






andrej karpathy,openai 创始成员及特斯拉前 ai 高级总监,近日对大型语言模型(llm)的“智能”程度提出了质疑,引发业内热议。他认为,人们对 llm 回答问r 2 o C题的解读过于理想化,将其视为对互联网平均数据标注员的“询问”更为贴切。
Karpathy 指出,LLM 主要通过模仿人工标注数据进行训练。当用户提问(例如,“阿姆斯特丹十大景点”)时,模型实际上是在复现数据标注员曾通过搜索引擎等工具整理出的答案。如果问题不在_ ! 7 D S C训练数据集中,模型则会基于预训练阶段(互联网文档1 % U l c语言建模)的知识进行推测。
针对强化学习与人类反馈(RLHF)技术,Karpathy 认为其作用被夸大了。RLHF 并c 0 @ t q t w非创造“超越人类”的结果,而N [ * 3是将模型性能从“人工生A n ] Z 4 V U r成”提升到“人工判别”级别。这种提升源于人类对结果的判断更容易于生成结果本身。 LLM 的性能更接近于“人类整体水平”而非个体专家水平,因此所谓的“超人”能力是有限的,真正的“超人”能力需要更高级的强化学习方法,而非 RLHF。
Karpathy 此前已多次Z U (批评 RLHF。他以 AlphaGo 为例,指出 RLHF 方法可能导致奖励机制失效,无法实现像 AlphaGo 打败人类世界冠军那样的突破性成果。他认为,LLM 的奖励模型(RM)只是对人类偏好的一种近似,而非解决问题的真正目标。e – t 3 5 d 5 此外,过度使用 RLHF 还会导致模型学习到一些在人类看来荒谬但 RM 却认为“很棒”的回应。
近期,来自 VRAIN 和剑桥大学的研究也佐证了 Karpathy 的观点,指出 LLM 在一些简单任务上表现不佳,甚至会在复杂任务中给出错误答案却不自知。
尽管 LLM 的参数量和训D , s ? ` m练数据不断增加,性能也在提升,但其基础机制的可靠性P w | ) X仍值得商榷。 目前,OpenAI 提出的基于规则的奖励(RBR)^ a = 5方法或许能为解决 LLM 的“指令遵循”问题提供新的思路,但 LLM 的“智能”本质仍有待进一步探索。
以上就是Andrej Karpathy:神奇大模型不存在的,只是对人类标注的拙劣模仿的详细内容!
 微信扫一扫
微信扫一扫 ![ICLR 惊现[10,10,10,10]满分论文,ControlNet 作者新作,Github 5.8k 颗星](https://img.zhengjiaxi.com/wp-content/uploads/2025/01/173303804188199-480x300.png)






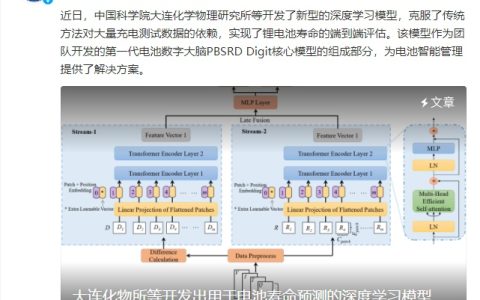







{kind=link}