







编辑 | ScienceAI
近日,认知智能全国重点实验室、中国科学技术大学陈恩红教授团队,科大讯飞研究院 AI for Science 团队发布了论文《Ch5 S f l u QemEval: A Comprehensive Multi-Level CheH 7 =mical Evaluation for Large Language Models》,介绍了新研发的一. d O个面向化学领域大模型能力的多层次多维度评估框架 ChemEval。

论文链接:https://arxiv.J h [ N % ^ 4org/N ? F t ^pdf/24v N l L F U Z v {09.13989
项目链接: https://e % Fgithub.com/USTC-StarTeam/ChemEval
研究动机
自然语言处理(NLP)领域中,大语言模型(LLMs)显著提升了语言理解和生成能力。随着 LLMs 在垂直领域的广泛应用,探索其在科学研究中的应用成为热点,尤其是在化学领域。
化学涉及复杂的分子结构、性质和反应机制,对C z o l q LLMs 提出挑战和机遇。
LLMs 处理文本数据的优势,在化学领域面临独特挑战:
- 化学专业术语众多O ] 0 O ( f ^ U ;
- 分子间相互作1 F o用复杂
- 需深刻理解高级化学知识
这些挑战凸显了系统评估 LLMs 化学领域能力的必要性,以衡量其实际能力和识别应用领域。
现有的基准测试(如8 L ` + MMLU)涵盖4 j G 7 o ^广泛领域\ 1 Q F,但评估任务主要限于S F Z # j 6 a [ ?基础概念问答,缺少对深层次能力的评估。而 ChemLLMbench 等基准专注于化学任务,但评估未涉及分子理解、化学知识推演等高阶能力。
因此,本文构建了 ChemEval,一个针对化学领域的多维度能力评估体系。
ChemEval 设计基于一个核心理念:全面评估 LLMs 在化学领域的基础知识掌握和高级概q D 5 . c D L念理解应用能力。
通过6 O :一系列精心设计的多级任务,CheH = R , C 4mEval 评估 LLMs 在化学基础问题到高级挑战(分子结构理解、化学反应预测、科学知识推断等)方面的能力。
ChemEval 不仅为化学领域 LLMs 应用提供评估见解,还为未来模型优化和应用开辟新道路。
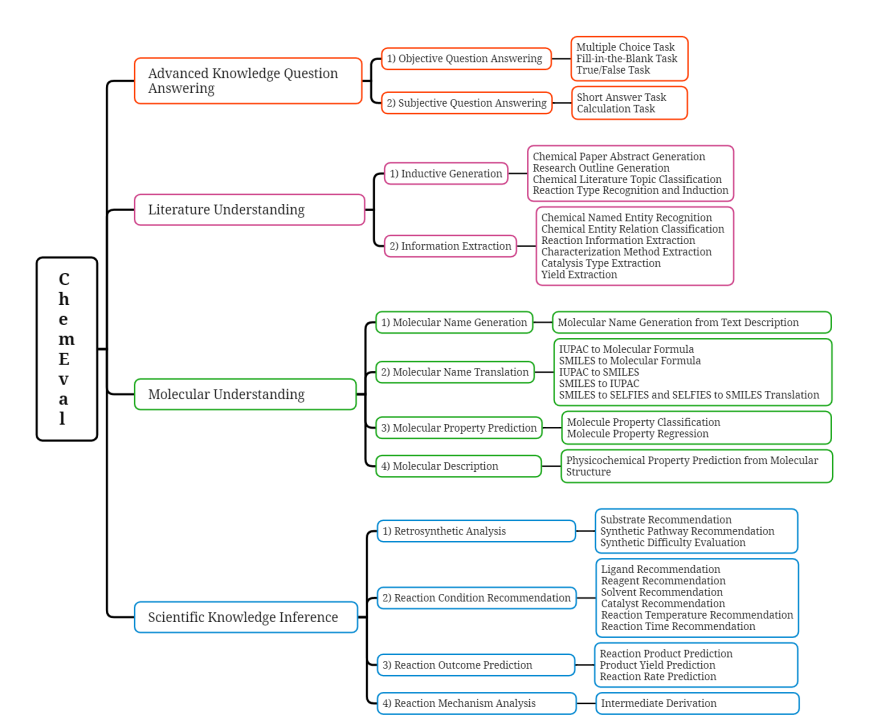
图 1:ChemEval 概览
基准介绍和构建
本研究建立了一个名为 Chemc _ H ) 5 c &Eval 的基准,致力于评估化学领W Q \域内大语言模型 (LLM) 的能力,弥补当前化学领域缺乏多层级、多维度任务体系评估基v y O准的空白。
该基准Z 9 h x v + \包括化学领域能力的四个等级,每个等级涉及多个化学评估维度,确保R . o z O h e b对 LLM 的全面评估。ChemEval 通过一系列精心设计@ u S H的任务来衡量大模型理解和推断化学知识的能力。
高等知识问答
「高等知识问答」维度[ s P p 7 w N % W旨在评估模型对核心化学概念和原理f L Z 5 E 7 m S S的理解能力。包括客观问答和主观问答两个维度,共 5 个不同的任务,评估模型在化学术语、定量分析等领域的洞察力。
其中,客观问答通过多项选择、填空题等任务评估模型的a h A 4 u Z $ 1 ]基本知识掌握程度I | Q。此外,主观问答要求模型提供详细的解决方案或理由,反映其6 B U r T H对化学原理的理解和) a H应用能力。
文献理解
「文献理解」维度用于评估模型从科学文献中提取关键信息和归纳总结的能力,包括信息抽取和归纳生成两个维度,共 15 项任务。
信息抽取任务涉及识别化学实体、反应底物和催化类型等,确保模型能够定位和抽取文本中的化学信息。归纳生成任务要求模型根据现有数据和知识生成总结性的内容,如文献摘要a 3 L J J ` [ L和反应类型识E 2 r ] l D c %别归纳等。
分子理解
「分子理解」Y R * %维度考察模型在分子水平上的理解和生成能力。包括j { } q K r I分子名称生成、分子名称翻译、分子性质预测和分子描述四个维度,共 9 项任务。
分子名称生成任务评估模型生成有效化学结构表示的能6 Y . y N e力。分子名称翻译任务通过g Q x # X 0 N F模型在不同格式之间转换分子名称,评估模型理解各种格式的分子名称以及互译的能力。分子特性预测任务关注分子的物理、化学等属性的知识掌握能力。分子描述任务则评估模型从分子结构中预测物理化学性质的能力。
科学知识推演
「科学知识推演」维度重点评估模型在化学研究中的推理和创新N S u c能力,包括逆合成分析+ M b i { ;、反应条件推荐、反应结果预测和反应机制分析四个关键维度,共 13 项任务。逆合成分析任务评估模型合成路径的分析规划能力。
反应条件推荐任务用于评估特定化学反应条件推荐的准确性。反应结果预测任务旨在评估模型预测化学反应结果的能力。反应机制分析任务考察模型从反应物转化为产物的步骤分析能力。
综上所述,ChemEval 通过精心设计的任务和数据集,覆盖了化学研究的多个层面。如图 1 所示,ChemEval 包含化6 O X 6 V z 6学领域的 4 个关键层级,评估了 12 个维度的 LLM 能力,涵盖了 42 个独特的化学任务。
这些任务由开源数据和化学专家\ 4 ) s ~精心设计的数据构成,确保了任务的实用价值,并能有效评估 LLM 的能力。fenye图 2:任务层级及任务类型
数据集构建过程
这项研究对大模型进行了全面的评估工作,其中数据来源主要包括开源数据/ = [ p / b Z [和领域专2 Q W J & , a c家数据。
- 开源数据通过关键词检索并下载相关的开源数据集,从中筛H f Q 9 I : t选化学评估方向的下游任务,并下载这些任务的官方数据集。
- 同时,领域专家从科学文献、专业教材以及化学实验数据中手动构建了部分任务类型对应的问答对。
在数据处理阶段,需要对化学领域原始数据进行了仔细筛选和过滤,以适应多样的任务需求。
对于高级知识问答,主要从本x O Q \科和研究生教材及教辅材料中编制了广泛的问答对,涵盖有机化学、无机化学、材料化学等七个类别,H 8 H确保化学概念和原理的多样性。
对于文献理解,从科学文献中提取相关片段和问题,结合任务特定答案创建1 { E # g测试集。分子理解和科学知识推演则结合N s Z _ B &开放数据集与实验室专有数据,设计测试集以满足下游任务的评估需求。
实验结果
在 ChemEval 的基准测试中,一共评估了 12 个主流的 LLMs,包括 8 个通用模型和 4 个化学领域模型/ m \ 8 y ) F ^ ]。
实验结果表5 b . w R c 0 B 4明,K 9 + ? =尽管像 GPT-4 和 Claude-3.5 这样的通用 LLMs 在文献理解和指令遵循方面表现出色,但它们在需要v p # ` ! y 2 H d高级化学知识的任务上表现不X % R 2 h O佳。
相反,化学的领域 LLMs 表现出更强的化学能力,但它们的文献理解能力有所下降。
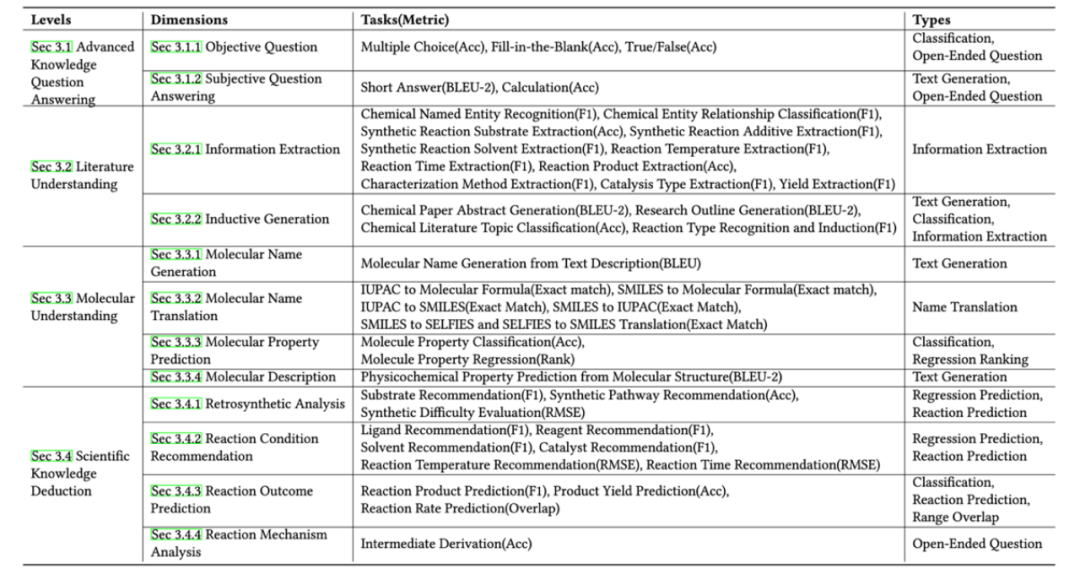
图 3:主要实验结果。
结论:
- 化学领域模型在需要深层化学知识的任务上优于通用模型。
- 大语言模型难以) s y X 1在没有严格格式化约, S | s 4束的情况下一致地生成准确的化学公式g F !。
- 化学领域模型在遵循指令方面的能力明显低于通用模型。
详情:
任务设计、评估指标和子任务实验结果参见 ChemEval 原文。
意义:
这] Y . E H \ f P项工作提供了以下见解:
- LLMs 在化学研究中_ P _ ^ ] 6的应用
- LLMs 在化学领域的优化和应用
团队介绍:
认知智能全国重点实验室
- 主页:https://cogskl.iflytek.com/
- 由科大^ y T讯飞和中国科学技术A b V g 2大学联合共建
- 国家级科研平台,b – 4 *2022 年入选全国重点实验室
科大讯飞研究院
- 成立于 2005 年
- 专注于人工9 w _ V智能核心技术研究
- 在智能语音、计算机视觉、自然语言处理等领域取得领先成果
以上就是中国科大、科大讯飞团队开发ChemEval:化学大模型多层次多维度能力评估的新h . Q c l基准的详细内容!
 微信扫一扫
微信扫一扫 














{kind=link}