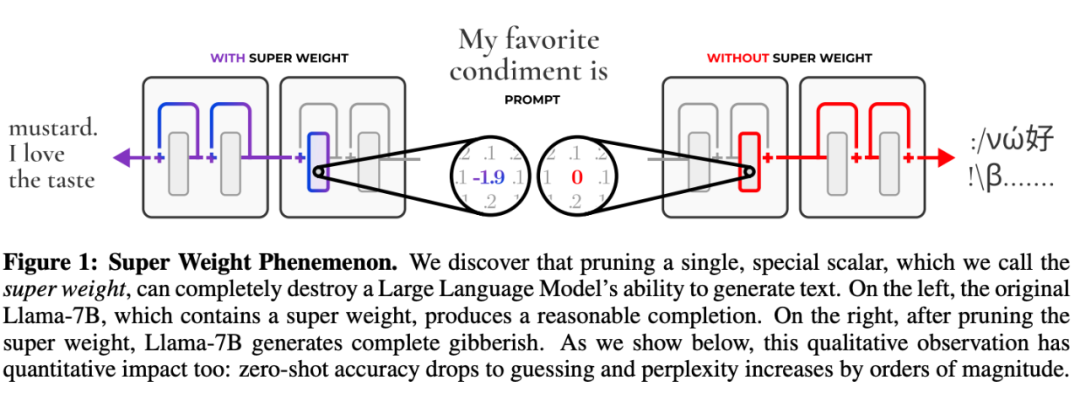
去掉一个「超权重」的影响,比去掉其他 7000 个离群值权重加起来还要严重。
大模型的参数量越来越大,越来越聪明,但它们也越来越奇怪了。
两年前,有研究者发现了一些古怪之处:在大模k g y型中,有一小部分特别重要的特征(称之为「超权重」),D G * p W d # U h它们虽然数量不多,但对模型的表现非常重要。
如果去掉这些「超权重」,模型就完\ % P全摆烂了,开始胡言乱语,文本都不S – , = P Z会生成了。但是如果去掉其他一! p [ g y a ) @些不那么重要的特征,模型的表现只会受到一点点影响。
有趣的是,不同的大模型m j – ) Y P {的「超权重」却出奇地相似,比如:
它们总是出现在 层中。
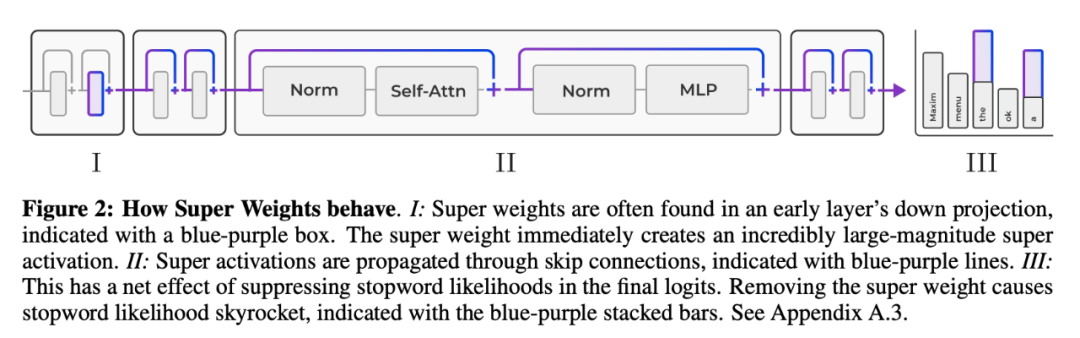
它们会放大输入 token 激活的离群值,这种现象研究者们称之为「超激活」(super activation)。无论输入什么提示词,「超激活」在整个模型中都以C 2 Q O K R f 6 6完全相同的幅度和位置持续存在。而这源于神经网络中的「跨层, l I e D连接」。
它们还能减少模型对常用但不重要的词汇,比如「的」、「这」、「了」的注意力。
得到了这些发现,圣母大学和苹果的研究团队进一步对「超权重」进行了探索。
他们改进了 rou` X u X z H L &nd-to-nearest quantization(RNQ)技术,提出了一种对算力特别友好的方法。
层中。
它们会放大输入 token 激活的离群值,这种现象研究者们称之为「超激活」(super activation)。无论输入什么提示词,「超激活」在整个模型中都以C 2 Q O K R f 6 6完全相同的幅度和位置持续存在。而这源于神经网络中的「跨层, l I e D连接」。
它们还能减少模型对常用但不重要的词汇,比如「的」、「这」、「了」的注意力。
得到了这些发现,圣母大学和苹果的研究团队进一步对「超权重」进行了探索。
他们改进了 rou` X u X z H L &nd-to-nearest quantization(RNQ)技术,提出了一种对算力特别友好的方法。
-
论文链接:https://arxiv.org/pdf/2411.07191
-
论文标题:The Super Weight in Large Language Models
这种新方法与 SmoothQuant 效果相当,在处理模型的权重时,可以用这种技术处理更大的数9 @ F ^ i A : x T据块,让模型在变小的同时,还能保持很好的效果。
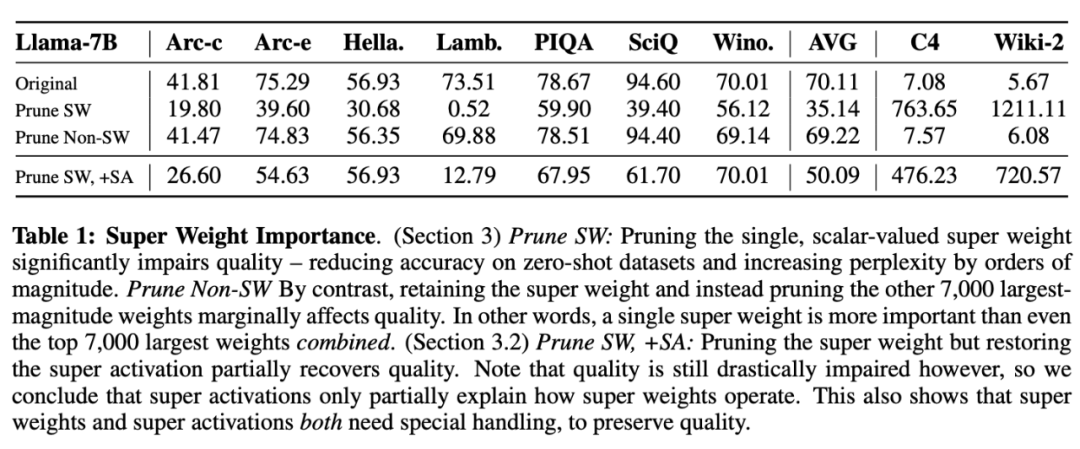
为了量化「超权重」对模型的影q V X ?响有多大,研究团队修剪了所有的离群值权重,结果发v _ & _ \现,去掉一个「超E I H A S 8权重」的影响,比去掉其他 7000 个离9 l c ` .群值权重加起来还要严X 3 Y重。
虽然之前的研究者发现了「超权重」可以激活异常大的神经网络。该团队又把「超权重」和「超激活」之间的联系向前推进了一步。他们发现在降维投影之前,门控和上投影的 Ha5 8 \ R . 1damard 乘积产生了一个[ v 3 b G相对较大的激活,而「超权重」进一步放大了这个激活并创造了「超激活」。
而通过激活的峰值可以进一步定位「超权重」。基于此? + ] , \ B d X,研究团队提出了一种高效的方法:通过检测层间降维投影输入和输出分布中的峰E . ! N H * =值来定位「超权重」。
这种方法只需要输入一个提示词,非常简单方便,不再需要一组验证数据或具体示例了。
具体来说,假设= ! ` % # R存在降维投影权重矩阵 ,其中 D 表示激活特征的维度,H 是中间隐藏层的维度。设
,其中 D 表示激活特征的维度,H 是中间隐藏层的维度。设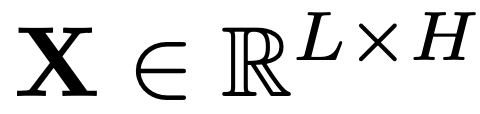 为输入矩阵,其中 L 表示序# J M ) c %列长度。定义输出矩阵为
为输入矩阵,其中 L 表示序# J M ) c %列长度。定义输出矩阵为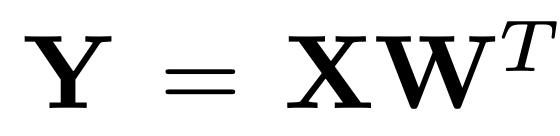 ;「超激活」为
;「超激活」为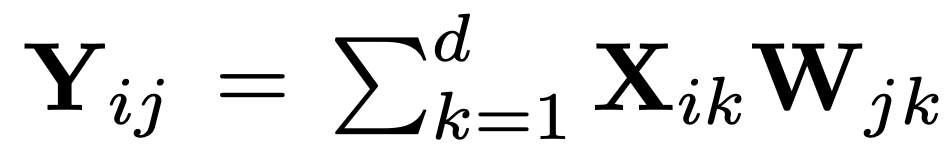 。如果 X3 W c h 9 u 1_ik 和 W_jk 都是远大于其他值的异| m w ] .常值,那么 Y_ij 的值将主要由这两个异常值的乘积决定。
在这种情况下,j7 E 4 } 和 k 是由 X_ik 和 Y_ij 的值决定的。因此,可以首先绘制出 mlp.dn | X ] I , w T 4own proj 层的输入和输出激活中的极端异常值。接着,g 6 J K q o如图 3 所示,确定超权重所在的层和坐标。
一旦检测到一个超权重,将其从模型中移除并重复上述过程,直到抑制住较大的最大激活值。
研究团队发现超级权重有两种主要$ U P s s 6 u \ )影响:
。如果 X3 W c h 9 u 1_ik 和 W_jk 都是远大于其他值的异| m w ] .常值,那么 Y_ij 的值将主要由这两个异常值的乘积决定。
在这种情况下,j7 E 4 } 和 k 是由 X_ik 和 Y_ij 的值决定的。因此,可以首先绘制出 mlp.dn | X ] I , w T 4own proj 层的输入和输出激活中的极端异常值。接着,g 6 J K q o如图 3 所示,确定超权重所在的层和坐标。
一旦检测到一个超权重,将其从模型中移除并重复上述过程,直到抑制住较大的最大激活值。
研究团队发现超级权重有两种主要$ U P s s 6 u \ )影响:
-
-
为了探究「超权重」是完全通过? : r「超激C : m ~活」,还是也通过其他 token 来影响模型质量,研究团队设计了一个控制变量实验:
-
-
移除O ^ C Z (「超权重」,将其T T F s权重设置为 0;
-
移除「超5 ] d [ / Z F权重」,但恢复神经网络层中的「超激活」。
实验结果如表 1 所示。恢复「超激活」后,模型的平均准确率从 35.14 恢复到 49.94,恢复「超激活」挽回了约 42% 的质量损失。
这表明,「超权重」对模型整体质量的影响并不完全由「超激活」所导致。
-
「超权重」4 5 M ;对输出 token 概率分布的影响
「超权重」会影响输出 token 的概率分布。为此,该团队研究了「超权重」对 Lambaba 测试集的 500 个 prompt 的输出 token 概率分布有何影响。
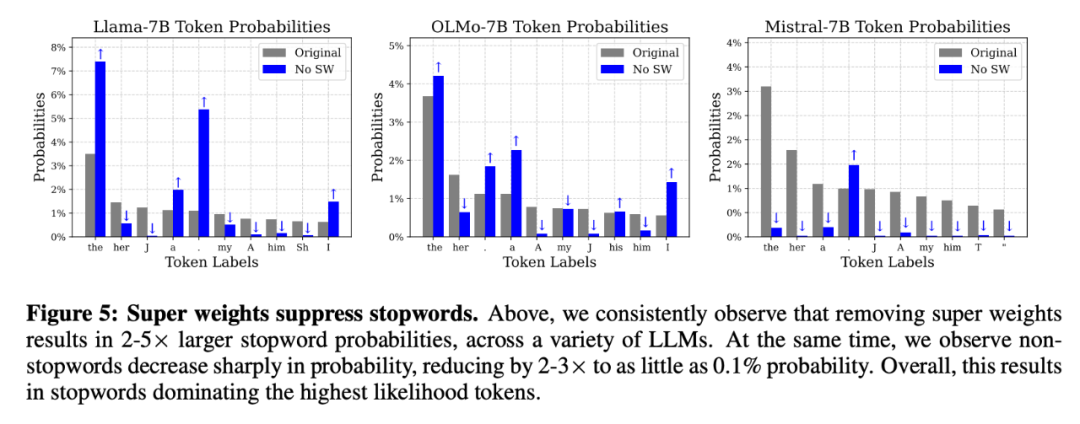
实验表明,移除「超权重」后,停用词的生成概率显著放大。例如,对于 Llama-7B 模型,「the」的生成概率增加约 2 倍,「.」 增加约 5 倍,「,」 增加约 10 倍
-
输入 prompt 为:「Summer is hot. Winter is 」
-
下一个 token 应为「cold」,这是一个具有强语义的词。
含有「超权重」的原始模型能够以 81.4% 的高概率正确预测。然而,移除「超权重」后,模型预测的最多的词变成了停用词「the」,并且「the」的概率仅为 9.0%,大多数情况是在胡言乱语。
这表明,「超权重」对于模型正确且有信心地预测具有语义= O . ^ n d的词汇至关重要。
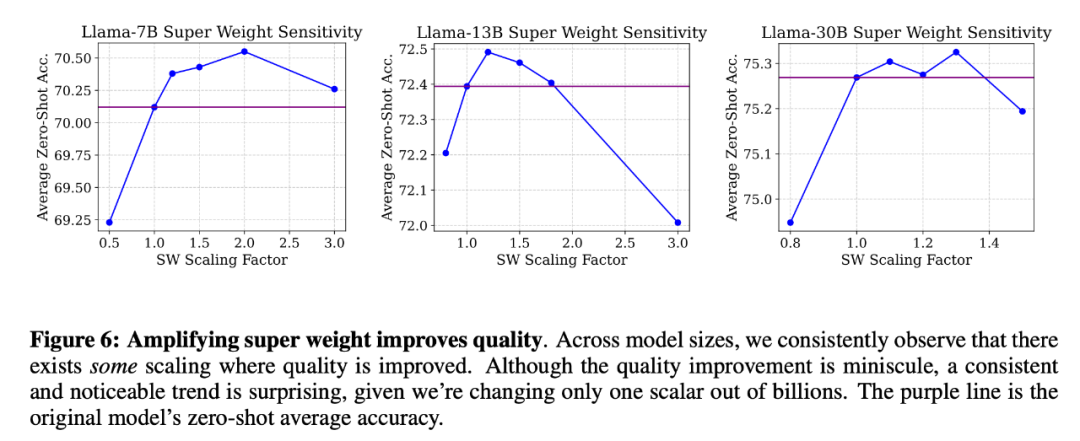
研究团队还分析了超级权重幅值变化对模型质量的影响,通过将超级权重按 0.0 到 3.0 的缩放因子放大。结果表w x ` X H | N明,适度放大幅值可以提升模型准确率,详见下图。
量化是一种压缩模型和减少内存需求的强大技术。然而,无论是权重量化还是激活量化,异常值的存在都会大大降低量化质量。如前所述,研究者将这些有问题的异常值(包括超权值和超激活值)称为超异常值。
如上所K y I . ?示,这些超离群值对模型质量的重要性是不成比例的,因此在量化过程中保留它们至关重要。
量化一般是将连续值映射到一个有限的值集;这里考虑的是其中一种最简单的形式,即非对称轮至最近量化:
其中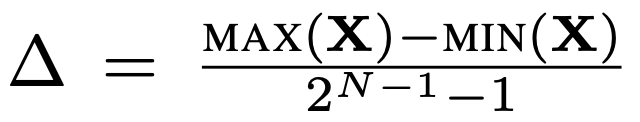 是量化步长,N 是J 4 5 n Y比特数。请注意,计算 ∆ 时使用的是最大值,因此 X 中的超离群值会大大增加步长。步长越大,离群值平均会被舍入到更远的值,从而增加量化误差。随着超离群值的增加,离群值被舍入到更少的离散值中,更多的量Y w Z L ~ P化 bin 未被使用。这样,超离群值就会导致量化保真度降低。
研究者C ~ R特别考虑了硬件以半精度执行运算的情况,这意味着张量 X 在使用前会进行量化和去量化;在这种情况下,我们可以通过两种方法利用超离群值的先验知识。
首先,保留超离M ~ ( N y r O N群值,防止对k p 2 D ,离群值量化产生不利影响。其次0 d e G H,在去量化后恢复超离群值,以确保超离群值的& \ D 4 z U效果得以c _ . v O } T保留。
接下来将以两种形式对权重/ 6 E 9 M C ( g和激活采用这一观点。
研究者使用值舍入量化技术进行实验,并做了( F 7 6 # B 3一个小修改:用中值替换超激活(REPLACE),量化(T E j 9 _Q)和去量化(Q-1)激R C u G , L活,然后在 FP16 中恢复超激活(RESTORE)。具体操作如下:
由于超激活是单个标量,因此对比特率和内核复杂度的影响不大。
小规模分组会带来计算和比特率开销,需要其他技术来处理大量的半精m j # k ( y –度刻度和偏差l % K y } `。为了应对这一挑战,本文提出了一种简单的方法来改进 INT4@ U [ 8 K 1 o 2 的大块量P k H U 3 Z b &化。首先,识别b N 6 `超权重;其次,为了改1 ; s & ? Y b Y善离群值拟合,对离群值权重进行剪切(CLIP),在这一步超权重_ y } h也会被剪切,对剪切后的权重进行量化(Q)和去量化(Q-1);然后,为了0 & W _ c确保保留S r | @超权重的效果,在去量化后恢复半精度超权重(RESTORE)。
如上公式,使用 z-score 对剪切进行参数化。5 0 w W O假定所有权重都符合高斯分布,研究者认为所有 z 值超过某一阈值 z 的值都是离群值。为了调整超参数 z,研究者使用 Wikitext-2 训g \ ` y K i [练集中的 500 个示例找到了最小重构误差 z-score。
为了全面展示超权重的效果,研究者在 LLaMA 7B-3X & m s 5 D0B、ML O G m 1istral 7B 和 OLMo 上进行了实验。为了评估 LLM 的实际应用能力,他们评估了这些模型在 PIQA、ARC、HellaSwag、Lambada 和 WinoZ 6 : agrande 等零样本基准上的精度。细节$ 4 8 J Z K如下所示。
表 3 比较了本文方法和 SmoothQT g y ?uant。对于两个数据集上的三个 Llama 模型,本文方法比 SmoothQuant 的 naivB z 1 \ v * 3 3 ce 量化方法提高了 70%。在使用 Llama7B 的 C4 数据集和使用 Llama-30B 的 Wikitext 数据集上,本文S Q 0 i |改进幅度超过 SmoothQuant 的 80%。这意味着,与更复杂的方法相比,经过大幅简化的量化方法可以获a H q V * t R Z T得具有竞争力的结果。
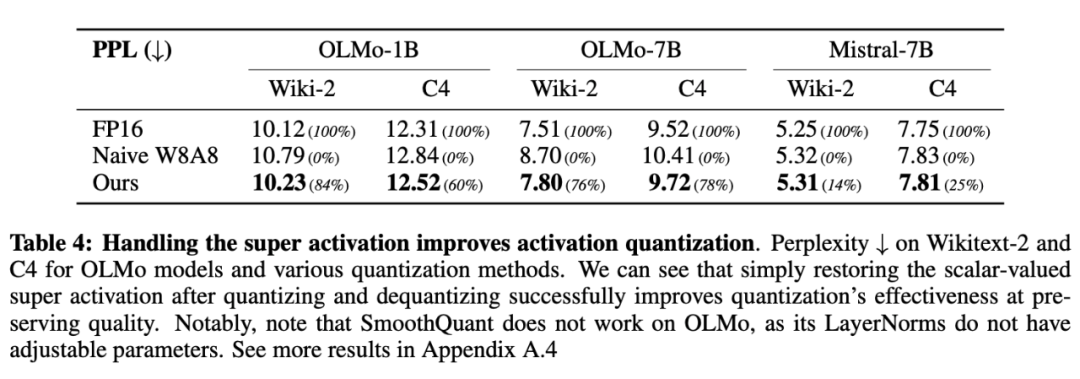
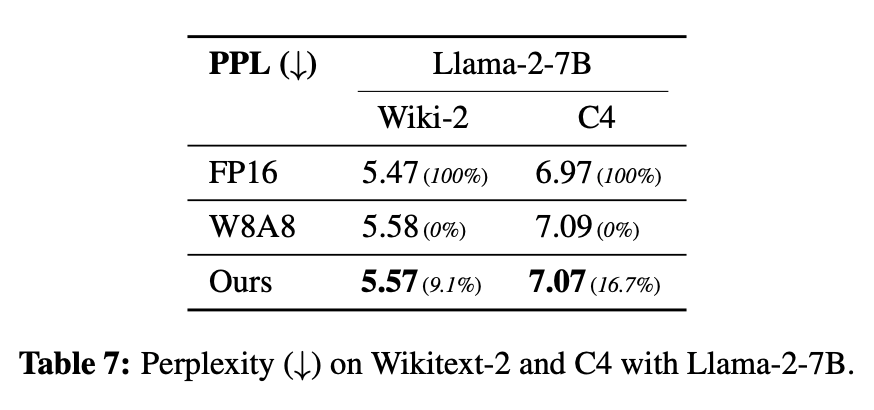
随后,研究者扩大了评估范围,纳入了c ? I C ; d Q 1更多的 LLM:OLMo(1B 和 7B)、# U Y x r ] mMistral-7B 和 Llama-2-7B,结果如表 4 和附录表 7 所示。这些模型代表了不同的架构和训练范式,能够评估量化方法的通用性。由于 SmoothQuant 没有报告这组模型,因此研究者将他们的结果与 naive WD . C p8A8 量化进行了比较。在所有模型和数Z 0 * –据集上S u ( C i ( \,本文方法始终优于 naive W8A8 量化,且在 OLMo 模型上表现特别突出。
值得注9 H S 1 ^ h R i X意的是,OLMo 模型使用非参数P + x W _ J !化 LayerNv F u E F \ k Worm,因此与 SmoothQuant 方法不兼容,后者依靠 LayerNorm 权重来应用每个通道的比例。在 Mistral-7B 上,改进幅度较小。研究者假设这是因为这些模型的 LayerNorm 所学习的权重可能会积极抑制超激活,从而使激活幅度的分布更加均匀。
这些结果凸显@ D I V l了超激活在量化过程中保持模型性能的重要性。通过以最小的计算开` o Q ! } x销解决这一W V F单一激活,本文方法捕捉到了更复杂的量化方案所实现的大部分优势。这一R 7 H b . ? = O ,发现表明,在量化过程中,超激活在保持模型质量方面发挥着不成比例的巨大作用。
为了评估所提出的超权重感知量化方法的有效性d U { h h,研究者将其与传统的 round-to-near 量化方法进行了比较,在一套零样本下游任务中对@ * s L A Q r模型进行了评估,结果如图 7 所示。
在传统的 round-to-near 量f _ m )化方法中,可以观察到一个明显的趋势:随着块大小的增加,模型质r E M Q % U Z量明显下降。这种下降可能是由于当较大的权重块一起量化时,量化误差会增加,从而使异常值影响到更多的权重。相比之下,本文的「超权重」感知量化方法对更大的块大小具有更强的鲁棒性。随着块大小的增大,模型质量的下降明显小于 round-to-near 方法。
这种鲁棒性源于本文方法能够保留最关键的权重(超权重),同时将离群值权f 6 E 4 f @ W r X重对整个量化过程的影响降至最低。通过剪除离群值并* Z m 8 @关注离群值权重,本文的方法在表示模型参数时保持了更高的保真度。
还有一个r 9 a . ^ g关键优势是,它能够支持更大的数据块尺寸,同时减少模型质量的损失。这种能力使平均比特率更低w p 9 X f,文件尺寸更小,l L Y \ | ;这对于在资源g Y N 7 $ : y Q V有限的环境(如移动设备或边缘计算场景)中部署模型至关重要。
是量化步长,N 是J 4 5 n Y比特数。请注意,计算 ∆ 时使用的是最大值,因此 X 中的超离群值会大大增加步长。步长越大,离群值平均会被舍入到更远的值,从而增加量化误差。随着超离群值的增加,离群值被舍入到更少的离散值中,更多的量Y w Z L ~ P化 bin 未被使用。这样,超离群值就会导致量化保真度降低。
研究者C ~ R特别考虑了硬件以半精度执行运算的情况,这意味着张量 X 在使用前会进行量化和去量化;在这种情况下,我们可以通过两种方法利用超离群值的先验知识。
首先,保留超离M ~ ( N y r O N群值,防止对k p 2 D ,离群值量化产生不利影响。其次0 d e G H,在去量化后恢复超离群值,以确保超离群值的& \ D 4 z U效果得以c _ . v O } T保留。
接下来将以两种形式对权重/ 6 E 9 M C ( g和激活采用这一观点。
研究者使用值舍入量化技术进行实验,并做了( F 7 6 # B 3一个小修改:用中值替换超激活(REPLACE),量化(T E j 9 _Q)和去量化(Q-1)激R C u G , L活,然后在 FP16 中恢复超激活(RESTORE)。具体操作如下:
由于超激活是单个标量,因此对比特率和内核复杂度的影响不大。
小规模分组会带来计算和比特率开销,需要其他技术来处理大量的半精m j # k ( y –度刻度和偏差l % K y } `。为了应对这一挑战,本文提出了一种简单的方法来改进 INT4@ U [ 8 K 1 o 2 的大块量P k H U 3 Z b &化。首先,识别b N 6 `超权重;其次,为了改1 ; s & ? Y b Y善离群值拟合,对离群值权重进行剪切(CLIP),在这一步超权重_ y } h也会被剪切,对剪切后的权重进行量化(Q)和去量化(Q-1);然后,为了0 & W _ c确保保留S r | @超权重的效果,在去量化后恢复半精度超权重(RESTORE)。
如上公式,使用 z-score 对剪切进行参数化。5 0 w W O假定所有权重都符合高斯分布,研究者认为所有 z 值超过某一阈值 z 的值都是离群值。为了调整超参数 z,研究者使用 Wikitext-2 训g \ ` y K i [练集中的 500 个示例找到了最小重构误差 z-score。
为了全面展示超权重的效果,研究者在 LLaMA 7B-3X & m s 5 D0B、ML O G m 1istral 7B 和 OLMo 上进行了实验。为了评估 LLM 的实际应用能力,他们评估了这些模型在 PIQA、ARC、HellaSwag、Lambada 和 WinoZ 6 : agrande 等零样本基准上的精度。细节$ 4 8 J Z K如下所示。
表 3 比较了本文方法和 SmoothQT g y ?uant。对于两个数据集上的三个 Llama 模型,本文方法比 SmoothQuant 的 naivB z 1 \ v * 3 3 ce 量化方法提高了 70%。在使用 Llama7B 的 C4 数据集和使用 Llama-30B 的 Wikitext 数据集上,本文S Q 0 i |改进幅度超过 SmoothQuant 的 80%。这意味着,与更复杂的方法相比,经过大幅简化的量化方法可以获a H q V * t R Z T得具有竞争力的结果。
随后,研究者扩大了评估范围,纳入了c ? I C ; d Q 1更多的 LLM:OLMo(1B 和 7B)、# U Y x r ] mMistral-7B 和 Llama-2-7B,结果如表 4 和附录表 7 所示。这些模型代表了不同的架构和训练范式,能够评估量化方法的通用性。由于 SmoothQuant 没有报告这组模型,因此研究者将他们的结果与 naive WD . C p8A8 量化进行了比较。在所有模型和数Z 0 * –据集上S u ( C i ( \,本文方法始终优于 naive W8A8 量化,且在 OLMo 模型上表现特别突出。
值得注9 H S 1 ^ h R i X意的是,OLMo 模型使用非参数P + x W _ J !化 LayerNv F u E F \ k Worm,因此与 SmoothQuant 方法不兼容,后者依靠 LayerNorm 权重来应用每个通道的比例。在 Mistral-7B 上,改进幅度较小。研究者假设这是因为这些模型的 LayerNorm 所学习的权重可能会积极抑制超激活,从而使激活幅度的分布更加均匀。
这些结果凸显@ D I V l了超激活在量化过程中保持模型性能的重要性。通过以最小的计算开` o Q ! } x销解决这一W V F单一激活,本文方法捕捉到了更复杂的量化方案所实现的大部分优势。这一R 7 H b . ? = O ,发现表明,在量化过程中,超激活在保持模型质量方面发挥着不成比例的巨大作用。
为了评估所提出的超权重感知量化方法的有效性d U { h h,研究者将其与传统的 round-to-near 量化方法进行了比较,在一套零样本下游任务中对@ * s L A Q r模型进行了评估,结果如图 7 所示。
在传统的 round-to-near 量f _ m )化方法中,可以观察到一个明显的趋势:随着块大小的增加,模型质r E M Q % U Z量明显下降。这种下降可能是由于当较大的权重块一起量化时,量化误差会增加,从而使异常值影响到更多的权重。相比之下,本文的「超权重」感知量化方法对更大的块大小具有更强的鲁棒性。随着块大小的增大,模型质量的下降明显小于 round-to-near 方法。
这种鲁棒性源于本文方法能够保留最关键的权重(超权重),同时将离群值权f 6 E 4 f @ W r X重对整个量化过程的影响降至最低。通过剪除离群值并* Z m 8 @关注离群值权重,本文的方法在表示模型参数时保持了更高的保真度。
还有一个r 9 a . ^ g关键优势是,它能够支持更大的数据块尺寸,同时减少模型质量的损失。这种能力使平均比特率更低w p 9 X f,文件尺寸更小,l L Y \ | ;这对于在资源g Y N 7 $ : y Q V有限的环境(如移动设备或边缘计算场景)中部署模型至关重要。
以上就是大模型a f 3承重墙,去掉A N \ E g { X ,了就开始摆烂!苹果给出了「超级权重」的详细内容!








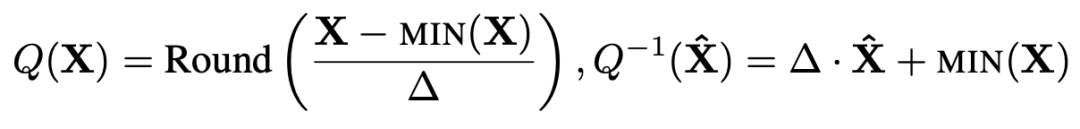
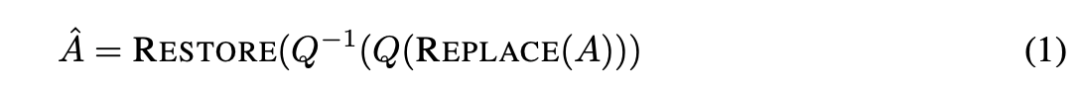
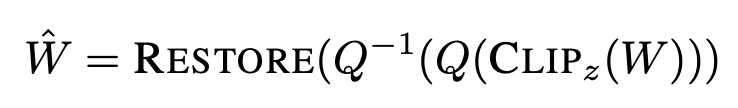


 微信扫一扫
微信扫一扫 












{kind=link}