llama
-
推动大模型自我进化,北理工推出「流星雨计划」
北京理工大学计算机科学与技术学院的direct lab启动了“流星雨”研究计划,旨在探索大模型的自我进化理论与方法。该计划的核心思想源于人类个体能力提升的模式:在掌握基本技能后,通…
-
HuggingFace工程师亲授:如何在Transformer中实现最好的位置编码
一个有效的复杂系统总是从一个有效的简单系统演化而来的。——John Gall 在 Transformer 模型中,位置编码(Positional Encoding) 被用来表示输入…
-
跨模态大升级!少量数据高效微调,LLM教会CLIP玩转复杂文本
在当今多模态领域,clip 模型凭借其卓越的视觉与文本对齐能力,推动了视觉基础模型的发展。clip 通过对大规模图文对的对比学习,将视觉与语言信号嵌入到同一特征空间中, A 6 O…
-
智能体竟能自行组建通信网络,还能自创协议提升通信效率
Hugging Face 上的模型数量已经超过了 100 万。但是几乎每个模型都是孤立的,难以与其它模型沟通。尽管有些研究者甚至娱乐播主试过让 LLM 互相交? & K …
-
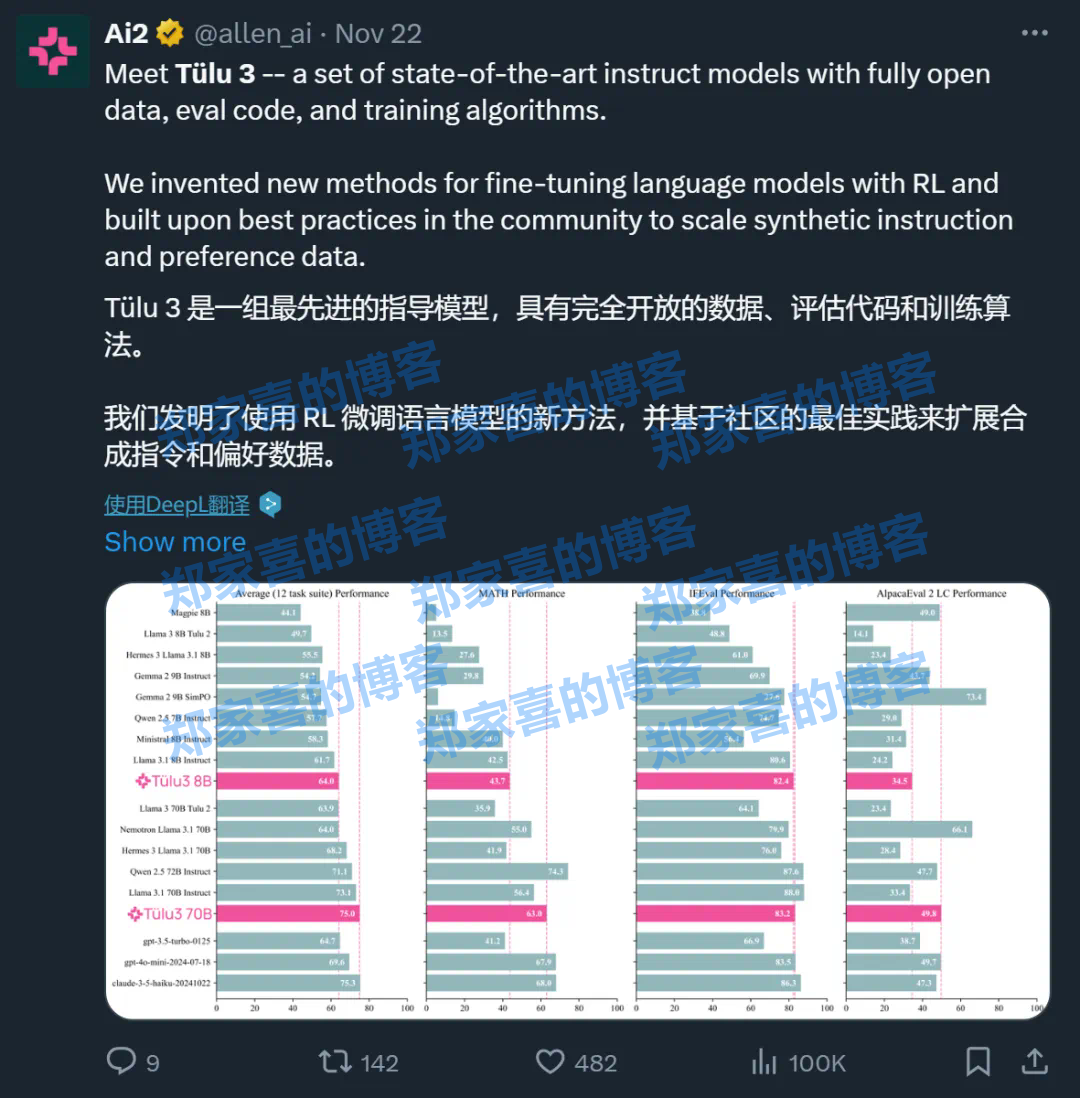
这才是真・开源模型!公开「后训练」一切,性能超越Llama 3.1 Instruct
开源模型阵营又迎来一员猛将:Tlu 3。它来自艾伦人工智能研究所(Ai2),目前包含 8B 和 70B 两个版本(未来还会有 405B 版本),并且其性能超过了 Llama 3.1…
-
上交大o1复现新突破:蒸馏超越原版,警示AI研发"捷径陷阱"
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
阿里云百炼上线百万长文本模型Qwen2.5 -Turbo,百万tokens仅需0.3元
11月20日消息,阿里云推出最新升级的qwen2.5-turbo模型,现已上线百炼平台。这款模型拥有100万超长上下文处理能力,相当于100万个英文单词或150万个汉字,在多项长文…
-
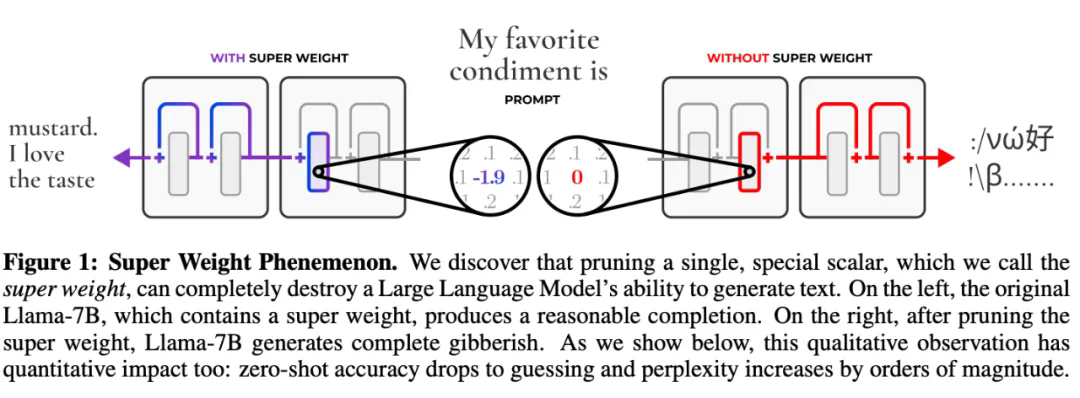
大模型承重墙,去掉了就开始摆烂!苹果给出了「超级权重」
去掉一个「超权重」的影响,比去掉其他 7000 个离群值权重加起来还要严重。 大模型的参数量越来越大,越来越聪明,但它们也越来越奇怪了。 两年前,有研究者发现了一些古怪之处:在大模…
-
突破无规则稀疏计算边界,编译框架CROSS数倍提升模型性能
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
1000多个智能体组成,AI社会模拟器MATRIX-Gen助力大模型自我进化
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。} W + =如…
-
Scaling Laws终结,量化无用,AI大佬都在审视这篇论文
研究表明,你训练的 token 越多,你需要的精度就越高。 最近几天,AI 社区都在讨论同一篇论文。 UCSD 助理教授 Dan Fu 说它指明了大模型量化的方向。 CMU 教授 …
-
调研180多篇论文,这篇综述终于把大模型做算法设计理清了
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果d Y A …
-
NeurIPS 2024 | 真实世界复杂任务,全新基准GTA助力大模型工具调用能力评测
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
LLM 比之前预想的更像人类,竟也能「三省吾身」
子曾经曰过:「见贤思齐焉,见不贤而内自省也。」自省可以帮助我们更好地认识自身和反思世界,对 ai 来说也同样如此吗? 近日,一个多机构联合团队证实了这一点。他们的研究表明,语言模型…
-
大模型已过时,小模型SLM才是未来?苹果正在研究这个
手机还是更适合小模型 大模型虽然好,但我的笔记本和手机都跑不动呀。就算勉强能跑起来,也是奇慢无比。而与此同时,对适合移动和边缘设备的小模型的需求却在不断增长,因为这些模型似乎才能真…
-
国产最强语音大模型诞生,MaskGCT宣布开源,声音效果媲美人类
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
MIT韩松团队长上下文LLM推理高效框架DuoAttention:单GPU实现330万Token上下文推理
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进1 L = 9 9 H Q 2了学…
-
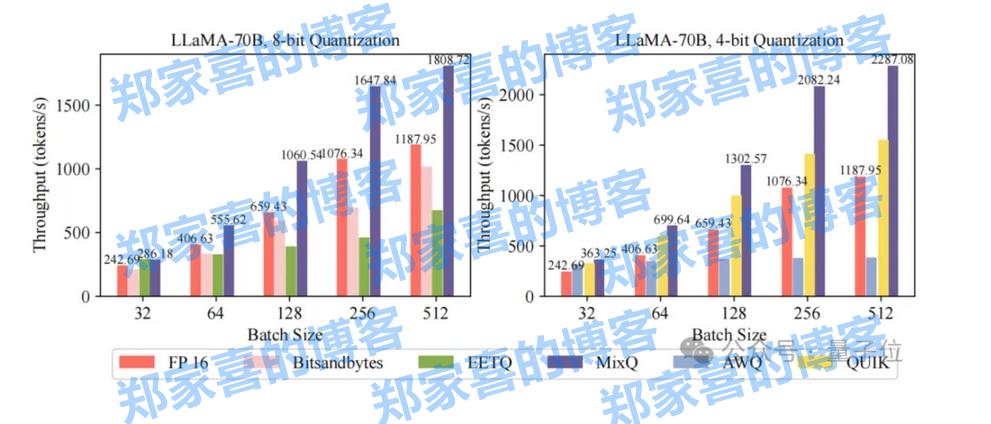
清华开源混合精度推理系统MixQ,实现大模型近无损量化并提升推理吞吐
一键部署llm混合精度推理,端到端吞吐比awq最大提升6倍! 清华大学计算机系PACMAN实验室发布开源混合精度推理系统——MixQ。 MixQ支持8比特和4比特混合精度推理,可实…
-
NeurIPS 2024 | 解锁大模型知识记忆编辑的新路径,浙大用「WISE」对抗幻觉
aixiv专栏是本站发布学术、技术内容的栏目。过去数年,本站aixiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
补齐Transformer规划短板又不放弃快速思考,田渊栋团队的Dualformer融合System 1和2双重优势
一个 token 就能控制模型快些解答或慢点思考。 OpenAI 1 模型的发布掀起了人们对 AI 推理过程的关注,甚至让现在的 AI 行业开始放弃卷越来越大的模型,而是开始针对推…
-
北大林宙辰团队全新混合序列建模架构MixCon:性能远超Mamba
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
微调大模型,AMD MI300X就够了!跟着这篇博客微调Llama 3.1 405B,效果媲美H100
随着 AI 模型的参数量越来越大,对算力的需求也水涨船高。 比如最近,Llama-3.1 登上了最强开源大模型的宝座,但超大杯 405B 版本的内存就高达 900 多 GB,这对算…
-
NeurIPS 2024 | 大模型的词表大小,同样适用于Scaling Law
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有w ( …











{kind=link}