
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
在 AI 领域,近期的新闻焦点无疑是关于「Scaling Law 是否撞墙?」的辩[ l H e论。这一曾经被视作9 6 ( & F 0 { 1大模型发展的第一性原理,如今却遭遇了挑战。在这样的背景下,研究人员开始意– u + n \ ` ~识到,与其单纯堆砌更多的训练算力和数据资源,不如让模型「花更多时间思考」。以 OpenAI 推出的 o1 模型为例,通过增加推理时间,这种方法让模型能够进行反思、批评、回溯和纠正,大幅提升了推理表现。
但问题在于,传统的自我反思(Self-Reflection)和自我纠正(Self-CorrectO ( ^ } D . g &ion)方法存在明显局限 —— 模型的表现往往受制于自身能力,缺乏外部信号的引导,因此容f L 7 n ? a W易触及瓶颈,止步不前。
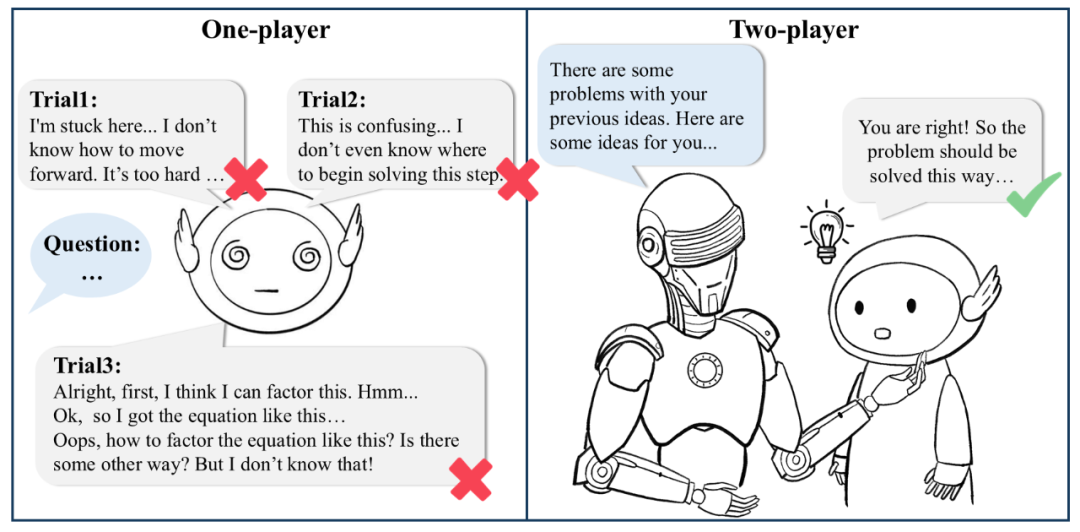
单一模型在传统自我纠正与自我优化时往往难以纠正自: t p \ c身,而双模型协作架构下能够获得更有建设性的建议。
针对这些挑战,B W ~ k t [复旦j * w 7 C NLP 研究团队提出了一种全新的双模型协作架构(Two-Player Paradigm)。简单来说,就是让评判模型(Critique ModY U g ! ^ |el)参与到行为模型(Ak ; &ctor Model+ \ 0 – ? ` Y x w)的推理过程中 —— 行为模型Q _ X x T – L *专注推理,评判模型则以步骤级别的反馈为行为模型: ] # P ~ f i指路。
这种设计打破了传统依赖于单一模型的限制,也让行为模型能够在训练和推理阶段实现自我改进。更重要的是,整个框架无需依赖模型蒸馏过程(例如直接模仿 o1 的思考过程),而是通过多模型协作互动获得了高质量、可靠} o ! C 3 – +的反馈信号,最终实现性能随计算投增大的不断提升。
-
如何自动化构建 critique 数据集,训练高效、可靠的评判模型(Critique Model);
-
使用评判模型推动测试i h B W [ ; G Z S阶段的扩展(Test-time Scaling);
-
通过交互协作提升行为模型的训练性能(Training-time Scaling);
-
基于 critique 数据的 Self-talk 帮助模型自我纠错。
作者们提出了一个创新性框架 ——AutoMathCritique,可以自动生成步骤级别的反馈(step-levelK } L E z D * feedbackE D Q $ [ { :),并基于此构建了名为 MathCritiqueW M 4-76kI x E j e F F 的数据集,用于训练评判模型。进一步,研究团队深入探讨了评判模型在测试阶段助力推理性能的机制,并通过引入双模型协作架构 Cr0 E c { Z J ^ l uitique-in-the-Loop,有效缓解了模型探索与学习的自训练过程中常见的0 B & & X 1 O长尾分布问题,为B 0 9 0 ; \ o W )复现 OG = 5 = ~ a VpenAI o1 深度推理表现开辟了新的可能性。
-
论文题目:Enhancing LLM Reasoning viA \ 9 m F N } i =a Critique Models with Test-Time and Training-Time Supervision
-
论文地址:http://au C m ] ~ X vrxiv.org/abs/2411.16579
-
-
代码仓库:h4 Q j Y @ k W .ttps://git2 t 5 D 3hub.com/WooooDyy/MathCritiq0 t ` s 8 7 M P aue
-
数据仓库:https://huggingface.co/datasets/MathCritique/L I u a *MathCr[ q D ^itique-76k
-
自动化、可扩展地构造步骤级 Critique 数据
为了研究 Critique 模型在架构中的作用与性能,作者们首先训练了一个可# B F靠的 Critique 模型。鉴于步骤级别反馈数据的[ q h M _ h h稀缺,作者们提出了一种新的框架 AutoMathCritique,用于自动化构造多样性推理数据,并获得步骤级别的反馈。
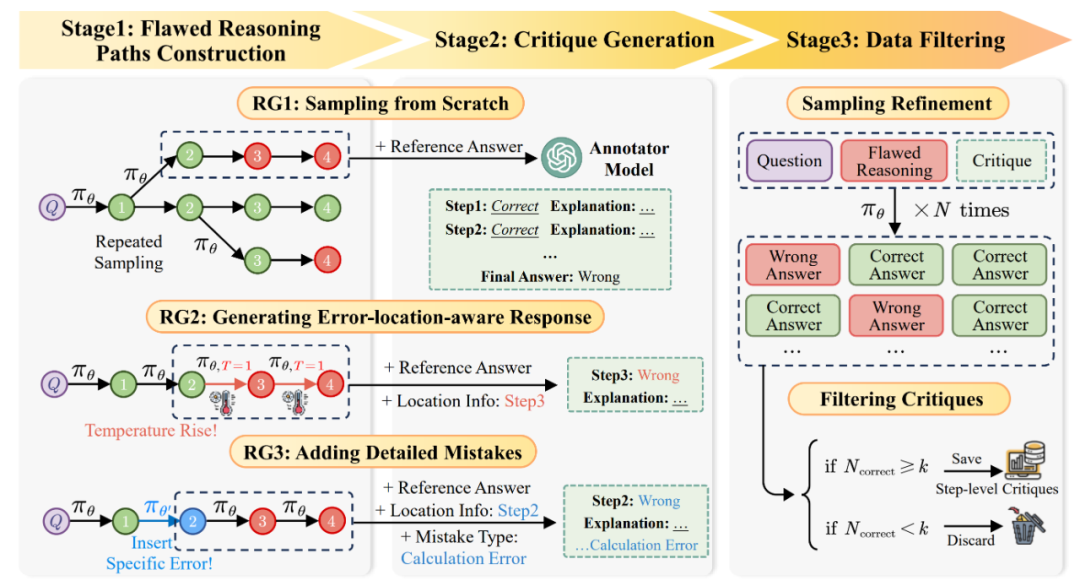
AutoMathCritique 流程:通过多: @ j J !种方式收集错误数据与错误信息,并交由标注模型进行步骤级别标注。在标注完相应问答反馈对后,交由 Actor 模型进行进一步筛选。
图中,第一个阶段「构建错误推理路径」包含三种策略:
-
RG1l S D ^ m K: 直接构建整体推理路径,在高温度@ P Y 2 * 5下让 Actor 模型进行重复采样,采样出的数据只会包含最终答案的错误( M X ? ? q I信息;
-
RG2: 以某一条推理路径为模板,在特定的推理步后逐渐提高温度,让 Actor 模型r 1 x采样出新的轨迹,采样出的数据会包含J 1 m ? ^ =最终答案的) + [ o T + C错误信息与错误步骤的位置信息;
-
RG3: 以某一条推理路径为模板,对特定的推理步插入多样化错误内容,让 Actor 模L Q b D [型继续采样出完整轨迹,采样出的数据会包含最终答b d H案_ ^ 5 \的错误信息与错误步骤的位置与错误信息。
第二个阶C w = %段「标注步骤级别反馈」提供了详细的反馈数据:为了更好的提升反馈数据的质量,研究人y } S E员将; ` V E A D % H k第一阶段获得的各类错误信息交由标注模型,并提供参考答案、错位定位和错误类型信息作为辅助,帮助标注模型提供步骤级别5 1 @ S C f的反馈。
第三个阶段「精筛反馈」筛选出更加高质量的数据:为了进一步筛z ! Y f N P选出能够更好帮助 Actor 模型的数据,研究人员将错误推理路Q N | ` ~ 4 s径与反馈数s + I – ~据一起输入给 Actor 模型,根据其} 6 – Z \ Z u } E修改后答案的正确率决定是否保留。
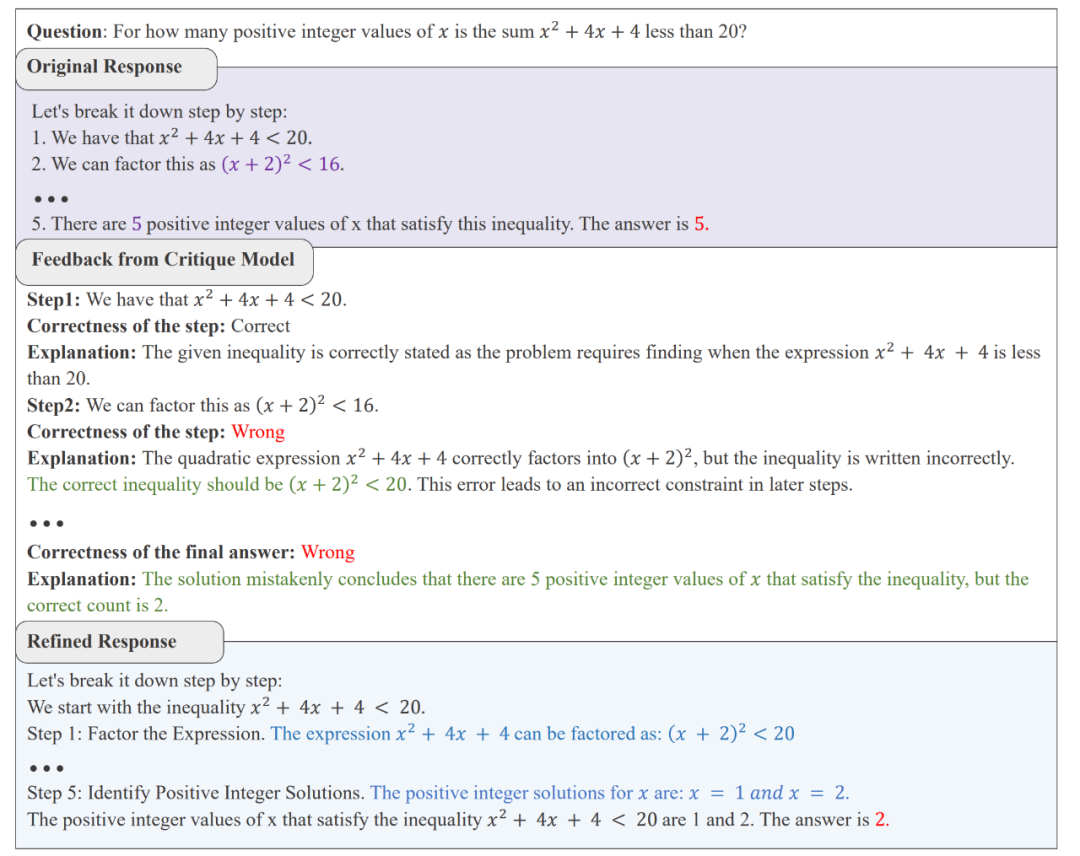
AutoMathCritique 收集到的信息示例
通过如上方案构建的数据既包含模型本身所可能犯下的错误,又构建了域外错误,使 Critique 模型能够学习大批量、多样化错误数据。而步骤级别的反馈数据使得 Actor 模型能够更好的定位自己所犯下的错误,进而提升修改的质量。
使用如上框架,研究团队构建了一个拥有 76k 数据量的数据集/ 4 3 d z u 3 . ` MathCritique-76k,其中既包含了正确推理轨迹又包含了自动化合成的错误轨迹,并且筛选了优质的U S r步骤级别反馈数据用于之后的训练。
Critique 模型如何帮助 Actor 模型提高测试性能?
实验% N E a Z探究:Critique 模型在测试时对 Actor 模型的帮助
基于如上构建的数u R Q 1 p n Y据集,作者以 Llama3-Instruct 系列为基座模型,微调了一个专门用于提供s $ R I Q – S b ]步骤级别反馈的 Critique 模型。其选取了常用的数l a G g \学推理数据集 GSM8p ( 9 N 9 e ] bK 与 MATH 为测试对象,进行了多种实验。
1. CritN w l 5 r E / 1 mique 模型对错误的O l 9 u W A S J g识别率与对 Actor 模型的帮助
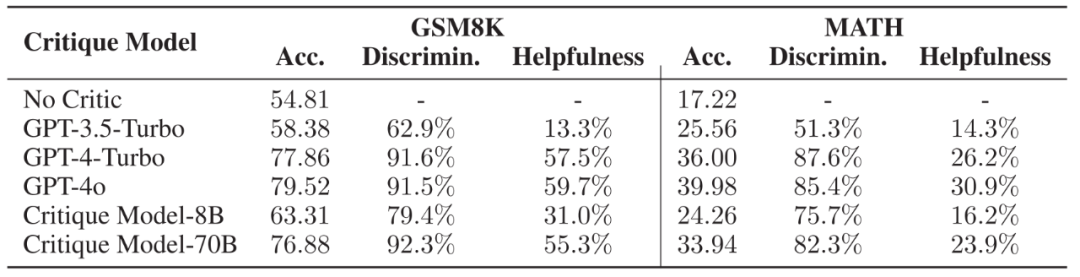 不同 Critique 模[ L – o b Z Q型的推理轨迹正误判断能力与对 Acto: q [ – Gr 模型的帮助,Acc. 代表 Actor 模型在不同 Critique 模型的帮助下能够达到的正确率9 L a 9。
不同 Critique 模[ L – o b Z Q型的推理轨迹正误判断能力与对 Acto: q [ – Gr 模型的帮助,Acc. 代表 Actor 模型在不同 Critique 模型的帮助下能够达到的正确率9 L a 9。
作者选取了两个微调后的模型与 SOTA 模型作为研究对象,发现 Critique 模型能够极为有效地识别出推理轨迹的正确与否,并$ * s T b 0 [ @且其所提供的步骤级别反馈能够被 Actor 模$ c { N ` }型所用,使得 Actor 模型能够显著改进自己的错r s K r k W r $误,以达到更高的正确率。
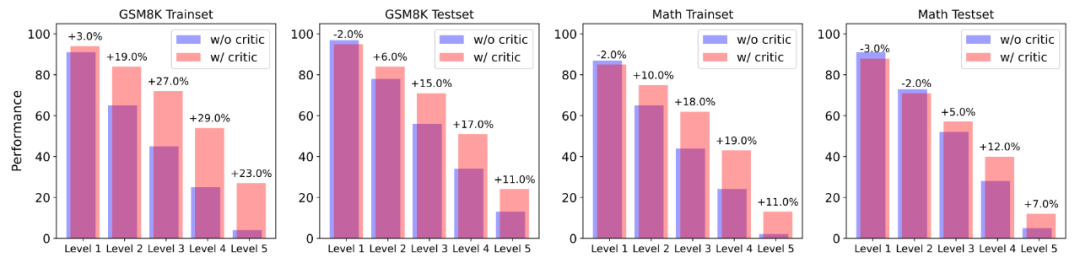
为了更进一步探究 Actor 模型是如何受到帮助的,作者将数据集按照 Actor 模型初始的正确率分为了 5 个难度,并且比较在不同难度下,有无反馈数据对模型回答正确率的影响。
以 Actor 模型正确率(采样 100 次)作为难度分级的指标,使用 Critique 模型的反馈数据能在更高难度题目下获得更大的帮助。
研究发现 Actor 模型在几乎各个难度下,^ o , J m I 5 e正确率均有所提升。而且在难度级别较高的题目中,Actor 模型均收到了更大的帮助,表现为正确率的显著提升。这说明,使用 Critique 模型帮助 Actor 模型改进其所不会的难题,可以是解决自我提升长尾分布难y A j z U题的新方法。
2. 在 Critique 模型帮助下增加推理计算投入的性能
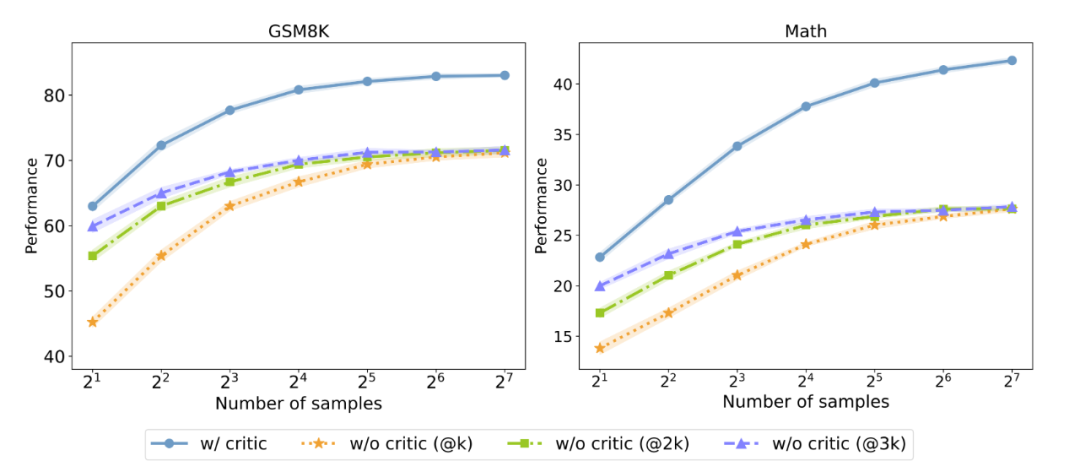
有! K @ c n ) p无反馈数据对测试时 Majority voting 性能的影响,@3K 代表采样数量为横坐标的三倍,以控制采样消耗相同。
研究人员进一步探究 Critique 模型能否在测试时提高 Ak & ~ *ctor 模型性能` I G H a e c。他们以并行 Majority voting 的结果作为测试指标,发现即使在控制了相同的采样消耗的情况下,拥有反馈数据依旧能够2 v a 6 s U Y显著超过没有反馈数据的 Actor 模型。这\ ( | S说明,加入 Critique 模型可以作为实现 Test-time Scaling 的新方法之一。
Crim p U s ~ W 5 C 8tique 模型如何帮助 Actor 模型探索与学习?
基于以上在 Test-time 的发现,研究人员将# r 2 7 _ @测试阶段所展现出来的优势用于训练阶段(Training-time)的探索与学习(Exploration & Learning),进一步探究 Critique 模. 5 M U p型能否帮助 Actor 模型在训练时进行自我优化。为此,他们提出了一个有难度感知的双模型协作优化架构Critique-in-the-x U @ yloop Self-Improvement,用于获得更高质量、多样化的数据,并缓J – J E o 5解自我优化采样时的长尾难题。
Cri! M } ? J V v Rtique-in-the-loop Self-Improvement:有难度感知的双模型协作优化架构
Critique-in-the-loop Self-Improvement 算法伪代码
研究人员提出了一种双模型协作优化架构。在第一次采样时,Actor 模型会在训练集上重复多次采样。针对错误数据7 C 4 k ^ g V,研究人员使用 Critique 模型辅助 Actor 模型进行% D 6 m s a多次自我修正,从而达到了难度感知的目的。每一轮迭代时,Actor 模型总会学习正确的数据,从而实现自我提升。
实验探究:Critique 模型在训练时[ \ 9 + i 0 5 b对模型性能的影响
1. Critique-in-the-loop 能够有效帮助模型自我提升
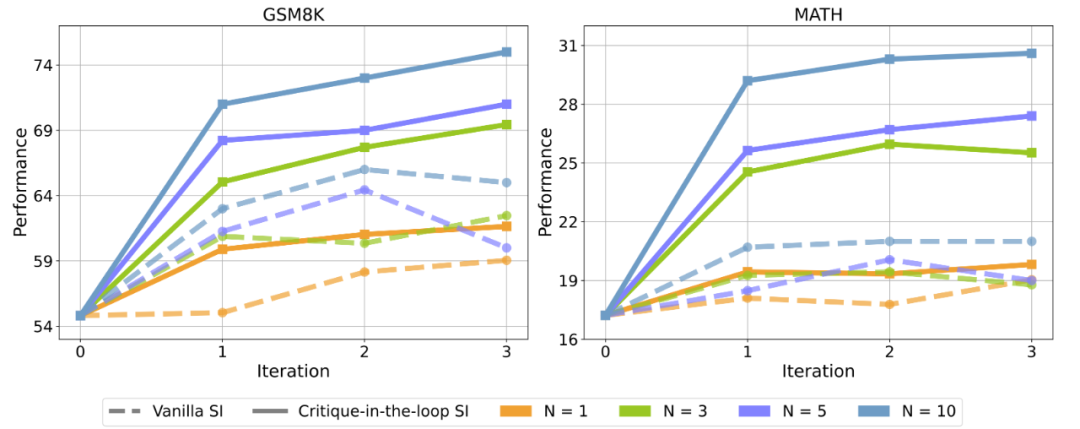
相比于在训练阶段只使用 Actor 模型D Z ; @ d @ G @ #进行采样(Vanilla SI), 使用 Critique 模型后,Actor 模型在测试集正确率上均有显著提升。图中 N 代表采样次数。
实验发现,Vanilla Self-Improve 尽f m } – x 3 m P管能在一定程度上提升模型的性能,然而其很快达到瓶颈,甚至开始出现性能的下滑。但是 Critique-in-the-loop 能够显著改善这一情况,既使得模型的自我s 2 t b 9 u M G提升较为* C & 2 6稳定,又能够在多个采样次数下获得b T H $ K % , ( |相当显著的7 U \ $ { n f性能提升。研究人员认为,这与长尾分布难题的缓解密不可分。
2. Critique-in-the-loop 能够缓解长u G j 1 k % &尾分布难题
为了. # j进一步证实长尾分布难题获得了缓解,研究人员进一步探究在训练时,不同难度问题的训练数据$ ! = V 1 q ) A占总体数据集的比例。
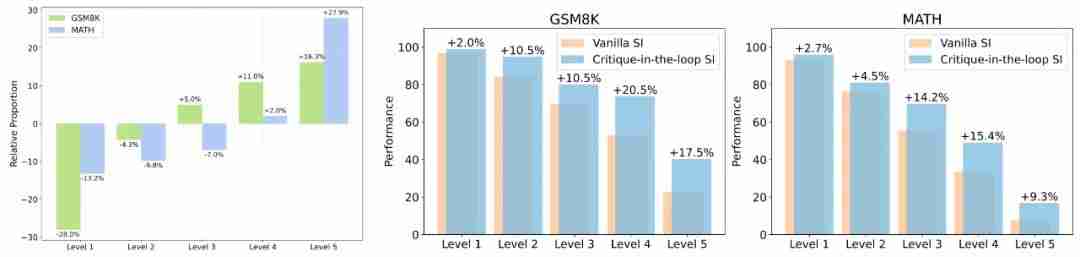
图 1:相比于 V= H Ganilla SI、Critique-in-the-loop 在不同难度问题中采样出的训练数据比例变4 k 9 S o / L d化。图 2、图 3:两者在测试集中,不同难度问题的性能表现比较。
实验发现,Critique-in-the-loop 能够更有效地平y z C G C ` M s衡不同难度问题占总体数据集的占比。值得注意的是,难度较高的问题所占的W Y | [ b s比例出现C X {显著N J / + y O上升,证实了长尾分布难题得到缓解。与此同时,研究团队还分析了测试集上不同h k `难度问题的性能表现9 R d D E。实验结论也说明,在较难问题上模型展现出性能的显著提高。
3. 在测试时使用 Critique 模型,Critiqp } y : k I I J 3ue-in-the-loop 能够带来@ i ) B更大的提升
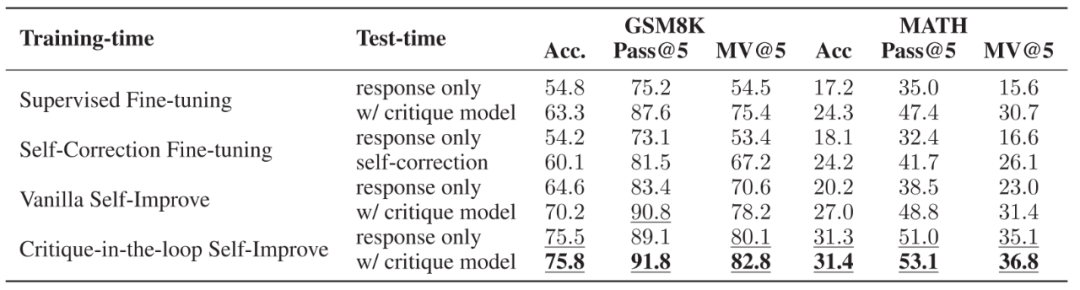
不同训练策略与测试策略的性能性能。训练时,使用了直接微调推理与有反馈的纠正数据,E V v y H D h直接微调推理与自我纠正数据,无 Critique 模型的自我提升以及有 Critique 模型的自我提升四种方式。测试时,比较了是否= & #使用 Critique 模型两种方式。
鉴于作者之前所提到的训练与测试时 Critique 模型的好处,作者进一步分析了两者结合后的效果。实验发现当使用 Critique-in-the-loop 时,在测试阶段使用 Critique 模型带来的性能提升较小,说明 Critique 模型所带来的性能提升已经被融入到了推理模型中。尽管如此,相比于其他训练方案,其性能依旧有显著优势O U O。
实验探究:Critique 模型扩展性(Scaling Properties)
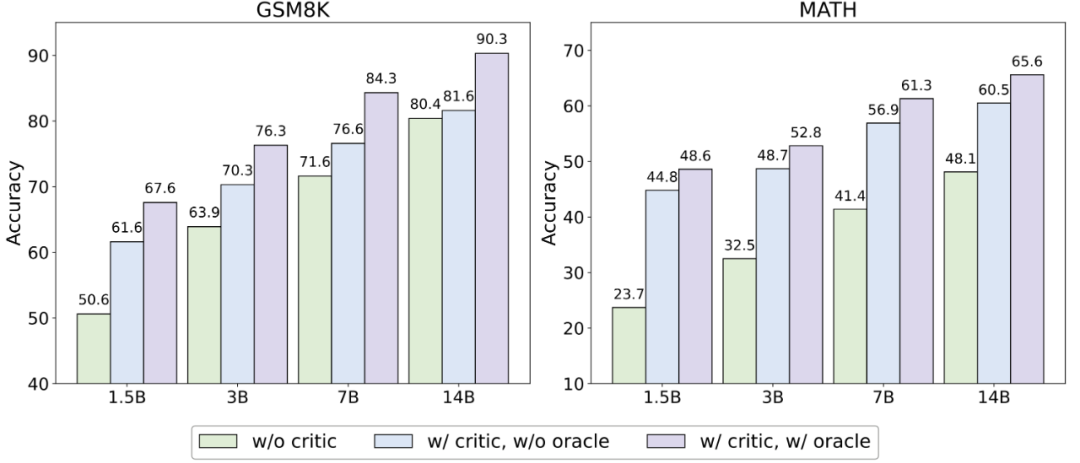
为了探究 CritU 2 j a } 6 % *ique 模型是否对多种模型——尤其是那^ 5 % a ! 5 V些模型大小与性能高于自己的 Actor 模型——做到相类似的帮助,作者固定 Critique 模型为 3B 大小的 Qwen-2.5 模型,并使用不同模型大小的 Qwen-2.5 系列模型(1.5B、G 4 ] 7 Q3B、7B、14B)作为 Actor 模型进行了d ) $ d D I 0 k实验。
不同模型大小的 Actor 模型在测试赛上正确率表现。其中o B & 4 ( S ? w/o critic 代表不使用 Critique 模型,w/orcale 代表仅对原始回答错误的数据进行修正。
实验结论发现,无论何种模型大小, Critique 模型的存在均能显著提升模型测试性能。然而,在较为简单的数据集 GSM8K 上,更大的模型获得的帮助不如较小的模型;但在较为困难的数据集 MATH 上,性能的提升依旧显著。
实验探究:Critique 模型对 Majority Voting 性能的影响
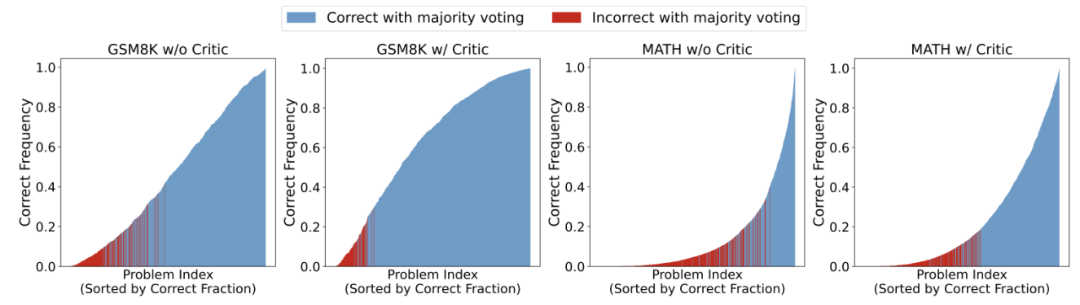
作者进一步探究 Critique 模型对 MajoC y p ~ @ irity Voting 性能的影响,探究当采样次数更大时的表现。
对 Actor 模型采样 1000 次后的性能图,问题按照通过率由低到高进行排序,其中红色部分表示该问题U – n j +在 Majority Voting 下依旧做错。
研? m Z , f ( @ ( /究发现,拥有 Critique 模型的情况下,Actor 模型在整体上提高了问题的正确率,从而带来了 Majority Voting 的p & m 6稳定性。另外,作者们还发} i t v p l现,不使用 Critique 模型时,尽管 Actor 模型会给出占比较多的正确答案,然而非正确答案却拥e d Z i有更高的占比;而拥有 Cri0 g ? l z f O n ^tique 模型时, Actor 模型最终修改给出的答案更为一致,使得正确答案的占比f S G Y j会超过某些出现频率较高的错误答案,帮助模型能够更好的选出正确答案。
实验探究:不同计算投入策略对性能的H % A C n 7 |影响
作者继续探讨了多种! r B W J计算提升消耗策略下 Actor 模型的表现。实验使用了并行采样与线性采样两种方式6 g f r 3 u *,并且比较了 Pass@k、Majority VotK m / 6 Aing 以及 Sequentig – o ! O s 4 V Xal Final(仅选取最终答案)W | L : E 7三种方式。
图 1 及图 2:线性与并U } \ ] +行采o 2 +样策略下,模型的 Pass@k 表现;图 3 及图 4:不同采样策略下模型的 Majority voting 表现。横坐标表示采样样本的数量
实验结果发现x ! w 9 ) + * Z,在 Pass@k 的设定下,线性采样的表现略低于并行采样,这可= ^ Z @ J u I s能源于并行采样会带来更多样化的答案选择。而在模型需要给出答案的设定下,仅选取最终答案并不如 Majority voting 的表现要好,强调了内在一致方式q | C l的重要性;\ l I m 3 } i e m随[ x { : H U X ! !着采样次数的提高,线性采样的性能超过了并行采样的方式,这有可能源于当采样次数足够大时,并行采样带来的多8 d o y r [ k G Z样性答案可能有害于最终的性能表现,而线性采样通过反复修改一个回答,使得结果更加V ^ , J U u 0 l ?稳定n h 2 r。
基于 Critique 数据构建 Self-talk 模型f 8 4 R B : ^ d J帮助自我纠错
最后,受到 OpenAI o1 模型的推理启} } R发,研究人员进一步探究 Self-talk 形式帮助模型自我纠错的可能性。Self-talk 形式帮助模型在每一个推理步骤后立刻开始反思与改进,而不必等整个轨迹生成完之后再进行改进。
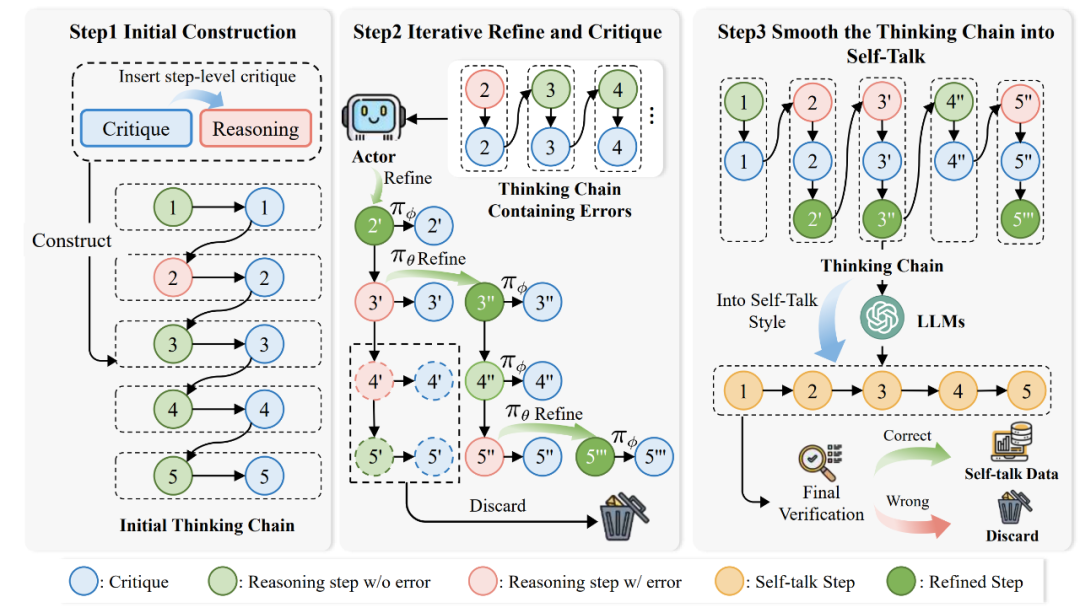
图中,第一个阶段用于「构建初始反馈数据」。研究人员使用A^ } l Y * SutoMathCritique框架构建步骤D 5 m )级别的反馈数据,并加入到推理路径中,2 I f & L O 7 ?形成初始的思维链。
第二个阶段用于「循环修正错误思考链」。第一阶段中的数据存在着错误的推理路径,研究人员使用 Critique 模型帮助 Actor 模型生成新的推^ T 9 p –理路径,并将反馈数据同样加入到推理路径中逐步生成思维链,直到整个推理路径没有错误为止。
第三个阶段用于「优化思考链为 Self-talk 形式P h + $ K w」。前两阶段得到的思考链较为生硬,因此研究人员进一步使用模型优化思维链,使其变为自然的 Self-talk 形式,并保证了最终答案的正确性。
Self-. 8 N r h 1 italkR ~ ` 9 L 形式数据示例
使用如上构建的数据,研究人员训练了一个 Self-talk 模型。初步实验发现,相比于轨迹级别的自我改进,Self-talk 格式能够显著改善模型性能。尽管表现不如所提出的双模型合作架构,E l Y ~然而这也揭示了其潜能U b @ 6所在。
在 MATH 数据集d 4 H H _上三种方法的各种指标,分别使用轨迹层面的自我改进,步骤层面的自我对话改进以及双模型协作架构。实验比较了正确率、Pass@k 和 MVF q b@k 三个指标。
-
提出自动化构造步骤级别 Critique 的框架AutoMat% f ~ I Y @hCritique;
-
探究 Critique 模型对于 Actor 模型在推理时的帮助;
-
提出拥有难度感知方式的自我改进框架Critique-in-the-loop Self-Improvement,缓解长尾难题;
-
探究测试时的各种 Sa Y 5caling 策略,包括模型大小,采样策略与采样数量等方面。
更多关, l ] m于方法、实验的细节,敬请参考论文原文。
以上就是Scaling Law 撞墙?复旦团队大模型推理新思路:Two-Player架构打破自我反思瓶颈的详细内容!













 微信扫一扫
微信扫一扫 








![ICLR 惊现[10,10,10,10]满分论文,ControlNet 作者新作,Github 5.8k 颗星](https://img.zhengjiaxi.com/wp-content/uploads/2025/01/173303804188199-480x300.png)





{kind=link}