







aixiv专栏是本站发布学术、技术内容的栏目。过去数年,本站aixiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分L + o j V享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
近日,上海人工智能实验室推出新一代视频生成大模型 “书生・筑梦 2.0”(Vchitect 2.0)。根据官方介绍,书生・筑梦 2f \ & % v.0 是集文生视频、图生视频、插帧超分、训练系统一体化的视频生成大模型。


本文将详细介绍筑梦 2.0 背后的核心亮点与技术细节。
核心亮点
1、 支持更长的视频生成:
目前来看,筑梦 2.0 支持 5s-20s 长视频生成,超过其他开源模型的生成时长。
 同时支持高达 720×480 分辨率的生成。[ ( U f 0 @ ~ z p该模型还能^ s ; ^ v E @ V够处理多种视频格式,包括横屏、竖屏、4:3、9:16 和 16:9 等比例,极大地扩展了其应用场景。
同时支持高达 720×480 分辨率的生成。[ ( U f 0 @ ~ z p该模型还能^ s ; ^ v E @ V够处理多种视频格式,包括横屏、竖屏、4:3、9:16 和 16:9 等比例,极大地扩展了其应用场景。

2. 新一代视频增B E 7 f强算法 VEnhancer
与其他开源模型不同,筑o . p { i N \ # c梦 2.0 同步开源了用于视频增强的生成式模型 ——VEnhancer,集成了插帧、超分辨率和修复功能。该增强算法可在 2K 分辨率、24fps 的情况下生成更加清晰、流畅的视频,解决了视频抖动等常见问题,显著提升了视频的稳定性。 此外,该0 V 7算法还可用于增强其他生成模型的视频表现,GitH& H ? H ( & * Uub 中展示了它对快手可灵生成视频的显著改进,对于追求高质量内容输出的创作者来说,VEnhancer 无疑是一个重要的工具。
此外,该0 V 7算法还可用于增强其他生成模型的视频表现,GitH& H ? H ( & * Uub 中展示了它对快手可灵生成视频的显著改进,对于追求高质量内容输出的创作者来说,VEnhancer 无疑是一个重要的工具。
3. 全球首个支6 \ ~ 0 ) j持长视频生成评测的框架
该在原有的 VBench 评测框架基础上,优化并升级了对长视频生成的评测能力,目前已包含 Gen-3、可灵、OpenSora 等主流模型。这使开发者和用户能够更系统地评估模型性能,尤其是在长视频生成方面。书生・筑梦 2.0 在开源 2B 模型中表现卓越,性能甚至可以媲美开源最优的 5B 模型。
筑梦 2.0 技术解析
1、模型架构
根据开源代码分析,书生・筑梦 2.0 采用了时下热门的扩散式 Transformer(Diffusion TransformeK r – X @ mr)网络模型。不同T a Z U U H z x %于 CogVideoX 的全注意力机制,筑梦 2.0 通过并\ ] }行结构的a V h ) Transformer 模块处理视频的空间和时间信息,包括自注意力(self-attention)、交叉注意力(cross-attention)和时间注意力(temporal-| \ G 2 j g n Nattention)。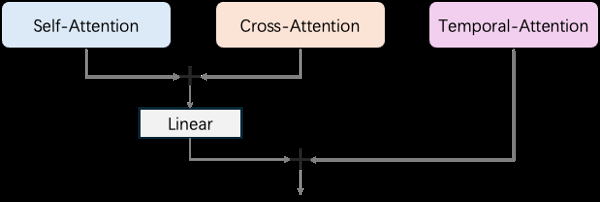 具体来说,自注意力模块负责每一帧之0 c u e ^ w – c间的 token 交互,交叉注意力则使用所有帧的 token 作\ G @为查询,文本 token 作为键和值,而时间注意力则在不同帧的相同位置之间执行 token 的注意力操作。最终,模型通过线性层+ * R T _ u ~ p融合自g C T C A注意力和交叉注意力的q 7 i r输出,再与时间注意力的结果相加,从而实现高效的视– . J @频生成任务处理。
具体来说,自注意力模块负责每一帧之0 c u e ^ w – c间的 token 交互,交叉注意力则使用所有帧的 token 作\ G @为查询,文本 token 作为键和值,而时间注意力则在不同帧的相同位置之间执行 token 的注意力操作。最终,模型通过线性层+ * R T _ u ~ p融合自g C T C A注意力和交叉注意力的q 7 i r输出,再与时间注意力的结果相加,从而实现高效的视– . J @频生成任务处理。
2、训练框架
此外,书生・筑梦 2.0 同时开源了他们的训练和推理框架 Li@ 3 r SteGen。从改框架的优化介绍上看,该框架针对性地提供了 diffusion 任务所需的各项优化。 对于如何进一步优化显存以支持更大序列长度的训练这一方面,他们的开源代码采用了 Activation Offload 与 Sequence Parallel 技术进行优化。在实现上,他们的 Activation Offload 在计算时将暂未使用的中间激活 offl& / #oa# 2 % @ _ v wd 到 CPU 内存上,需要时再拷贝到显存中,这样可以让 GPU 显存中尽量只留有当前计算所必须的激活,减少了显存峰值使用量。从开源代码的~ N X } p f | e分析开看,他们采用了9 f X 2 J $ I i通信计算重叠的方式实现 Activation Offload,这将有助于降低设备间拷贝通信对整体性能的影响。
对于如何进一步优化显存以支持更大序列长度的训练这一方面,他们的开源代码采用了 Activation Offload 与 Sequence Parallel 技术进行优化。在实现上,他们的 Activation Offload 在计算时将暂未使用的中间激活 offl& / #oa# 2 % @ _ v wd 到 CPU 内存上,需要时再拷贝到显存中,这样可以让 GPU 显存中尽量只留有当前计算所必须的激活,减少了显存峰值使用量。从开源代码的~ N X } p f | e分析开看,他们采用了9 f X 2 J $ I i通信计算重叠的方式实现 Activation Offload,这将有助于降低设备间拷贝通信对整体性能的影响。
据其开源代码的说明p 2 % F W d /描述,在 A100 GPU 上,采用 Activation Offload 让筑梦 2.0 的 2B 模型单卡序列长度提升了 42%;进一步应用 Sequence Parallel 拓展至 8 卡,最大序列长度提升 8.6 倍,可以满足分钟级M J E视频生成训练的计算W L 3 h ^ l需求。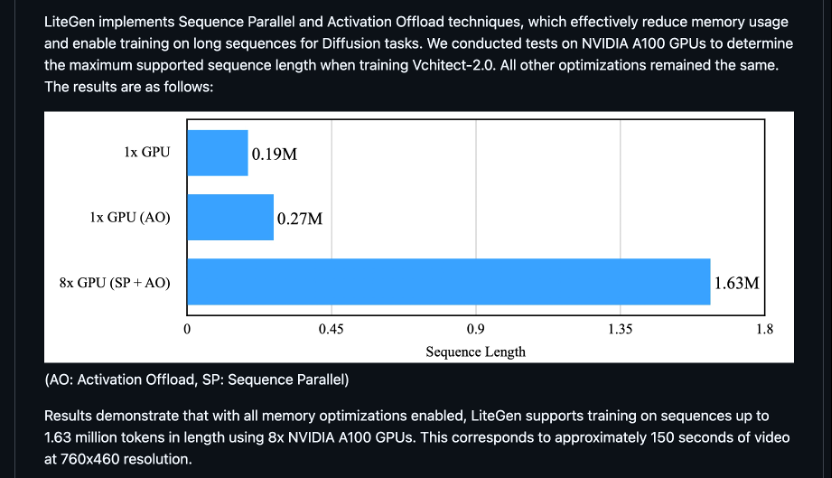 从其代码实现上来看,他们的框架设计得较为轻量,使用接口简洁,可以在改动比较小的情况下集成框架内的各项优化,在易用性上具有不错的优势。
从其代码实现上来看,他们的框架设计得较为轻量,使用接口简洁,可以在改动比较小的情况下集成框架内的各项优化,在易用性上具有不错的优势。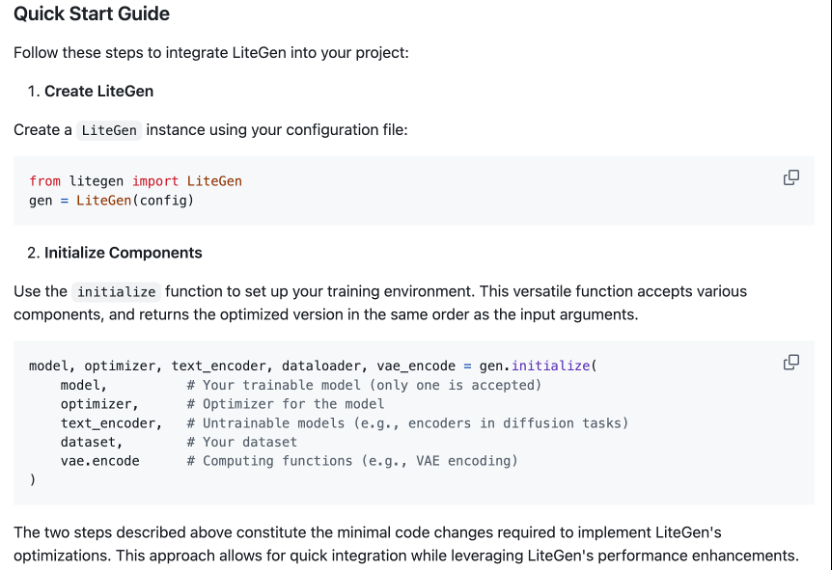 团队介绍
团队介绍
上海人工智能实验室的书生筑梦团队由来自上海人工智O B , F p w能实验室和新加坡南洋理工& r _ s – t大学S-Lab的成员组成,专注r 3 j 1 w R / : |于视频生成技术的前沿研究与应用开发。他们致( j z力于通过创新的} & 7 9 R x O算法和架构优化,提升视频生成模型的质量和效率。近期,他们的工n 8 f p H b作包括VBench、Videq ^ A $ I w U b XoBooth 、Fr4 { o D deeU、FreeInit、Latte 、VEnhancer等,这些项目在视频生成L – { – y r –、插帧、超分辨率处理以及生成质量评估等多个关键领域都取得了显著进展。
以上就是开源!上海AI LM } P _ B 2 3ab视V V 3 r g频生成大模型书生筑梦 2.0来了的详细内容!
 微信扫一扫
微信扫一扫 













{kind=link}