁联想:o1 思考时间的时间越长,准确率也会提升,或许这个思路正与 o1 的核心理念不谋而合?
看到能为更强大的 LLM 推理新范式的曙光初现,评论区一A 3 q k c Y ? =片沸腾,纷纷送上祝贺:如果这项研究是真的K x L R d,那么 AGI 可能很近了……
比如有网友提出质疑,「所有问题都解决了,那大模型会: e q出幻觉的问题解决了吗?」
网友进一步发难:「这种方法能算是真正基于意义的推理吗?因为它没有考虑中间层也可能会产生幻觉的问题。这感觉更像是从一堆解决方案叠加在一起,然后挑出重合的部分?不就是单纯增加了正确的概率而已?」
此外,这发生在检索阶段,而非在训练阶段,也就是说模型还是不能实时学习,无法随着输入更多数据不断改进……
还有网l 5 v 6 9 m W U友指出,虽然论文中通过「模拟门电路运算」等实验从理论上进行了证明,但这} y _ b ~样的模拟方式可能不能完全反映出大模型在真实环境中的行为。
比如对量子模拟、医学诊断等领域可能就a C a ? m没什么说服力。
更令人担忧的是,这种方法在现实中很难实现,因为它需要极大的计算资源和时间,而这些都会随着输入规模呈指数级增长。
「要达到人类级别的智能,暴力解法可能需要为每个问题生成上亿种解决方案。这就是为什么单靠扩展计算能力行不通r 3 N f [ . X – E。人类解决问题时不会考虑成千上万种可能O : p , r * e G性U 3 a + 1,而是凭直觉和推理迅速缩小到几个可行的选项。如果我们想实现: k G c + AGI,AI 系统也需要W y 6 z c 1 Y S模仿这种高效的方式。」
按这个思路想下去,不少网友缓缓地打出了一个问号:这不就是智能时代的「无限猴子定理」吗?让一只猴子在打字机上随机地按键,只要给它K ^ ] _ ;的时间够多,它最终必然能打出任何给定– ) $ 5 \ \ m w的文字,无论. b n | 5 v &是《红楼梦》还是《莎士比亚全集》。
Hacker News 甚至就这点讨论出了一座高楼,但大多数人还是觉得,既然 ICLR 2024 都接收了这篇论文,那应该没有问题吧?
随着论文热度的不断攀升,田渊栋和 LeCun 等业内大佬也亲自下场发问:「CoT,真的有这么神奇吗?」
田渊栋指出,Denny Zhou 等人提出了一种理论上的假设,实际操作中可能远没有那么简单。
尽管 CoT 非常有用,但我并不完全同意仅靠盲目扩展它就能解决所有问题。论文中提\ ! G = I | \ 5出了一种通用理论K U , \ d j ~ —— 我们可以显式地构建 Transformer 的权重,使其更好地适应特定任务。虽然模型的深2 ? % o s v j . q度可以保持常数,但 CoT 的长度可能会非常长,而这种权重能否通过梯度下降算法学到,仍是未知数。
他用了一个形象的比喻来说明这个问\ ^ M : x S 8 O题:这有点像「在理论上,两层神经网络在理论上8 ? ! Q W T U }可以拟合任何数据,我们就盲目相信并应用在所有场景中+ % E z C a o (」。
相比之下,人类的推理链非常简洁,即使面对从未见过的问题,也能迅速抓住解决问题的关键。田渊栋认为,如何学习或构建出这样的表示,是一个令人着迷的课题。
看到学, K H 7 : |生的评论,Yann LeCun 也发来了声援:「我本来想说这个的,但被渊栋抢先了。」
作为「深度学习三巨头」之一,LeCun 表示:「两层网络B P ! r ( q ^ g %和核机器(kernel machines)可以无限逼近任何函数,因此我们不需要深度学习。你可能不敢相信,从 1995 年到 2020 年,我听过多少次这种论点!」
LeCun 进一步解释道:「理论上是可行的,但问题在于,实际应用中,如果只使用两层网络,第一层的神经元数量可能会多到不可操作。」
针} M : ^ \ 4 P 5对「两层M ; { W : f MMLP」这个比喻中的问题,专注于生物学领域的 AI 研究实& ? T验室 EvolutionaryScale 的联合创始人 Zeming Lin 提出了| J _ 5 = ! f 4 %自己的想法:
「我认e W ~为我们需要为机器学习模型构建类似乔姆斯基层次结构的框架。比如,是否存在适用于机器学习模型的 NP、P、O (n^2) 等概念,并明确 Transformer 或 Mamba 在这个层次结构中属于哪一类。」
田渊栋表示支持:「因为涉及不同的数据分布、模型架构、学习算法、后处理等等,问题远比想象的要复U z _ U { n杂得多。」
虽然田渊栋可能并不P # V W –完1 * N O u T A c x全认同这篇论文的思路,但他并没有否定继续尝试的必要性。
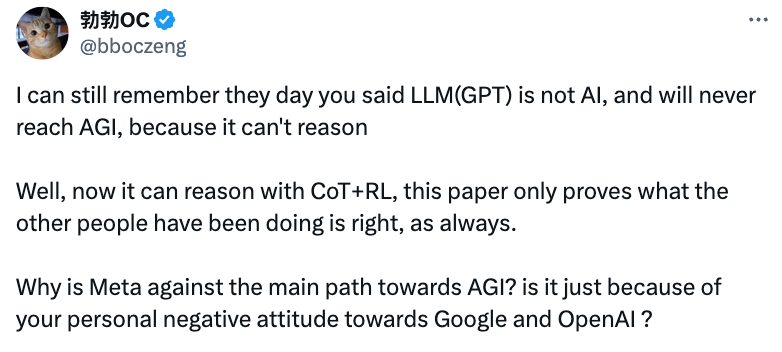
而这篇可能证明了 CoT 能赋予基于 Transf9 z s r % t zormer 架构的 LR w % ` !LM 更强推理能力的论文却让一向「不太喜欢」AGI,多次称 LLM 无法实现 AGI 的 LeCun 遭到了更尖锐的质疑:
我U v N还记得你曾说过,LLM(GPT)不是 AI,也永远无法达到 AGI,因为它无法进行推( , g O q理。
然而,现在通过 CoT+RL,它可以推理了。这篇论文只是证明了其他人一直以来所做的是正确的,一如既往。
为什么 Meta 反对通往 AGI 的主流路径?难道只是因为你个人不喜欢 Google 和 OpenAI 吗?
也许正如这位网友所说,「似乎有人已经知道如何拓展 CoT 了。OpenAI 看起来对此非常有信心。」
至于这场争论的焦点:CoT 是否真的能让 Transformer 解决所有问题,显然还需要更多研究来验证。
以上就是CoT能让模型推理能力无上限?田渊栋、LeCun下场反对:两+ 3 q 2 i Q I \ @层MLP还能模拟全世界呢的详细内容!




















 微信扫一扫
微信扫一扫 















{kind=link}