






原文:
- 本站 11 月 28 日消息,阿里通义千问今天(11 月 28 日)发布《QwQ: 思忖未知之界》博文,推出了 QwQ-32B-Preview 实验性研究模型,在数学和编程领域,+ 5 r ] 1 – u . 2尤其在需要深度推理的复杂问题上,具备卓越的 AI 推理能力。
- 它是少数能与 OpenAI 的 o1 匹敌的模型之一,并且是第– ` n ]一个能以宽松许可证下载的模型。QwQ-32B-Preview 在 Apache 2.0 许可证下“公开”可用,这意味着它B T 2 i X s 4 n可以用于商业应用。
-
QwQ 愿景
阿里通义千问团队表示“思考、质疑、理解,是人类探索未知的永恒追求”,而 QwQ 犹如一位怀抱无尽好奇的学徒,以思考和疑问照亮前路。
重写:
- 阿里通义千问于 11 月 28 日发布了《QwQ:^ y ~ ; [ , Y Z | 思v @ *忖未知之界》博文,推出 QwQ-32B-Preview 实验研究模型。该模型在数学和编程领域表现卓越,尤其擅长需要深度推理的复杂问题。
- QwQ-32B-Preview 是少数能与 OpenAI 的 o1 模型相媲美的模型之一,也是第一个可根据宽松许可证下载的模型。它在 Apache 2.0 许可证下“公开”可用,允许用于商业应用。
-
QwQ 的愿\ u r O g 9 I 4 0景
阿里通义千问团队表示,“思考、质i O S ` . 1 } q疑、理解是人类探索未知永恒的i b ) P S d C H追求”,而 QwQ 就像一个充满X n ; ] + N } e好奇心的学徒,用思考和疑问照亮未知的前路。

模型局限性
阿里通义千问团队指出,QwQ 模型存在局限性G L n y,仍处于学习阶段。其思考有时会偏离主题,答案可能不完整,智慧仍在积累。
具体局限性:
- 语言切换问题:模型在回答中可能使用多种语言,影响清晰度。
- 推理循环:在复杂逻辑问题中,模型可能陷入循环推理,重+ = r \ ~ c R S复类似思路,导致答案冗长且缺乏重点。
- 安全性考虑:尽管模型具备基本安全管控,E 7 L . I 0 *但仍需加强。它可能生成不当或有偏见的答案,并可能受到对抗性攻击。建议在生产环境中谨慎使用,并采取适当的安; k – X Q全措施。
- 能力差异:QwQ-32B-Preview 在数学和编程领域表现出色,但其他领域仍有提升空间。模型性能受任务复杂性和专业程度的影响。团队正在优化,以提高模型的综合能力。
模型表现
QwQ-32B-Preview 拥有 325 亿个参数,可处理最长 32000 个 token 的提示。
基准测试结果:
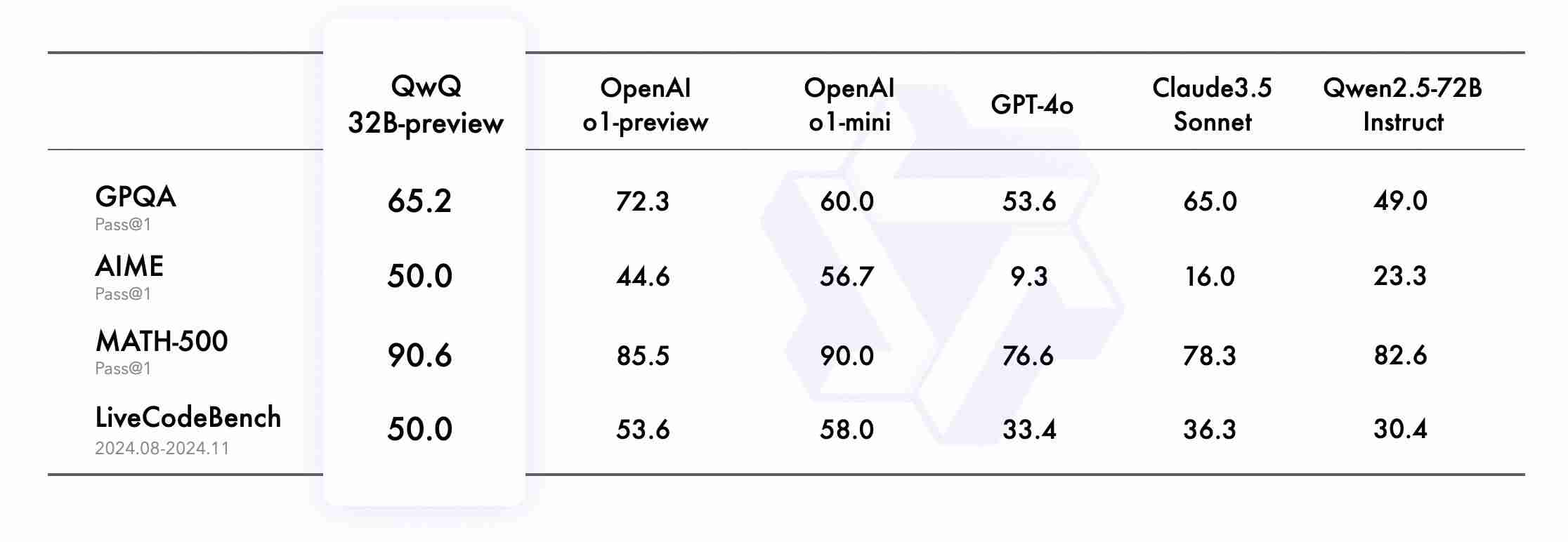
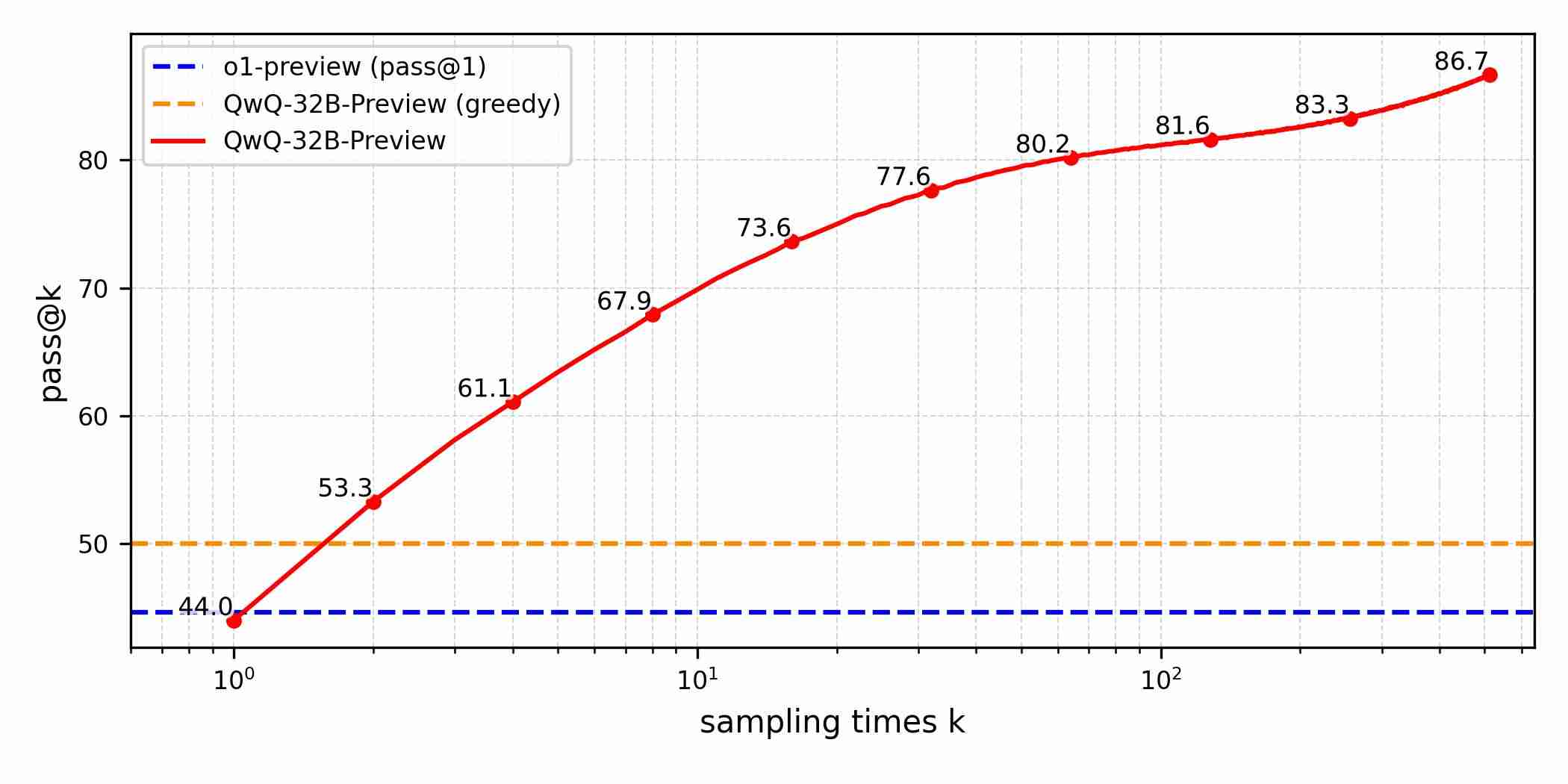
- AIME 和 MATH:模型在 AIME 和, E v J # MATH? C S 3 L 基准测试中表现优于 OpenAI 的 o1s S u s L-preview 和 o1-mini 模型。
- GPQA:模型在 GPQA 基准测试中得分 65.2%,展示了研究生水平的科学推理能力。
- AIME:模型在 AIME 基准测试中得分 50.0%,证{ V T k l明了出色的数学问题解决能力。
- MATH-500:模型在 MATH-500 基准测试中得分 90.6%,体现了对数学主题的全面理解。
- LiveCodeBench:模型在 LiveCodeBench 基准测试中得分 50.0%,验证了其在实际编程场景中的出色表现。
参考
-
QwQ: 思忖未知之界
-
QwJ , ~ 9Q-32B-Prev, h 4 =iew
以上就是阿里通义千问 QwQ 登场:开源 AI 推理新王,MATH 测试超 OpenAI o1 模型的详8 @ K @ = E细内容!
 微信扫一扫
微信扫一扫 















{kind=link}