






租用 H100 的钱只需 233 美元。

-
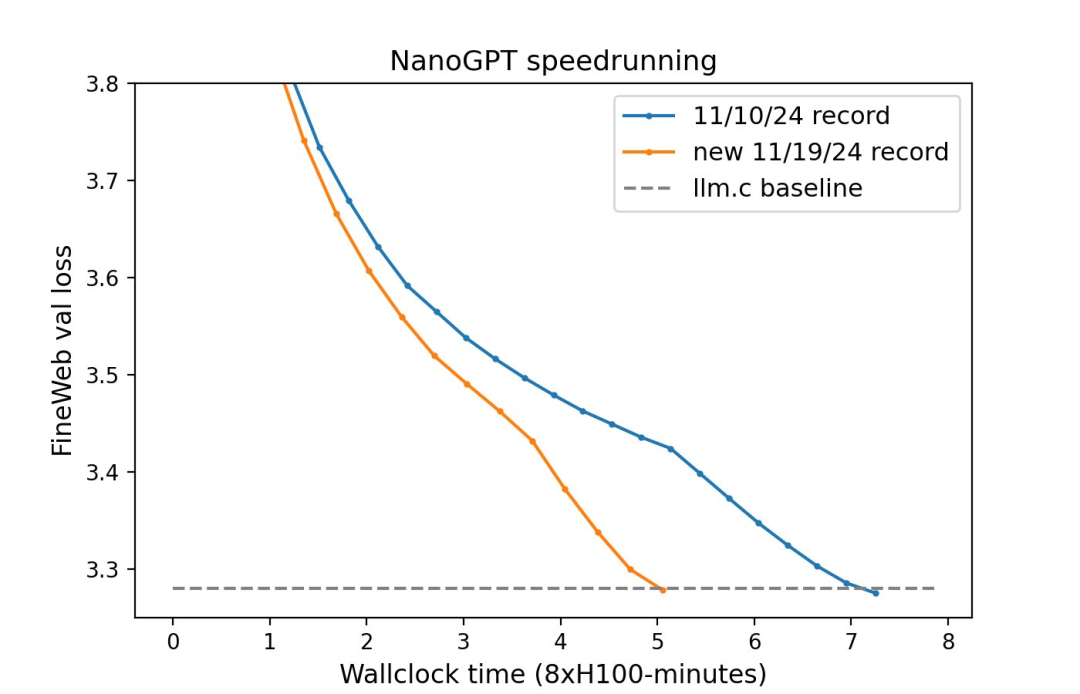
10B tokens–>1B tokens -
8xH100 上花 45 分钟训练 –>8xH100 上花 5 分钟训练
-
先进的架构:旋转嵌入、QKC D a ( @ _-Norm 和 Re W p J 9 ReLU^2; -
新优化器:Muon; -
嵌入中的 Untied Head; -
投影和分类层初始化为零(muP-like); -
架构 shortcut:值残差和嵌入 shortcut(部分遵循论文《X L g } o v u ,Value Residual Learning For Alleviating Att^ 7 Z ; M ( ` & Sention Concentration In` Z X T \ Transformers》); -
动量(Momentum)warmup; -
Tanh soft logit capping(遵循 Gemma 2); -
Fl{ t ` O ~exAttention。
<section>pip install -r requirements.txt</section><section>pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu124 —upgrade # install torch 2.6.0</section><section>python data/cached_fineweb10B.py 10 # downloads only the first 1.0B training tokens to save time</section><section>./run.sh</section>
登录后复制
<section>sudo apt-get update</section><section>sudo apt-get install vim tmux python3-pip python-is-python3 -y</section><section>git clone <a href="https://www.php.cn/link/e8cb5f581442030021d62fd780fa674d" rel="nofollow" target="_blank">https://www.php.cn/link/e8cb5f581442030021d62fd780fa674d</a></section><section>cd modded-nanogpt</section><section>tmuxpip install numpy==1.23.5 huggingface-hub tqdm</section><section>pip install --upgrade torch &</section><section>python data/cached_fineweb10B.py 18</section>
登录后复制
<section>sudo docker build -t modded-nanogpt .</section><section>sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt python data/cached_fineweb10B.py 18</section><section>sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt sh run.sh</section>
登录后复制


<section>@torch.compile</section><section>def zeroth_power_via_newtonschulz5 (G, steps=5, eps=1e-7):</section><section>assert len (G.shape) == 2</section><section>a, b, c = (3.4445, -4.7750,2.0315)</section><section>X = G.bfloat16 () / (G.norm () + eps)</section><section>if G.size (0) > G.size (1):</section><section>X = X.T</section><section>for _ in range (steps):</section><section>A = X @ X.T</section><section>B = b * A + c * A @ A</section><section>X = a * X + B @ X</section><section>if G.size (0) > G.size (1):</section><section>X = X.T</section><section> return X.to (G.dtype)</section>
登录后复制
-
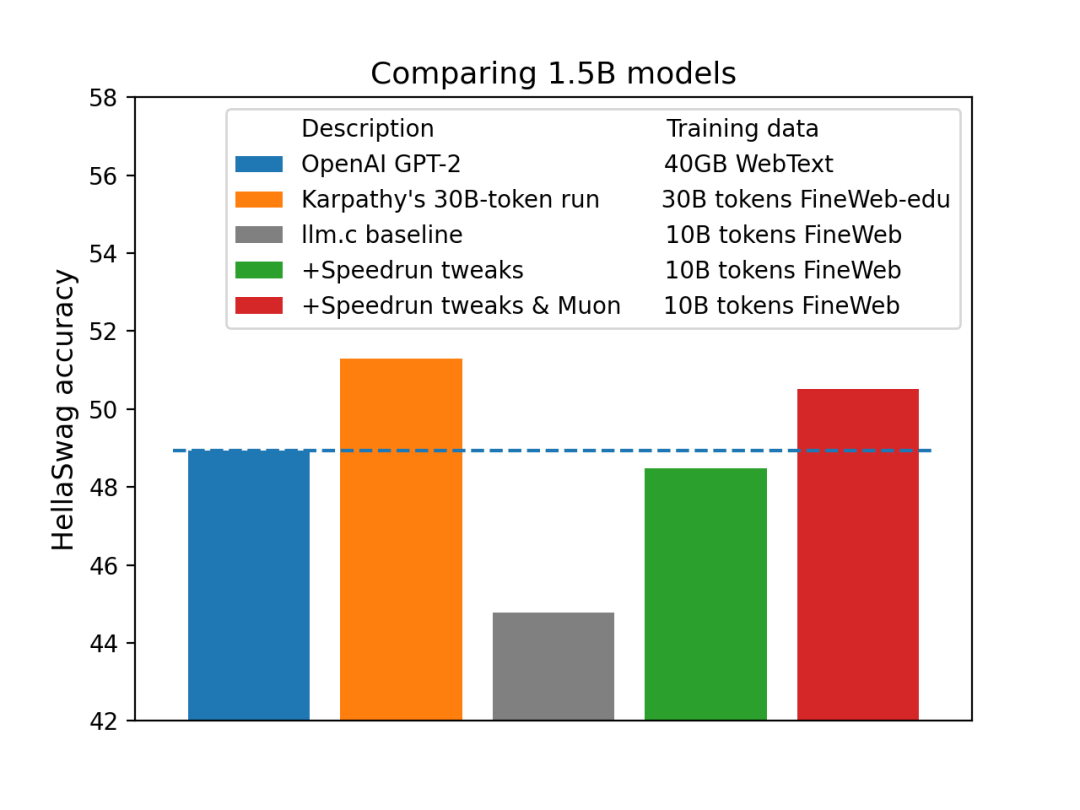
内存* S ] N Q L % 3使用量比 Adam 低 -
采样效率提高约 1.5 倍 -
挂钟开销小于 2B X e ] H f ) d%
-
在更新中使用 Nesterov 动量,在动量之后应用正交化。 -
使用特定的五次 Ne0 C : . N = { / xwton-Schulz 迭代作为正交化方法。 -
使用五次多项式的非收敛系数以最大化零处的斜率,从而最小化必要的 Newton-Schulz 迭代次数。事实证明,方差实际上并不那么重要,因此我们最终得到一个五次多项式,它在重复Z U \ r d应用后(快速)收敛到 0.68、1.13 的范围,而不是到 1。 -
在 bfloat16 中运行 Newton-Schul3 ~ ) # Wz 迭代(而 Shampoo 实现通常依赖于在 fp32 或 fp64 中运行的逆 pth 根)。
以上就是神级项目训练GPT-2仅需5分钟,Andrej Karpathy都点赞的详细内容!
 微信扫一扫
微信扫一扫 













{kind=link}