AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhi5 N |xin.com;zhaoyunfeng+ p G P@jiqizhixin.com
Sora 的发布让广大研究者及开发者深! d : R \ / 3 Q刻认识到基于 Transformer 架构扩散模型的巨大潜力。作为这一类的代表性工作,DiT 模型u p Q J F * 3 k抛} = ` : ! P ; W I弃了传统的 U-Net 扩散架构,转而使用直筒型去噪模型。鉴于直筒型 DiT 在隐空间生成任务上效果出众,后续的一些工作如 PixArt、SD3 等等也都不约而同地使用了直筒型架构。
然而令人感到不解的是,U-Net 结构是之前最常用的扩散架构,在图像空间和隐空间的生成效果均表现不俗;可以说 U-Net 的 inductive) / m m . bias 在扩散任务上已被6 * V ~ a广泛证实是有效的。因此,北大和华为的研究者们产生了一个疑问:能否重新拾起 U-Net,将 U-Net 架构和r l \ Transformer 有机结合,使扩散模型效果更上一层楼?带着这个问题,他们提出了基于 U-Net 的 DiT 架构 U-DiT。
-
论文: m 6 – Z + 0标题:u-dits: downsample tokens in u-shaped diffusion tranE : B W U } ` vsformers
-
论文地址:https5 l $ F z T G://arxiv.org/pdf/2405.02730
-
GitHub 地址:https://github.com/YuchuanX 5 d &Tian/U-DiT
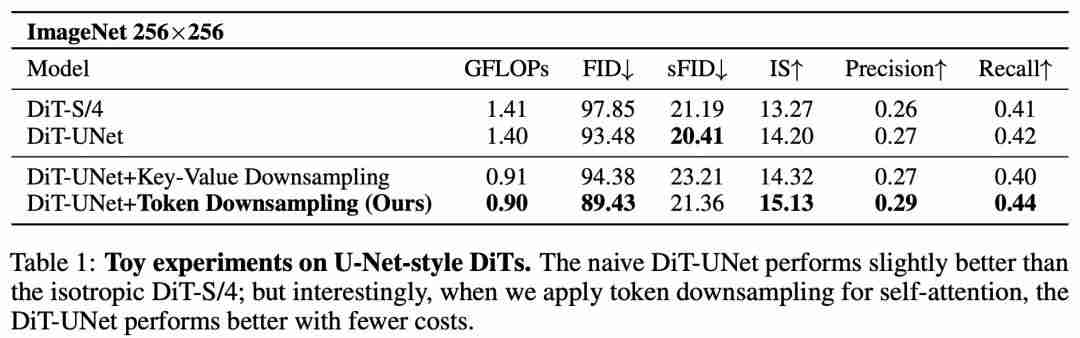
首先,研究者开展了一个小实验,在实验中尝试着将 U-Net 和 DiT 模块简b Q L u E h A单结合。然而,如表 1 所示,在相似的算力比较下,U-Net 的 DiT(DiT-UNet)仅仅比原始的 DiT 有略微的提升。
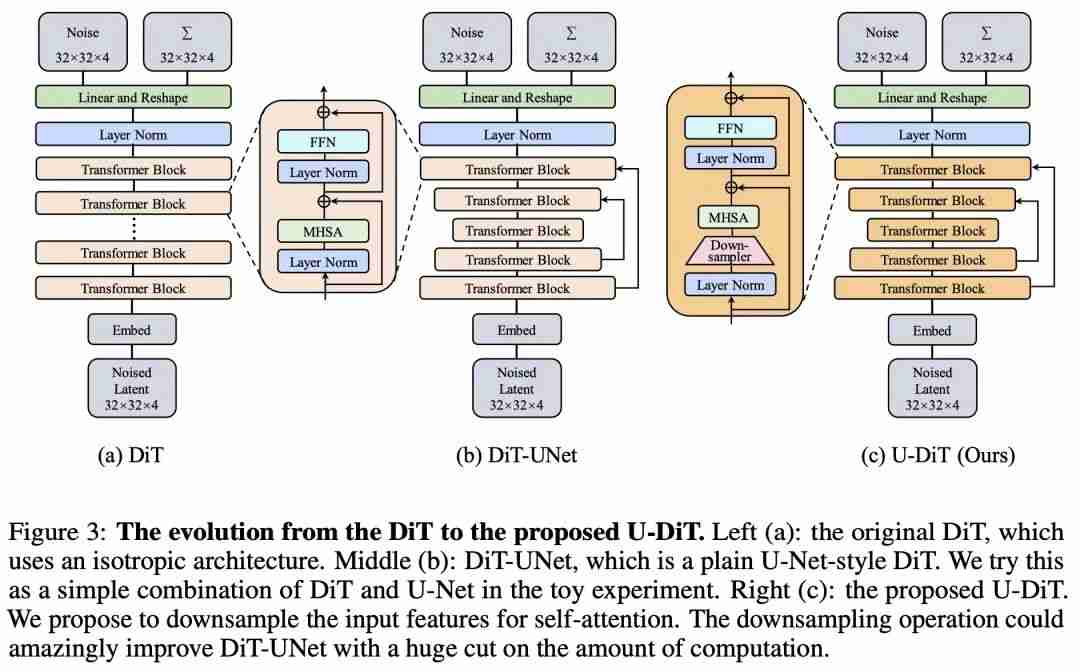
在图 3 中,作者们U y Q [ % Z展示了从原始的直筒 DiT 模型一步步演化到 U-D& 3 Q K q B 9 #iT 模型的过程。
根据先前的工作,在扩散中 U-Net 的主干结构特征图主要为低频信号。由于全局自注意力运算机制需要消耗大量算力,在 U-Net 的主干自注意力架$ f Q I x z构中可能存在冗余。这时作者注意到,简} ! E ~ o ! &单的下采样可以自然地滤除噪声较多的高频,强调信息充沛的低频。既然如此,是否可以通过下采样来消除对特征图自注意力中的冗余?[ ) I # ^
Token 下采样后的n _ v F v m y 6 Z自注意力
由此,作者提出了下采i n 0 a ( A q样自注意力机制。在自注意力之前,首先需将特征图进行 2 倍下采样。为避免重要信息的损失,生成了四个维度完全相同的下采样图,以确保下采样前后Z B L ? P | b的特征总维度相同。随后,在四个特征图上使用共用的 QKV 映H q a @ e 5射,并分别独立进行自注意力运算。最后,将四个 2 倍下采样的特征图重新融为一个完整特征图。和传统的全局自注意力相比,下采样自注意力可以使得自注意力所需算力降低 3/4。
令A q :人惊讶的是,尽管加入下采样操作之后能够显著模型降低所需算力,但是却反而能获得比原来更好的效果(表 1)。
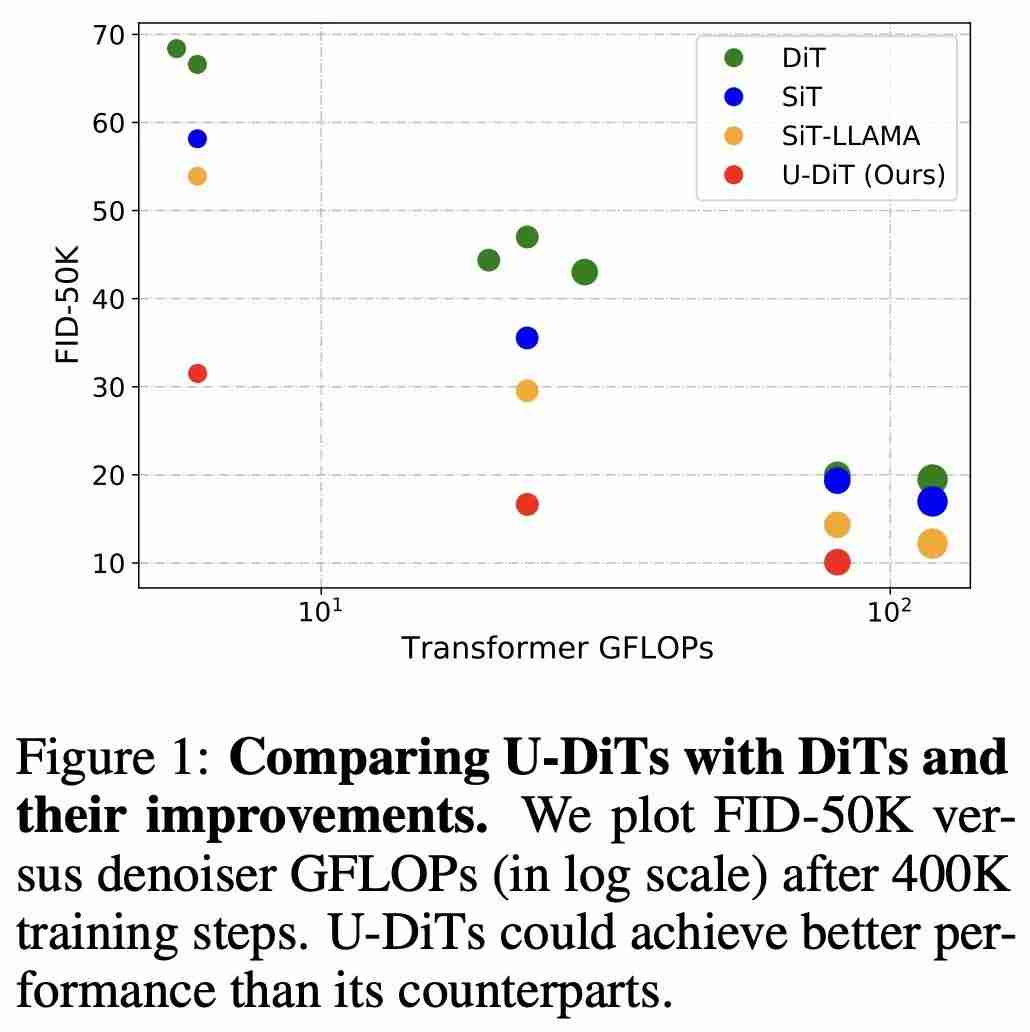
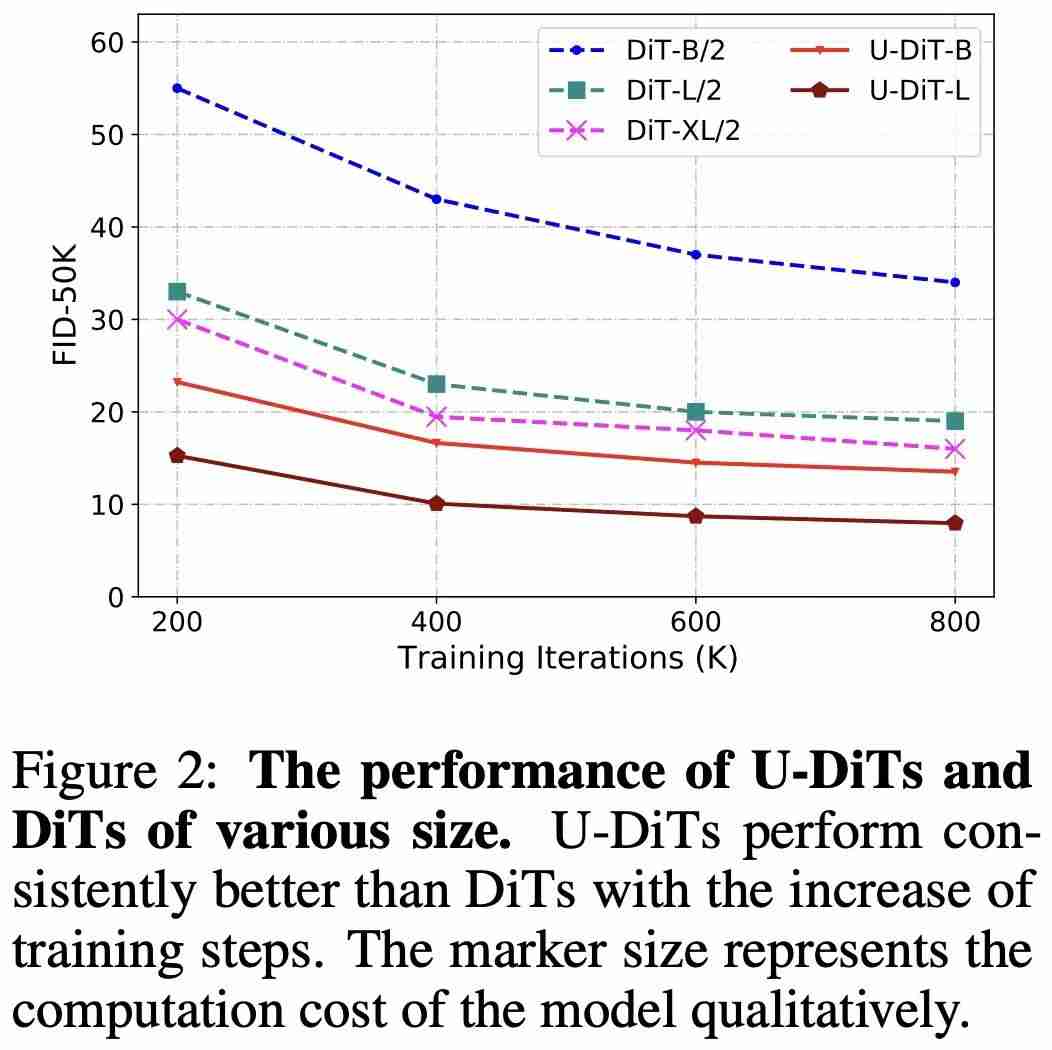
根据此发现,作者提出了基于下采样自注意力机制的 U 型扩散模型 U-DiT。对标 DiT 系列模型的算力,作者提出了三个 U-DiT 模型版本(S/B/L)。在完全相同的训练超参设定下,U-DiT 在 ImageNet 生成任务A i C $ { \上取得了令人惊讶的生成效果。其中,U-i – – 5 L 8 7 , LDiT-L 在 400K6 u b E r u J f 训练迭代下的表现比直筒型 DiT-XL 模型高约 10 FID,U-DiT-S/B 模型比同级直筒型 DiT 模型高约 30 FID;U-DiT-B 模型只需 DiT-XL/2 六分之一的算力便可达到更好的效果(表 2、图 1)。
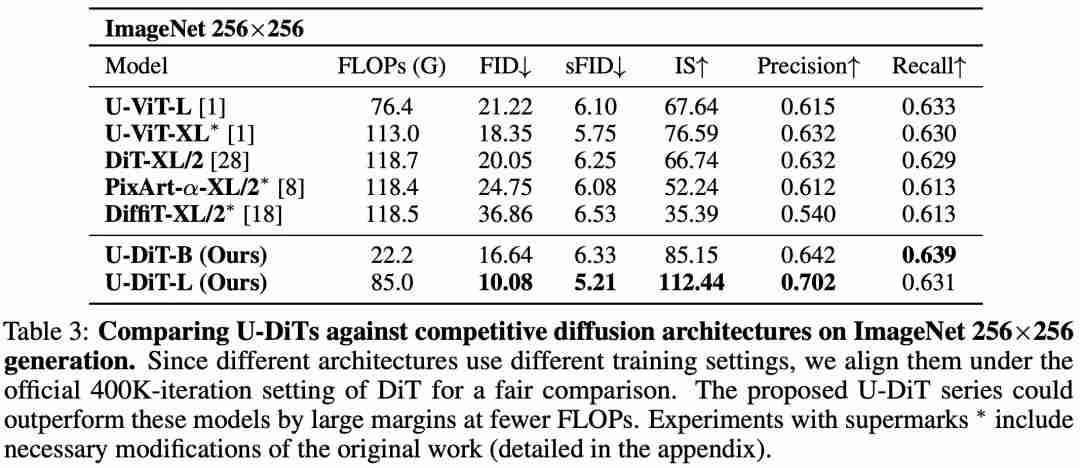
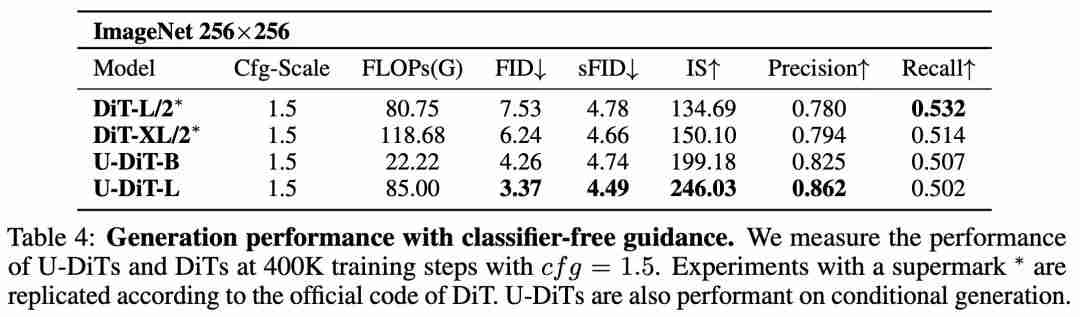
在有条件生成任务(表 3)和大图(512*512)生成任务(表 5)上,U-DiT 模型相比于 DiT 模型的优势同样非常明显。
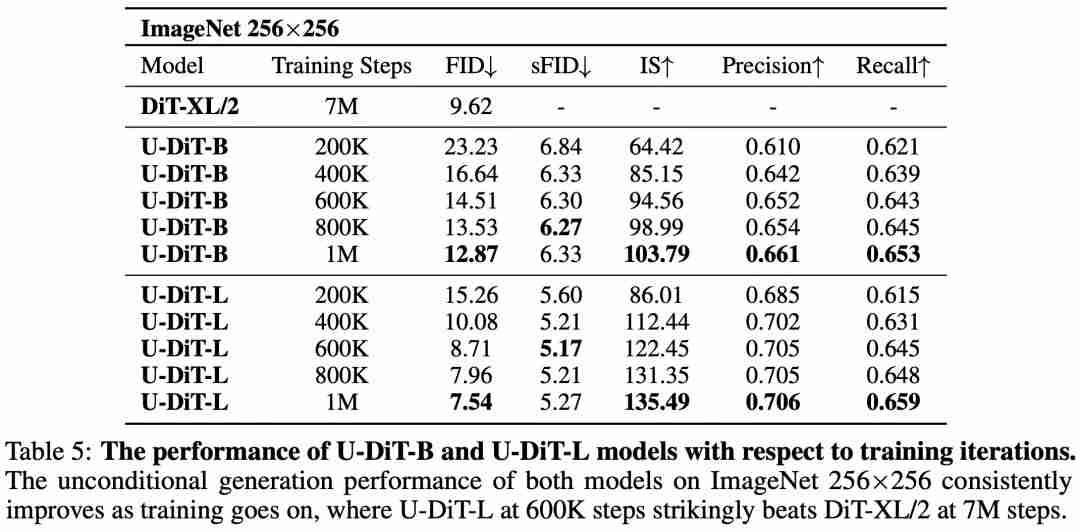
研究者们还进一步延长了训练的迭代次数,发现 U-DiT-L 在 600K 迭代时便能优于 DiT 在F 3 I G G K t . 7M 迭代时的无条件生成效果(表 4、图 2)。
U-DiT 模型的生成效果非常出众r + * ~ z ?,在 1M 次迭代下的有条件生成效果已经非常真实。
论文已被 NeurIPSM j f Z 9 9 2024 接收u U P – +,更多内容,请参考原论文。
以上就是Make U-Nets Great Again!北大&华为提出扩散架构U-DiT,六分之一算力即可超越DiT的详细内容!











 微信扫一扫
微信扫一扫 












{kind=link}