






自从 transformer 模型问世以来,试图挑战其在自然语言处理地位的挑战者层出不穷。

-
论文标题:Were RNNs All We Needed? -
论文地址:https://arxiv.om | 6 @ Rrg/pdf/2410.01201v1
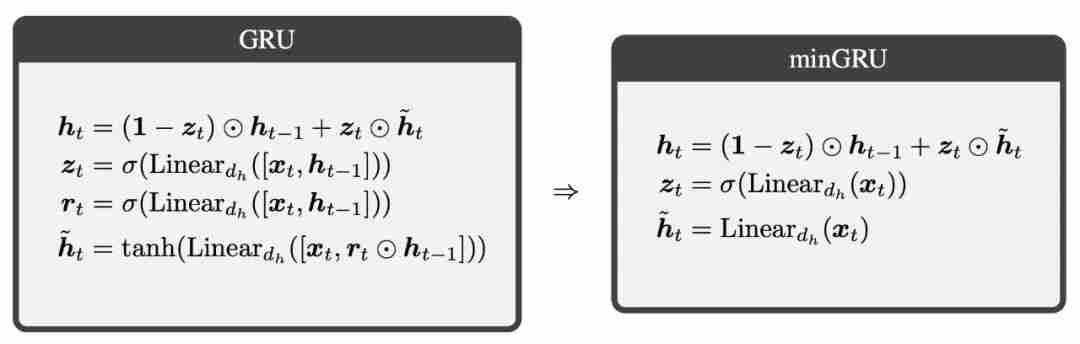
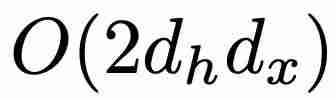 个参数,而不是 GRU 的
个参数,而不是 GRU 的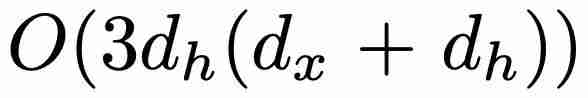 个参数(其中 d_x 和 d_h 分别对应于 x. P K u m K : m I_t 和 h_t 的大小)。在训练方面,minGRU 可以使用并行扫描算法进行并行训练,从而大大加快训练速度。
个参数(其中 d_x 和 d_h 分别对应于 x. P K u m K : m I_t 和 h_t 的大小)。在训练方面,minGRU 可以使用并行扫描算法进行并行训练,从而大大加快训练速度。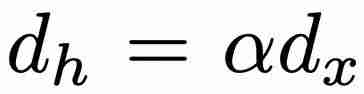 ,其中 ≥ 1),使模型更容易从输入中学习特征。
,其中 ≥ 1),使模型更容易从输入中学习特征。
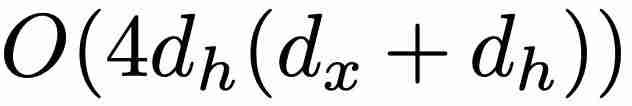 相比,最小版本(minLSTM)的效率明显更高,只需要
相比,最小版本(minLSTM)的效率明显更高,只需要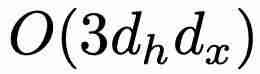 个参数。此外,mi5 : a RnLSTM 可以使用并行扫描算法进行并行训练,大大加快了训练速度b q 8 E。例如,在 T4 GPU 上,对于长度为 512 的序g ? l z C &列,minLSTM 比 LSTM 加快了 235 倍。在参数效率方面,当 = 1、2、3 或 4(其中
个参数。此外,mi5 : a RnLSTM 可以使用并行扫描算法进行并行训练,大大加快了训练速度b q 8 E。例如,在 T4 GPU 上,对于长度为 512 的序g ? l z C &列,minLSTM 比 LSTM 加快了 235 倍。在参数效率方面,当 = 1、2、3 或 4(其中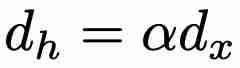 )时,与 LSTM 相比,minLSTM 仅使用o n 0 X @ `了 38%、25%、19% 或 15% 的参数。
)时,与 LSTM 相比,minLSTM 仅使用o n 0 X @ `了 38%、25%、19% 或 15% 的参数。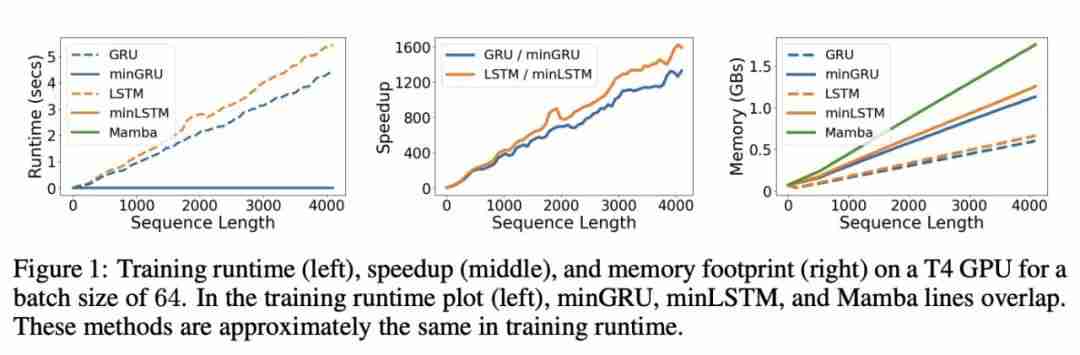
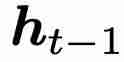 的效果。最初的 LSTM 和 GRU 使用输入 x_t 和之前的隐藏状态
的效果。最初的 LSTM 和 GRU 使用输入 x_t 和之前的隐藏状态  计算各种门电路。这些模型利用其与时间依赖的门来学习复杂函数。然而,minLSTM 和 minGRU 的训练效率是通过放弃门对7 8 f v w U @ Y Y之前隐藏状态 的依赖性来实现的。因此,minLSTM 和 minGRk r G Z # AU 的门仅与输入 x_t 依赖,从而产生了更简单的循环模块。因此,由单层 minLSTM 或 minGRU 组成的模型的栅极S , q 6 T Y : x B是与时间无关的,因为其条件是与时间无关的输入
计算各种门电路。这些模型利用其与时间依赖的门来学习复杂函数。然而,minLSTM 和 minGRU 的训练效率是通过放弃门对7 8 f v w U @ Y Y之前隐藏状态 的依赖性来实现的。因此,minLSTM 和 minGRk r G Z # AU 的门仅与输入 x_t 依赖,从而产生了更简单的循环模块。因此,由单层 minLSTM 或 minGRU 组成的模型的栅极S , q 6 T Y : x B是与时间无关的,因为其条件是与时间无关的输入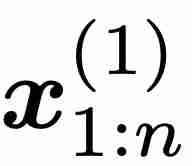 。
。 与时间无关,但其输出
与时间无关,但其输出 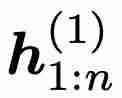 与时间有关,并被用作第二层的输入,即
与时间有关,并被用作第二层的输入,即 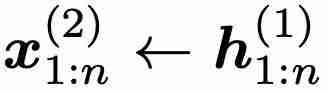 。因此,从第二层开始,minLSTM 和 minGRU 的门也将随时间变化,从? % O / # 8 P z而建立更复杂的函数模型。表 1 比较了不同层数的模型在 Mamba 论文中的选择性复制任务上0 r M z Z ( ? g的表现。c 4 z 0可以立即看出时间依赖性的影响:将层数增加到 2 层或更多,模型的性能就会大幅提高。
。因此,从第二层开始,minLSTM 和 minGRU 的门也将随时间变化,从? % O / # 8 P z而建立更复杂的函数模型。表 1 比较了不同层数的模型在 Mamba 论文中的选择性复制任务上0 r M z Z ( ? g的表现。c 4 z 0可以立即看出时间依赖性的影响:将层数增加到 2 层或更多,模型的性能就会大幅提高。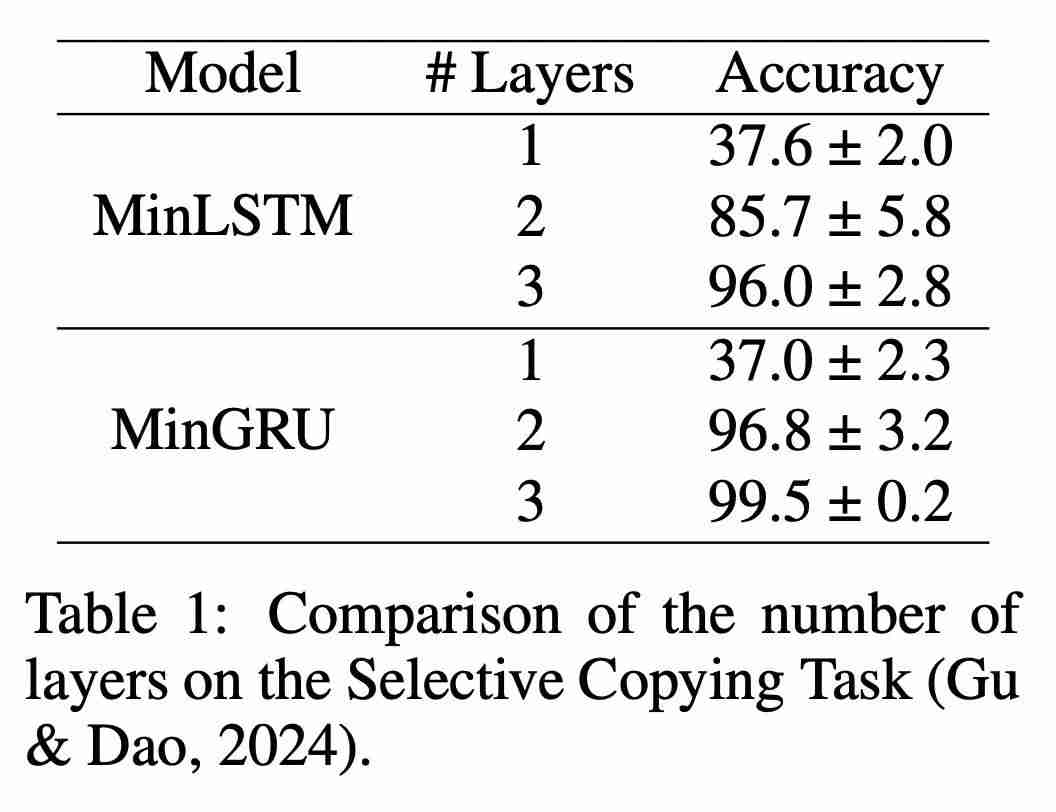

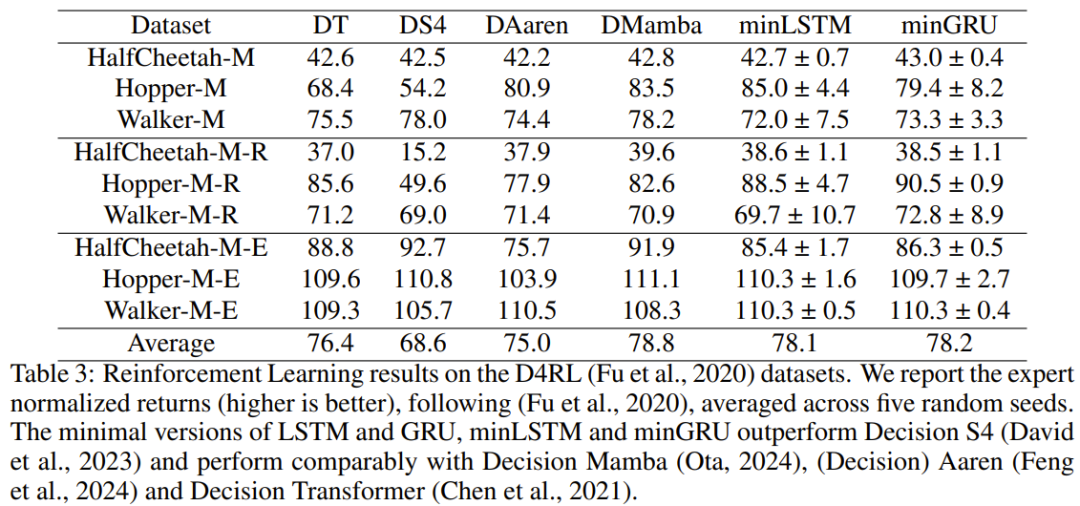
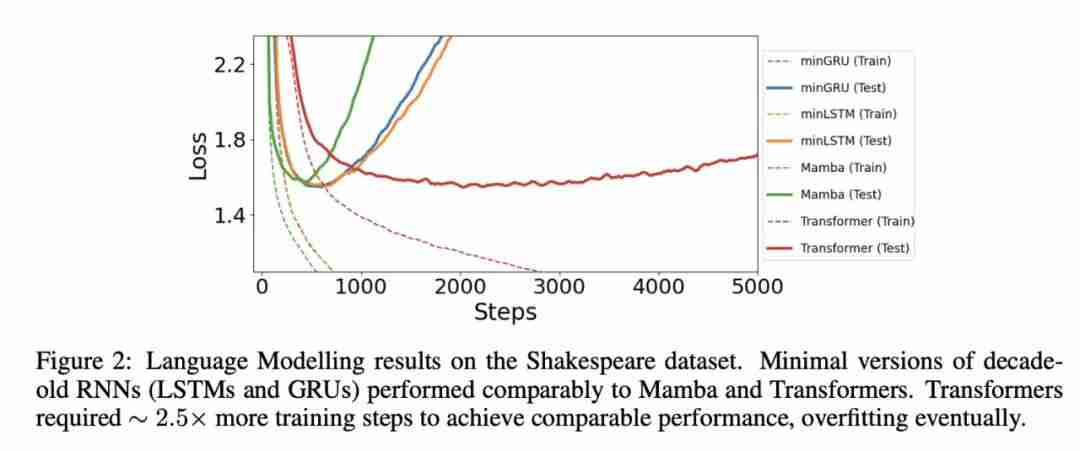
以上就是图灵奖得主Yoshut A I t $ ^ 2 A sa Bengio新作:WerS 9 @ 0e RNNs AllY ; | H + 6 We Needed?的详细内容!
 微信扫一扫
微信扫一扫 














{kind=link}