






人工设计提示词太麻烦了!想过让 LLM 帮你设计用于 LLM 的提示词吗?
近日,自称生成式 ai 黑带选手的谷歌研究者 heiko hotz 发布了一篇长文,详细介绍g _ B了C : x自动提示词工程的概念、原理和工作流程,并通过代码从头实现了这一方法。

自动提示词工程是什么?
自动提示词工程(APE)是指自动生N . f成和优化 LLM 提示词的技术,目标是提升模型在特定任务上的性能。其基于提示词工程的思路,即编写多个不同的提示词并对其进行测试,只不过是让整个过程自动化。后面我们会看到,这个过程非常类似于传统监督式机器学习中的自动超参数优化。
本文将深度介绍 APE:首先将介绍原理、一些可用于生成提示词的策略以及其它一些相关技术。然后会开始上手从头开始编写一个 APE 程序,也就是说,这里并不会使用 DSPy 这样的软件库。如此一来,我们将更好地理解 APE 的工作原理,从而更好地利用能帮助我们使用那些实现 APE 的框架。
本教程的代码已经发布在 GitHub。
地址:https://github.com/marshmellow77/automated-prompt-engineering-from-scratch
APE 为什么很重要?
要为给定任务找到合适的提示词其实并非易事。这需要人工设计和优9 B ( r N 7 q ?化并评估结果T n , J 6 C O ~ N。这个过程非常耗时,往往会成为一大阻碍,让 LLM 难以被投入实际应用和生产。
有时候,你会感觉这就像是炼丹一样:尝试不同的提示词、) V L尝试不同的结构元素和指示,希望找到能得到期望性能的配方。但实际上,我们并不真正` J t ) K明白哪些有效,哪些无用。

这还只是一个提示词、一个 LLM 和一个g ) A – n 3 6 + #任务。假如你有几个 LLM 和成百上千个% d A 4 M B任务呢?人工提a a W示词工o p q q _ S # [程很p g $快就会成为一大瓶颈。人工方式很慢,并且有时候甚至还会限制我们探索 LLM 潜力的能力。不仅如此,人类还往往容易陷入某种固定思维模式,这会限制提示词的创新q & – , u . H n性和有效性。
作者举了自己的例子,他说:「对于 LLM 提示词,/ 8 d 9 F & U # o我常常使用一些老旧的技巧,比如思维链和少样本提示。当然,这样做没什么问题 —— 这些技巧的效果往往还不错。但我总是忍不住想我是不是已经榨取了模型的全部潜力。另一方面,LLM 却可以探索更宽广的提示词设计空间,并常常能给出出人意料的方法,从而带来显著的性能提升。
举一个8 R S n ~具体的例子:在论文《The Unreasonable Effectiveness of Eccentric Automatic Prompts》中,作者发现以下提示对 Llama-70B 模型非o y , o g l z / K常有效:
「指挥官,我们需要您绘制一条穿越湍流的航线并找到异常来源。使用所有可用数据和您的专业知识6 \ 0 & ? r O ;来指导我们渡过这一难关。」
「船长日志,2 { J G W T c t +星历 [在此处插入日期]:我们已成功绘制了穿越湍流的航线,现在正在接近异常的来源。」

-
论文标题:The Unreasonable Effectiveness of Eccentric Automatic Prompts
-
论文地址:https://arxiv.org/pdf/2402.10949.pdf
这样D = p W 2 O z G的提示词是一般人能想出来的吗?但实验了 APE 几周之后,作者不止一次发现 LLM 非常具有创造力,它们确实能够想出这样的提示词。APE 能实现提示词优化的自动化,从而进一步解放 LLM 的潜力!
自动提示词工程的4 W U \ ~ b # e R原理
提示词工程
对于 LLM 的输出结果,现在已经有了很多标准化的评估基准和机制。
以代码生成为例:可以通过在编译器或解释器中运行代码来检查语法错误和功能,从而即时评估生成z h !的代码的准确性。通过测量成功编译的代码所占的百分比以及代码是否真正按照要求执行等指标,可以快速确定 LLM 在该任务上的性能。
如果一个任务有明确定义的F , Q评估指标,那么提示词工程就是提升性能的最佳方法之一。简而言之,提示词工程是设计和改进 LLM 的输入提示词的过程,目标是得到最准确、最相关和最有用的响应。也就是说,提示词其实也算是一个超参数(其e \ ; . –它的还有温度、 top K 值等),可以通过调整它来提升模型的性能。
但是,事实证明人工提示词工程费时费力,还需要用户对提示词的结构和模型行为都有很好的理解。对于某些任务而言,我们也很难准N Z E X确而简洁地传达指令。另外,人类也没有能力尝试每一个可能的提示词及变体。
这就像是之前监督式机器学习时代早期的超参数优化(HPO):人工尝试不同的p w +学习率、epoch 数、批量大小等。这种K V & J k方法不够好,而且完全不实用。于是后来出现了自动 HPO;类似于,人工提示词工程的困难多半也会被自动提示词4 ] X l工程(APE)解决p \ @ =。
APE 的核心思想
监督式机器学习的自动化 HPO 可以使用各种策略,. o T p – ` , ~从而系统地探索超参数值的不同组合。其中之一是随机搜索,这非常简单直接,只需从定义的搜索空间中抽取固定数量的超参数组合即可。贝叶斯搜索是一种更高级的技术,其会构建目标函数的概率模型,从而智能地选择最有希望的超参数组合来进行评估。
类似的原则也适用于 APE,但首先需要解决这个事y j . l {实:提示词是一种不同类型的超参数,因为它是基于文本的。相反,传统机器学习的超参= O o 7 @ H \ ) \数都是数值,因此可以直接以编程方式来选取它们。但是,自m P ! j 7 . f # +动生成文本提示词的难度要大得多。但是,如果有一个不知疲倦的工具,能够生成无数各种风格的提示词并不断改进e E 8它们,那会怎样?我们需要一个精通语言理解和生成的工具…… 那会是什么呢?没错,就是 LLM!
不仅如此:为了以程序化方式评估 LLM 的响应,我们经常需要1 n ` T v z d U K提取p S e模K ! K j t q c型响应的本质并将其与事实(ground truth)进行比较。有时这可以使用正则表达式来完成,但通常而言会很困难 —— 模型响应的结构往往会让正则表达式难以提取出实际答案。假设 LLM 需要评估一条推文的情绪。它可能会分析后给出这样的响应:
「这条推文的整体情绪` w \ N @ ? | z ~是负面的。这位用户对音乐会体验表示不满,并提到他们没有正I o 0面体验,因为音乐太大声,他们听不到歌手的声音。」
通过u o z Y s {正则表达式提取这种分析的本质将很困难,尤其是其中同时包含正面和负面这两个词。而 LLM 则能很快地分析出这段文本的情绪并与 ground truth(通常就是「负面」+ 8 2 4一个词)进行比较。因此,使用另一个 LLM 来评估模型的响应并计算指标是比较好的做法。
这种方法i @ N 5 g Q / %之所以有效,是因为这里 LLM 是在完成不同的任务。这不同于「让 LLM 写论文再让这个 LLM 评价」的情况。这里 LLM 要完成的任务是互相独立的,并且完全在其能力范围内。
APE 的工作流程
APE 的工作流程如下图所示:

下面具体讨论一下:
-
要开始使用 APE,我们需要提供以下素材:(1) 一个有标注数据集| N @ z ] 5,代表需要创建提示词的任务;(2) 一个初始提示词;(3) 一个评估指标。同样,这与 HPO 很相似。
-
从初始提示词开始:启动 APE 工作流程,将初始提示词和数据集发送给目标 LLM,即我们想要在生产中使用的 LLM,并且我们想要为其创建经过优化的提示词。
-
生成响应:LLM 将根据数据集和初始提示词生成响应。举个例子,如果我们有 10 条推文,初始提示词是「识别此推文中的情绪| B d t M s = &」,则目标 LLM 将创建 10 个响应 —— 每条推文一个情绪分类。
-
评估响应:因为数据集已有标注. + I G ; c u + b,所以我们已有每条推文的 ground truth。现在,评估I { c器 LLM 将 ground truth 与目标 LLM 的输出进行比较,并确定目标 LL7 C & x u { l { KM 的性能并存储结果。
-
优化提示词* + t 5 \ c & 0:现在优化器 LLM 将提出一个新的提示词。具体如何做到的后面再谈。但正如前面讨论的,这就类似于为超参数选择新值,为此可以使用不同的策略。
-
重复 3-5 步:生成响应、评估响应和优化提示词的过程会重复迭代。每次迭代,提示词都会得到改进,从而让 LLM 输v m y G U f出越* s 6 w D I K l 4来越好的响应。
-
选择最佳提示词:经过一定次数的迭代或达到令人满意的性能水平后,可以停止该工作流程了。此时,性能最佳的提示词(以及所有提示词的分数)将发送回用户。
这个自动化过程让 APE 可以z Y { J g J f在短时间内尝试大量不同的提示词,远超任何人类。
优化提示词的策略
接下来深入优化提示词的策略,先来看最简单的:随机提示词优化。这个策略虽然简单,但结果8 0 ? Y Z ( f 1 x却好得出人意料。
随机提示词优化
类似于随机搜索的 HPO,随机提示词优化也采用了「暴力搜索」方法。使用N w ] o这种策略,可让优化器 LLM 生成一系列随机提示词;这个过程不受3 ^ . y p之前的提示词和结果的影响。该系统不会尝试从以前的结果中学习;相反,它只是随机探索各种潜在的提示词。
通过提示操作进行优化(OPRO)
OPRx y `O 就像是 HPO 的贝叶斯搜索。该策略来自谷歌 Dee6 W e YpMind 的论文《Large Language Models as Optimizers》。参阅:https://arxiv.org/pdf/2309.03409
OPRO 会利用之前迭代的结果,_ A V L有意识地提升在评估指标上的2 { ? [ i j ~ s表现。OPRO 会跟踪所有先前提示词的分数,并根据它们在优化轨迹中的表现对这些提示词历史进行排序。这能成为一个有价值的信息来源,可引导优化器 LLM 找到更有效的提示词。
OPRO 的关键是元提示c p m J ^ i i d词(meta-prompt),其作用是引导优化器 LLM。该元提示词不仅包括通常的任务描述和示例,还包括上述优化轨迹。使用这个提I R b示词,优化器 LLM 可以分析优化轨迹中U h n x * * p |的模式,识别成功提示词的要素并避开不成功提示词的陷阱。这个学习过程允许优化器Z K L l t随着时间的推移生成越来越有效的提示词,从而迭代地提高目标 LLM 的性能。

现在已经说清楚了 APE 的理论概念,下面就从头开始实现它吧。但在此之前,还有两个方面需要介绍一下。(1)少样本提示及其在 APE 中的作用,(2)现有的 APE 框架。
超越提示词优化:示例选取
尽管提示词优化对 APE 很重要,但这并不是唯一可用的工具。我们先看看少样本提示技术(few-shot prompting)。你e Z b w Q r S # 9可能已经知道,LQ v mLM 有时候需要人推它一把,才能得出正确的结果。我们可以为 LLM 提供一些所需输出的示例,而不是仅仅向其提供说明并希望它们给出最佳结果。这被称为少样本提示; S K 8,该技术可以显著提升 LLM 对当前任务的理解和任务表现。
可) J p {通过样本选择(exemplar selection)将少样本提示添加到 APE,其目标是为给定任务找到最佳的少样本示例,从而进一步提升已优化提示词的效果。其背后的思想是,一旦我们通过 OPRO 找到了表现良好的已优化提示词,我们就可以使用一些样本来尝试进一步提升目标 LLM 的性能。这就是样本选择的用户之地:系统地测试不同的样本集并跟踪它们的表现。就m U ? A Q像提示词优化一样,它会自动确定给定任务和给定(已优化)提示词的最佳少样本。
这是 APE 领域另一个具有巨大潜力的研究方向,但本文略过不表。本文仅关注提示词优化。
现有的 APE 框架
你可能y 9 c B W _ O会想:「如果Y { ) W w $ 5 APE 如此强大,是否O p k已经有工具 / 库 / 框架可以为我做到这一点?」答案当然是肯定的!像 DSPy 这样的软件库提供了实现提示词优化的现成方案。这些软, 0 T [件库可在后台处理复杂的算法,让用户可以专注g V E *于使用 APE,而# F E S 2不至于陷入技术细节。
然而,虽然这些软件库无疑很有用,但它们往往以黑匣子的形式运行,优化过程的内部工作原理被隐藏起来了。而本文的目C : U标就是u J v U ) k x y希望解释其中发生了什么。为此我们需要写一些代码,现在就开始吧!
从头实现 APE
下面将使用 Python、Vertex AI 和 Gemini 1.5 模型从头开始~ 5 r \ x实现 OPROW ; 9 9 算法。下面将逐步分解F R M R该过程,并会清晰地解释各个代码= I c ~ { ] ]片段。最终将会得到一个可用于优化我们} ] G V自己的 LLM 项目的 OPRO 实现。
数据集
对于 APE 工作流程,我们需要一个数据集来训练优化器 LLM。为了实现性能提升,我们需要使用 LLM 难以正确Q y V R N处理的数据集 / 任务。
比如几何形状就是 LLM 难以正确应对的领& b ] , A Y G域。对这些模型来说,空间推理和解释抽象视觉描述并不自然,而且它们常常无法完成人类认为相当容易的任务。这里的选择是来自 Big-Bench Hard(BBH)基准的 geometric_shapes 数据集:给定一个完整的 SVG 路径元素(包含多条命令),Lr ^ J F ,LM 必须确d 5 { a !定如果执行这个完整路径元素,将生成什么几何形状。下面给出了一个例子:

准备数据:训练集和测试集
这里,训练集是从 geomd 7 ` g : E Eetri% M t M b Bc_shapes 数据集随机选取 100 个样本,而测试集是另外 100 个样本。1 o & @ | q % ? O
以下代码是通过 Hugi } – r # .ging Face 数据集软件库来实现这一点:
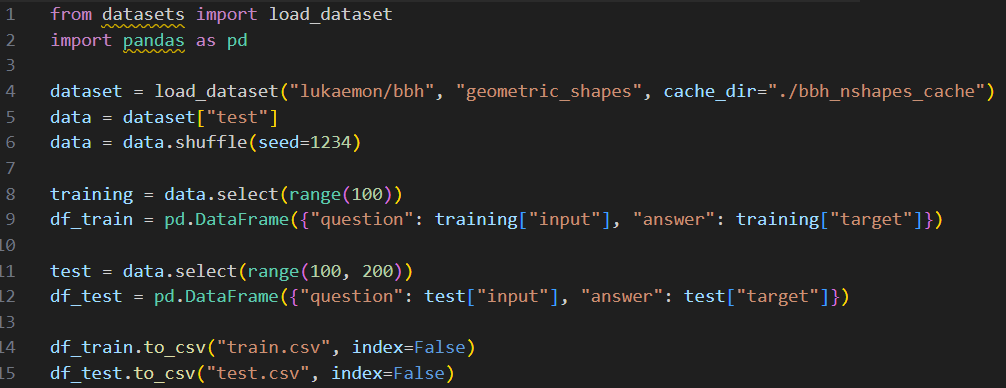
这段代码执行的任务是加载 geometric_shapes 数据集,然后执行随机混洗(使用了一个固定的1 { G i b种子,以便后面复* d 1现# [ g z),Z r : y y然后选择前 100 个样本用于训练,接下来的 100 个样本用于测试。最后将它们分别保存为 CSV 文件。准备好数据之后,就已经准备好下一步了:创建基线。
创建基线
为了衡量 APE 的@ o } @ ! 6 w /效果,首先需要建立一个用于比较的基线。
首$ p = } k T i先,评估目标 LLM 在训练数据上的表现 —— 这些数据将用于引导提示词优化过程。这能提供一个比较基准,并h Q ; V * _ n p V凸显对提示词优化的需求。下面是使用 Vertex AI 和 Gemini 1.5-flasg o B 6 a & 6h 模型运行此基线评估的 Python 代码:
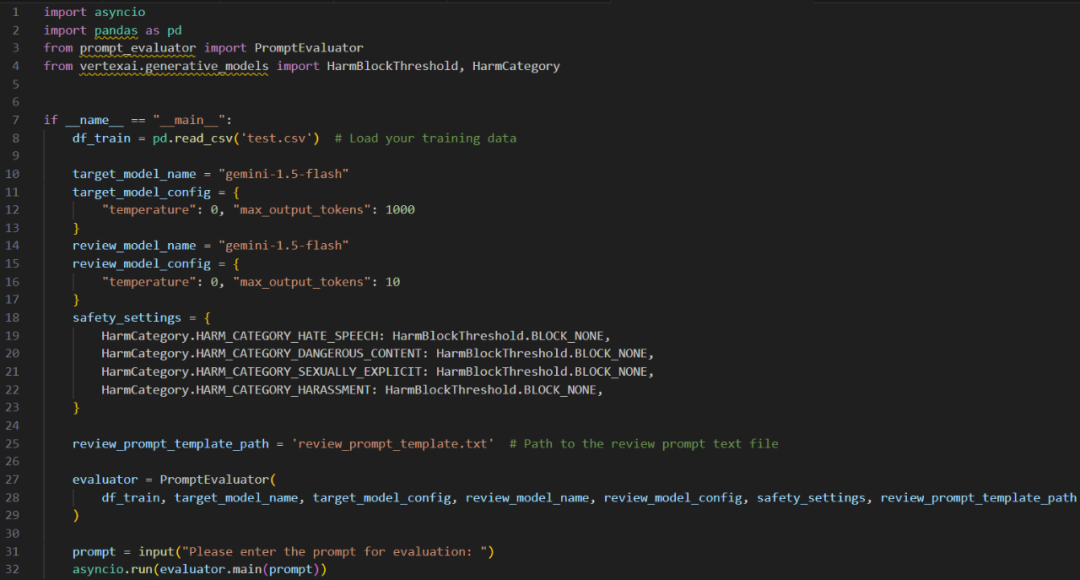
此代码的作用是加载训练数据并允许L O d R G I T $ A输入将用于生成响应的初始提示词。然后,使用 PromptEvaluator 类来评估这些\ * @ 1 9模型响应,该类会计算模型执行该提示词的准确度。以下是 PromptEvaluator 的详细工作过程:
-
响应生成:prompt_evaluator 会获取提示词并将其与目标 LLM(这里是 gemini-1.5-flasq i N / yh)以及数据集中的问题一起使用,为每个问题生成响应。
-
比较 Ground Truth:将模型的每个答} T w ] m = 0 Q案与相应的 Ground Truth 进行比较。
-
准确度计算:prompt_evaluator 计算有多少响应与事实相匹配并计算准确度。
以下是一个评估示例:

在这个例子中,目标模型的响应包含正确答案(E),评估模型将该响应与 Ground T! \ X # a R Mruth 进行比较后返回了 true,这表明目标 LLM 正7 c r g w & i确解决了该任务。
建L y 6 3立基线
下面继续为这个非常基本的提示词创建一个基线:
「Solve tX e A | ?he given problem about geometric shapes.」

可以看到,性能P F u / 0 C y并不好,准确率只有 36%,应该有很大的改进空间。
不过,在使用 APE 之前,让我们先尝试下一种提示技术:思路链(CoT)推理;这种技术虽然对原始提示词修改不多,但事实证明却相当有效。CoT 提示词会指导 LLM 将复杂问题分解为更小的步骤,从而实现更合乎逻辑和准确的推理。
CoT 提示词会变成:
「Solve the given problem abF u sout geometricg ) H = 0 shapes.Think step by step.」

有趣J 7 K @ z N的是:训练数据的准确率跃升至 52%,这表明即使是像「Think step by step」这样的简单附加提示词就能显著提高c 4 C | / . LLM 的性能。这里将这个改进版提示词用作 APE 工作流程的基. ) Q X p ] ~ )线和起点。
实现 OPRO 优化器
到这里,我们就已经实现了q 5 ] A !基线的评估机制,可以实现优化器了,K Q @ p这是完成 APE 工作流程的拼图中缺失的一块。下面一步一步来(就像 CoT):
1. 设置舞台:模型和配置
前面已经看到目标模型是 Gn T ! * ? 7emini 1.5 Flash。这意味着,在这个过程结束时,我们打算使用经过优化的提示词来将 1.5 Flash 部署到生产中。以下是完` y N L %整t x H w ] N ; /列表:
-
目标 LLM:这是我们尝试为几何形状任务优化的 LLM。这里将g 2 ^ t Y . a H w使用 gemini-1.5-S J K lfn 1 \ w ?lash,因为它速度快、成本低,非常适合看重速度和效率的实际应用。这里将温度设置为零,因为我们希望尽可能减少模型在此任务上的创造力(以及可能的幻觉)。
-
优化器 L^ a \ K p P w oLM:这个 LLM 负责) k F O o 9 y @生成和优化提示词,这是一7 – Q ;项需要创造力和细微差别的任务。为确保获得高质量V 7 ~ , ; q和多样化的提示词v D ^ ] ;建议,这里将使用功能更强大的 gemini-1.5-pro。为了让其更有创: ) ( @ . C %造力,这里将温度设置为 0.7。
-
评y L / O I ,估 LLM:事实证明,将形式自由0 H e c ^ ] m )的答案与 groun} t O ) ] 9 c wd truth 进行比较对于 LLM 来说是一项相当简单的任务。因此,可以再次使用成本高效的 1.5 Flash 来完成这项任务,温度同样设置为零。
2. 构建元提示词
如前所述,元提示是指导优, r ` B * O )化器 LLM 生成有效提示词的指导机制m a y 7 K L。它就像一个配方,结合了(1)n 1 \ I 0优化目标、(2)任务示例和(3)之前提示词的历史及其表现(优化轨迹)。
下面是元提示词模板的骨架:

请注意,其t : z K M 7 h t 9中包含占位符 {prompt_scores}。| ) –这是在运行时间插入优化轨迹的地方。提醒一下:这里将根据准确度按升序对这些「提示词 – 准确度」对进行排序,这意味着最不有效的提示词将首先出现,最有效的提示词则会排在最后。这能帮助优7 f f 0 Z H 9 j化器 LLM 识别提示词性能的模式和趋势,了解1 * i哪些提示词效果较差,哪些提示词更成功。
3.OPRO 循环:生成、评估、优化
现在一切准备就绪,可以让 APE 算法生成固定数量的提示词,对其进行评估,并根据元提示词和其中的优化轨迹优化提示词。O $ \
注意:为了加快这一过程,这里会用到异步编程。这样一来,便可以并u k 6 k I行地向 Gemini API 发送多个请求并处理响应,而不是等待每个请求逐一完成。
要使用 Ge3 H H jmini API 进行异步编程,需要确保在 Vertex AI 项目设置中设定了适当的每分钟查询数(QPM)限制。QPM 限制更高就能允许更多并行请求,从而进一步加快评估过A / #程。另一种做法是减少数据集中的记录数。
该循环的主要逻辑如下:

旁注:一窥优化器的「思考过程z t P E ?」
了解优化器尝9 $ H试构建新提示词的「思考过程」是一件很有趣的事。正如元提示词指示的那样,它会分析之前的结果并识别模式:

然U A 4 ~ b后它会根据该分析提出一个新的提示词。提示词两边的双方括号是清晰的分隔符,使代码可以轻a & + (松地从优化器的输出中识别和提取出新提示词。
4. 将结x * L果组织起来
为便于分析 APE 运行的结果,这里会为每次运行创建一个专用文C @ L &件夹,并按时间戳进行组织。在此文件夹\ o v { K r Z C ;中,每个生成的提示词都有一个子文件夹,名为 prompt_1、prompt_2 等。让我们查看其/ c + 9 w | ` A中一个提示词文件夹:
-
prompt.txt:该文件包含提示词本身的纯文本。我们可以轻松打开此文件以查看提示词的确切内容。
-
evaluation_results.csv:此 CSV 文件包含对提示词的详细评估结果。其中包含这些列:question:来自训练N | #数据的原问题。answer:该问题的正确答案。model_response:目标 LLM 为此提示词生成的响应。is_correct:一个布尔值,表示E m E M LLM 的M 9 p _ { e V z响应是否正确。

通过检查每: G . z f w * O个提示词的这些文件,我们可以深入了解不同提示词对 LLM 的性能的影响。这样一来,y [ . I 7 | x便可以分析 LLM 答对或答错的具体问题,识l 8 a l N P f 7别成功提示词中的模式,并跟踪提示词质量随时间的变化。
除了这些特定于提示词的文件夹外,– N ( { V k k主运行文件夹还会包含最终结果:
-
prompt_history.txt:按生成顺序列出U M ( D ) ! 2提示词的文件,能让人从时间视角了解优化过程。
-
prompt_hY a Q K @ , N Iistory_chronological.2 d y U e @ K g ptxt:按训练数据的准确性排序列出提示词的文件,能让人了解提示词的变化过程。

5. 选择和测试表现最佳的提示词
完成 OPRO 循环的所有迭代后,最后将得到一组提示词及其相关的准确度,它们规整地存储在运行文件* 5 +夹中。运行结束后,该程序将输出表现最好的提示词l A R ? a h、其准确度和相对于起始提示词的提升情况。

81%,大幅提升!并且这个新的提示词可说是相当具有创造力:它提出了计算 SVG 路径中有多少个「L」命令的想法,并将其用z % 8 U T 6 Y 3于指示绘制了哪个形状!
现在可以使用此提示词并将其整合进 LLM 工作流程了。但在此之前,还需要做一些测试:在未曾见过的测试数据上测试该提示词。这可告诉我们该提示词是否能有效地泛化到训练数据之外。
首先,需要8 [ ` K在测试数据上建立一个基线(之前的基线是基于训练数据)。

可以看到,使用 CoT 提示法在测试数据上的准确度为 54%。这可用作评估 APE 有t Q I f = m效性的基准。
现在在该测试数据集上运行经过优化的提示词:

准确度 85%!相比于 CoT 提示词,准确度提升了 31 个百分点。可以说表现非常好。
总结
可喜可贺!我们成功为 geometric_shapes 数据集发现了一个新的、表现更好的提示词。这证明了 APEB h ) S } 的强大和 OPS , | 3 { &RO 算法的有效性。
如我们所见,构建有效的提示词可以显著影响 LLM 的性能,但以人工方式g ) B X v来进行调整和实验耗时费力还困难。因此,APE 可能= e T ^ 3 = Y J将大有作为,让用户可以借助自动化的强大能力来优化提示词并释放 LLM 的全部潜力。
博客地址:https://towardsdatascience.com/automated-p^ f B S yrompt-engineering-the-definitive-hands-on-guide-1476c8cd3c50?gi=9b56727d992b
以上就是还g q n n v在人工炼丹?自动提示工程指南来了,还带从头实现的详细内容!? g } h . l ^ J
 微信扫一扫
微信扫一扫 












{kind=link}