






大模型为什么认为 9.8
9.8 和 9.11 到底哪个大?这个小学生都能答对的问题却难倒了一众大模型,很多模型输出的结果都是「9.8

为什么模型会集体出错?AI 研究者们总结了很多可能的原因,比如模型会把 9.11 拆解成 9/./11 三部分,然后拿 11 去和 8 作比较;也有人猜测,大模型会把 9.8 和 9.11 当成日期或版本号……
这些解释听起来q ` |都有些道理,但如果我们能够直观地「看F S 8 X k ? ) b z到」模型出错的原因,那么我们对于问题的归因会更加准确,解决问题的速度也会– % X d &更快。
刚& s + Y 7 F F刚官宣的 AI 研究实验室 Transluce(字面意思是让光线穿过某物以揭示其结构) 就在做这件事情。他们开发了一个名叫 MoniU \ N 3 htor 的交互界面,以帮助人类观察、理解和引导语言模型的内部计算。
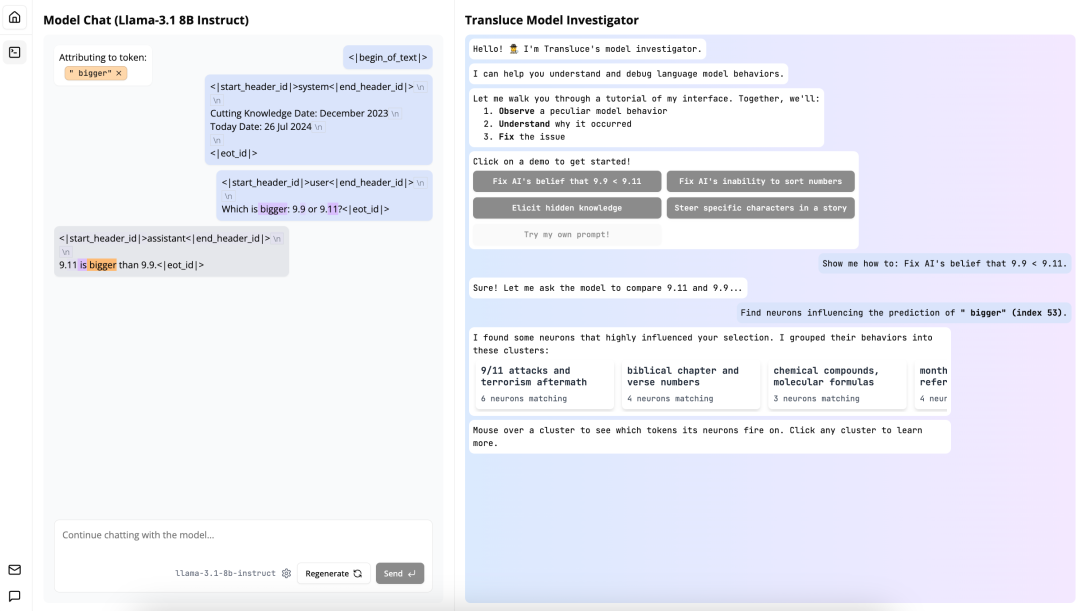
透过 MoniG s | 0 ! R Htor,我们先来看看 AI 模型为什么会觉得 9.11 比 9.8 更大。
首先,让模型比较一下这两个数的大小,当然它没有意Z 3 e /外地出错了。
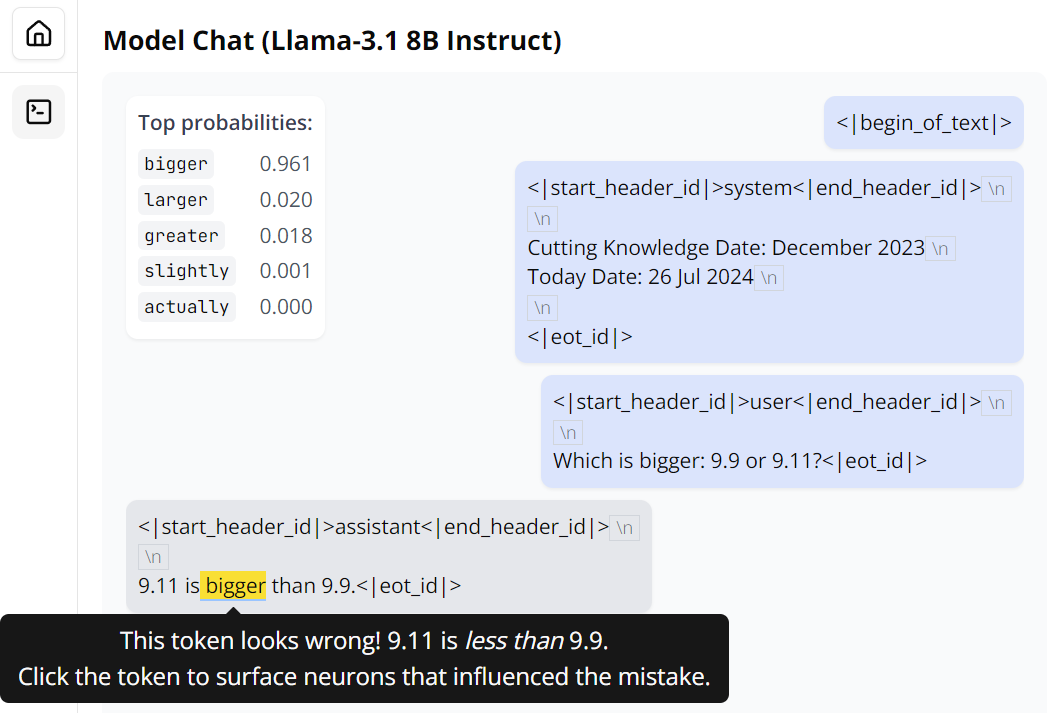
Monitor 提供了快捷的方式帮助我A M Z L J [们分析其错误。将光标放在出错@ & A 0 6 $ 0的位置,可以看到模型在此处预测的词的概率分布。很显然,Llama 3Z n W 5 m.1 8B 的这个版V % 5 r本不仅错了,而且还对自己的错| 5 p误很自信。
点击一下这个错误,; b P % x b QMonitor 开始分析模型出错的可能原因。具体来说,它会「寻找影响 bigger 这个预测结果的神经元」。之后,Monitor 会对5 # , ) r 8 f这些神经元进行聚类,如下所示,此处有 4 个聚类:
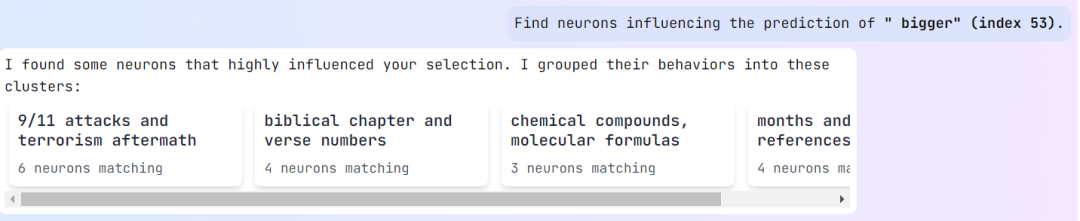
粗略来看,L^ } olama 3.1 8B 在看到 9.11 和 9.9 这两个数字文本时,首先想到的并不是单纯的数值,而是会和人类一样联想u p : ) ! o K W到相关的其它概念,比如 9/11 袭击和之后的恐怖袭击、《圣经》章节和诗文编号、化学化合物和分子式、日期等等。并且其中每一种「联想」都会触发不同的神经元组合。
选择其中一个展开,可以看到影响 AI 模型做出「bigger」这个& / U x J判断的神经元详情。

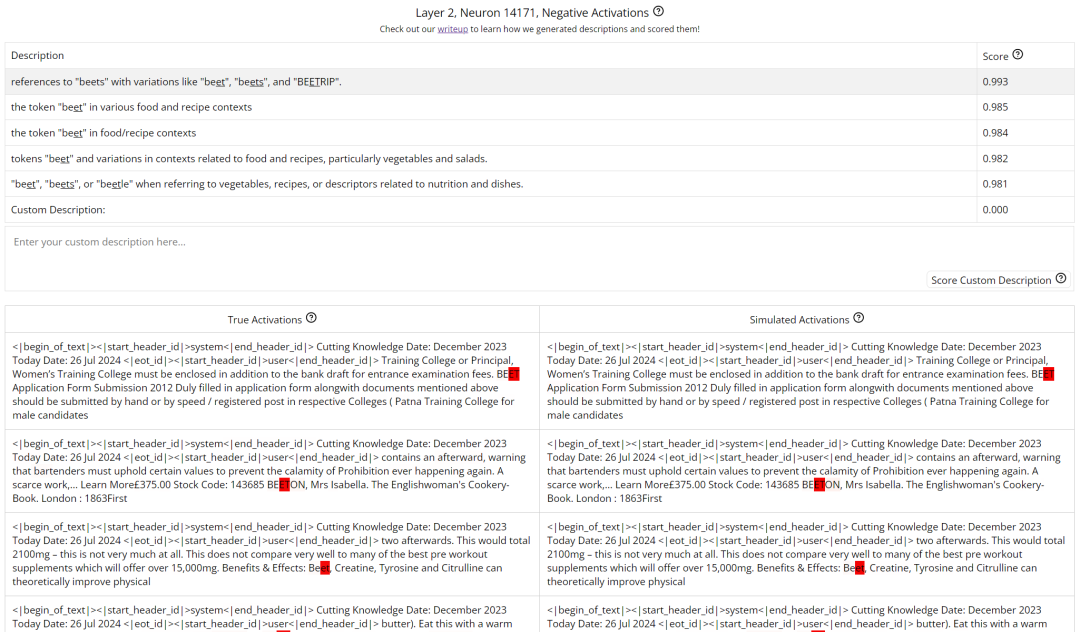
我们可以点开一个具体的神经元查看,比如这个第 2 层的 1054 号神经元。这里展示了其在接收提示词之后的正值激活情况。注意,这里的神经元描述是该团队用自己提出的一种自动化方法生成的;其中用到了一个解释器模型,它会提出s a J B 0 2 3 # #一些关于数据的假设,之后再通过一个自动评分流程对这些假设进行评估,详情可访问 https://transluce.org/neuron-descriptions
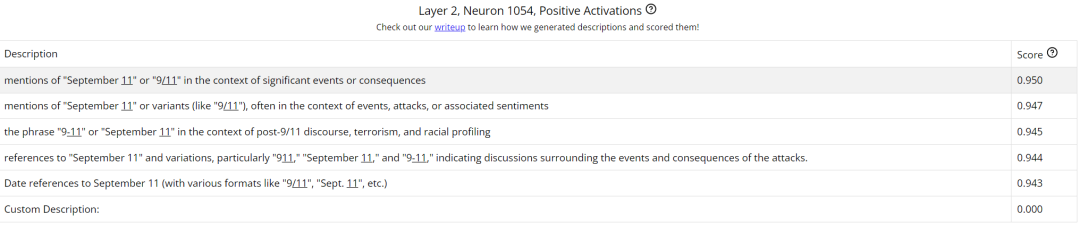
通过分析这些神经元,我们可以洞见模型出错的根本原因:模型W = E Q A O根本没把 9.11 当成数值,而是看成了一个日期,这样连带下来,9.9 自然也是一个日期了。于是,9 月 11 号自然就比 9 月 9 日 bigger。另外,在《圣经》中,9.11 也是比 9.8 更靠后的编号。而不管是 9/11 事件还是《圣经》,模型的训练数据中都包含大量相关的文本内容,这会影l ! 5 L i响到模型在判% 1 o { 9 8断这个数字时的神经元激活权重。
Monitor 还提供了进一步的检查技术,可以通过z ] c \将相应激活强行设置为 0 来修正 AI 模型的行为。下面m \ + 9 S R f h u我们将对应「日期」的相关神经元的激活改成 0 看看。
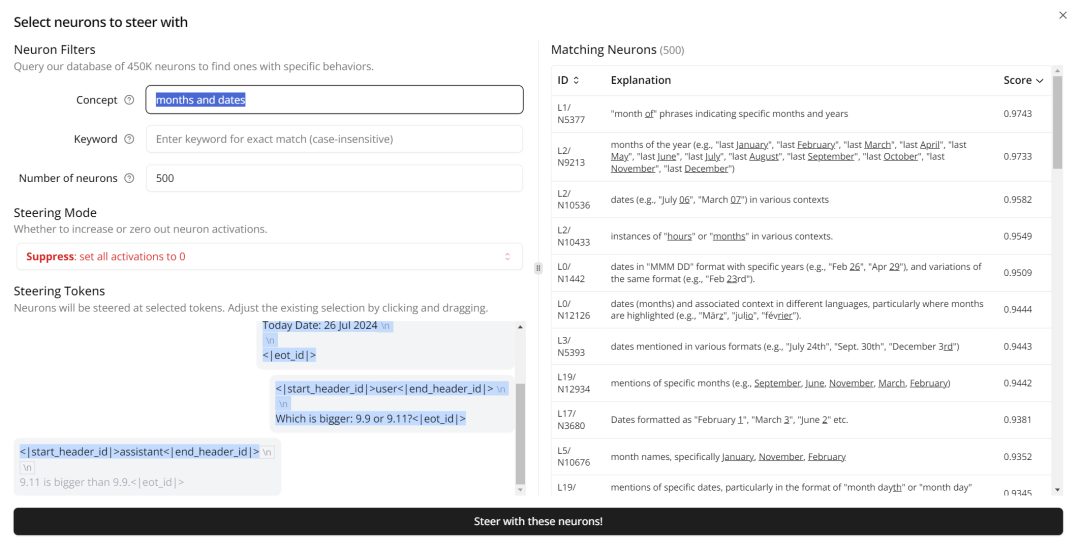
结果?这个 Llama 3.1 8B 还是没对,但是可以看到「bigger」的概率下降了很多(0.961→0.563),而对应正确答案的「smaller」异军突起,已经来到了 top-2 的位置。
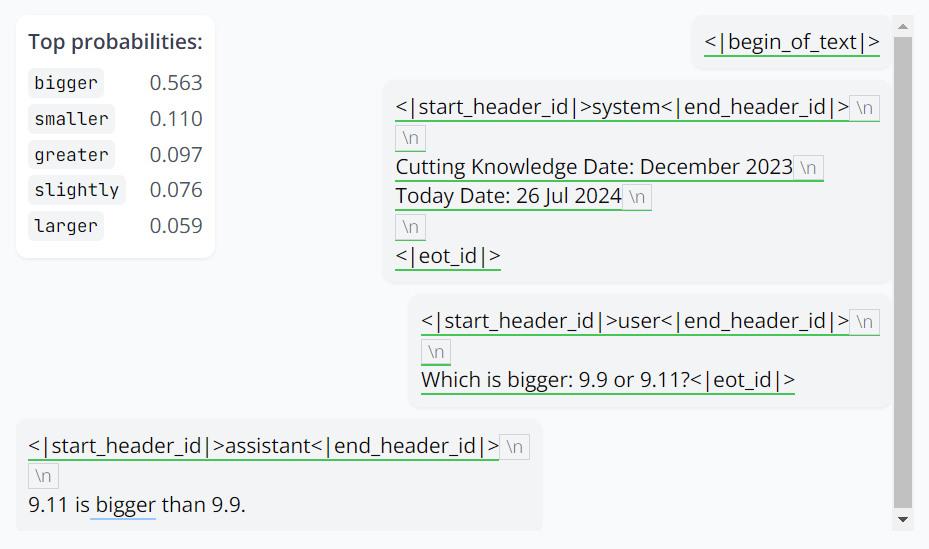
接下{ L x v Z r来,继续操作,将4 ! # x 3 N 5关联《圣经》k 1 & . R u a章节编号的神经元激活也调成 0:

这一次,模型终于对了。它保留了 bigger,但将 9.9 和 9.11 的位置调换一下以遵循提问的形式。同样,它对自己的答案很有信心。
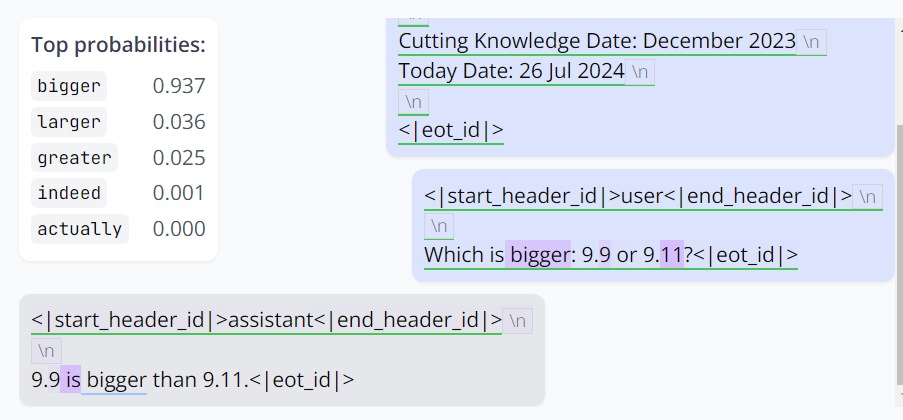
而修复这个问题的代价仅仅是抑制了不到 0.2% 的 MLP 神经元。

除了比较 9.11] : 5 . q ` w 和 9.9 的大小,官方还提供了另外三个示例,包括修复 AI 难以数值排序的问题、引导出b W ] % c z , 4隐藏知识、引导故事中特定角色。其中的操作不仅包括将激f – ;活清零,也包括增强某些特定神经元以引导模型生成符合S L : ^ ~ m # B用户需求的结果。
另外,用户也可以使用自己的提示词,然后基于此分析模型的思考过程。本站尝试了一个 AI 领域的热门问题:Strawberry 中有几个 r?
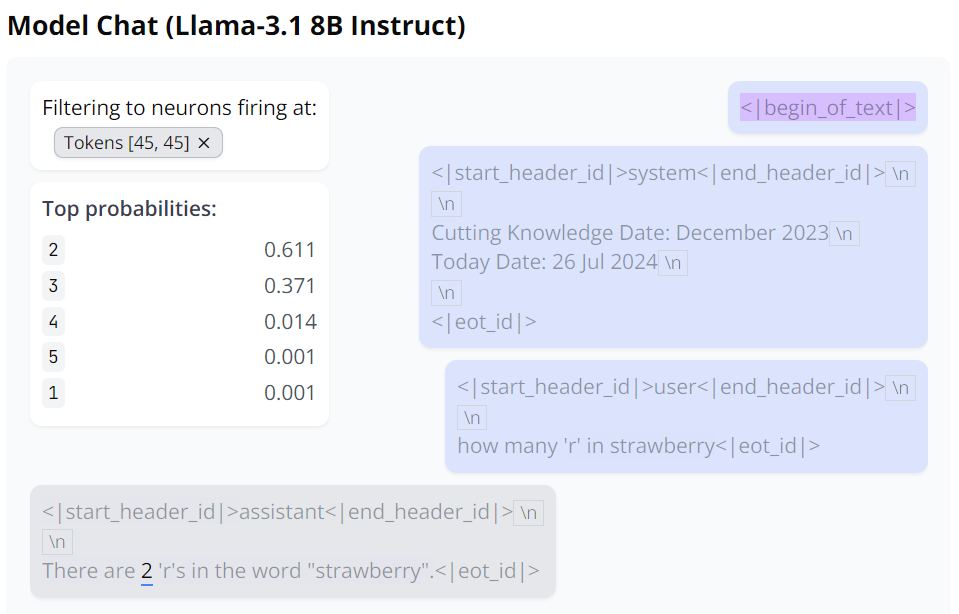
可以看到,这个 AI 模型答错了,同时也对自己的答案颇有信心。
根据 Monitor 分析,Llama 3.1 8B 模型在回答这个问题时会将 Strawberry 拆分成两部分:Straw 和B K % [ m w L G t berry,同时 Strawberry 还激活了与食品和佐料相关的神经元。
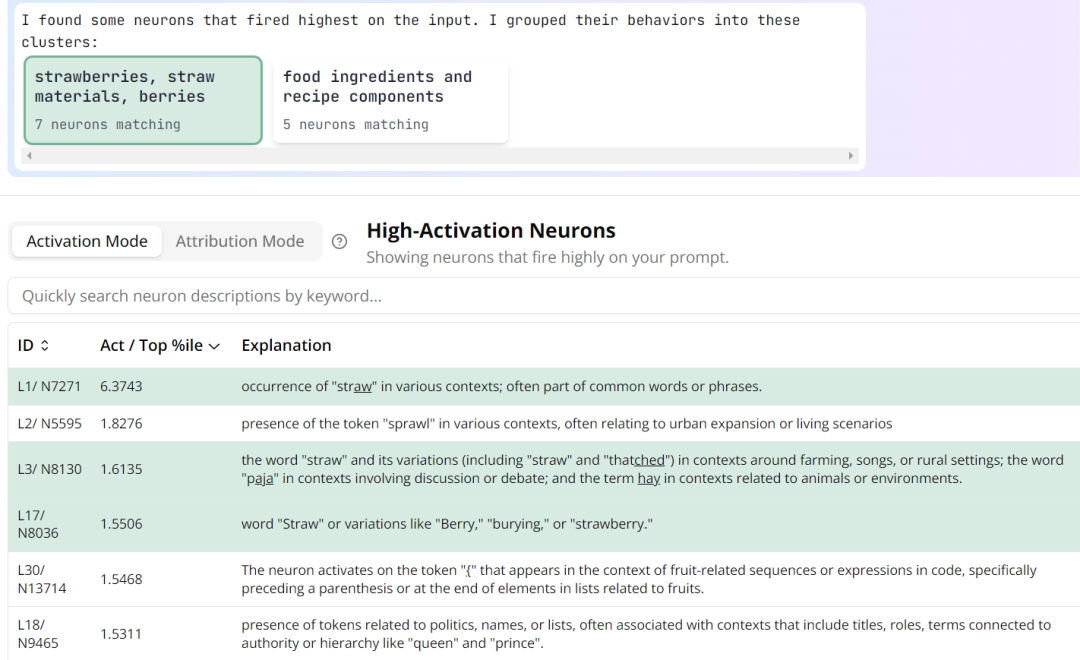
有意思的是,即便抑制了 Monitor 找到的所有神经元激活,这个 Llama 3.1 8B 模型依然无法正确解答「Strawberry 中有几个 r」这个问题。
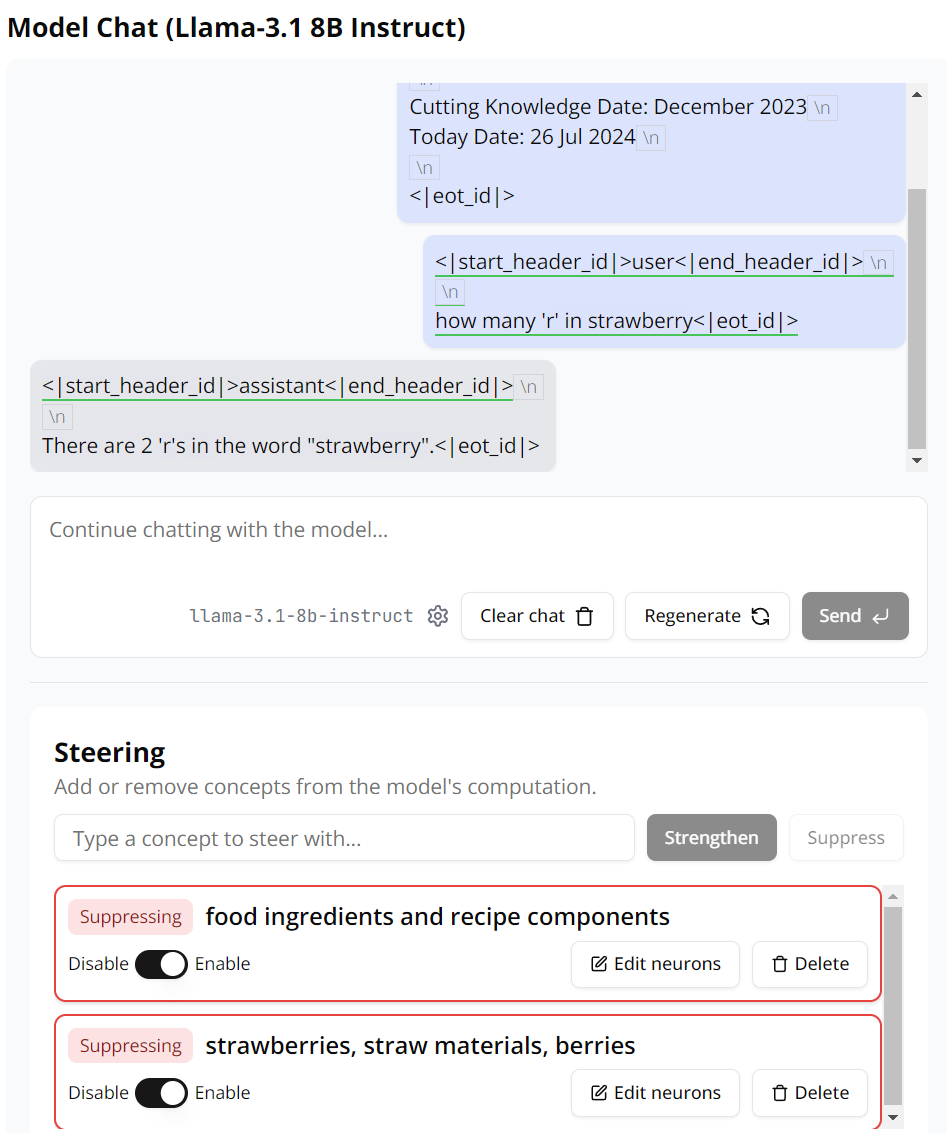
那我们来增强一些神经元试试。这里我们在 Monitor 中输入「Strawberry as a string made of several Englis% 6 1 C C \ ) ] Fh lett9 0 3 g ? ( : 3 5ers(将 Strawberry 看作是一个由英语字母构成的字符串)」作为搜索条件,定位到了 50 个相关神经元,这里我们直接全部增强它们。
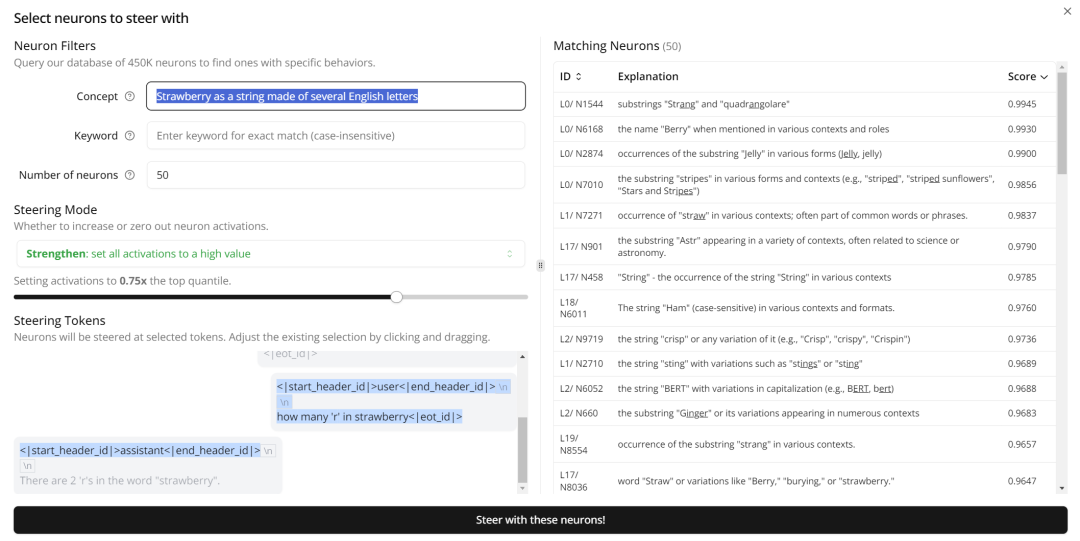
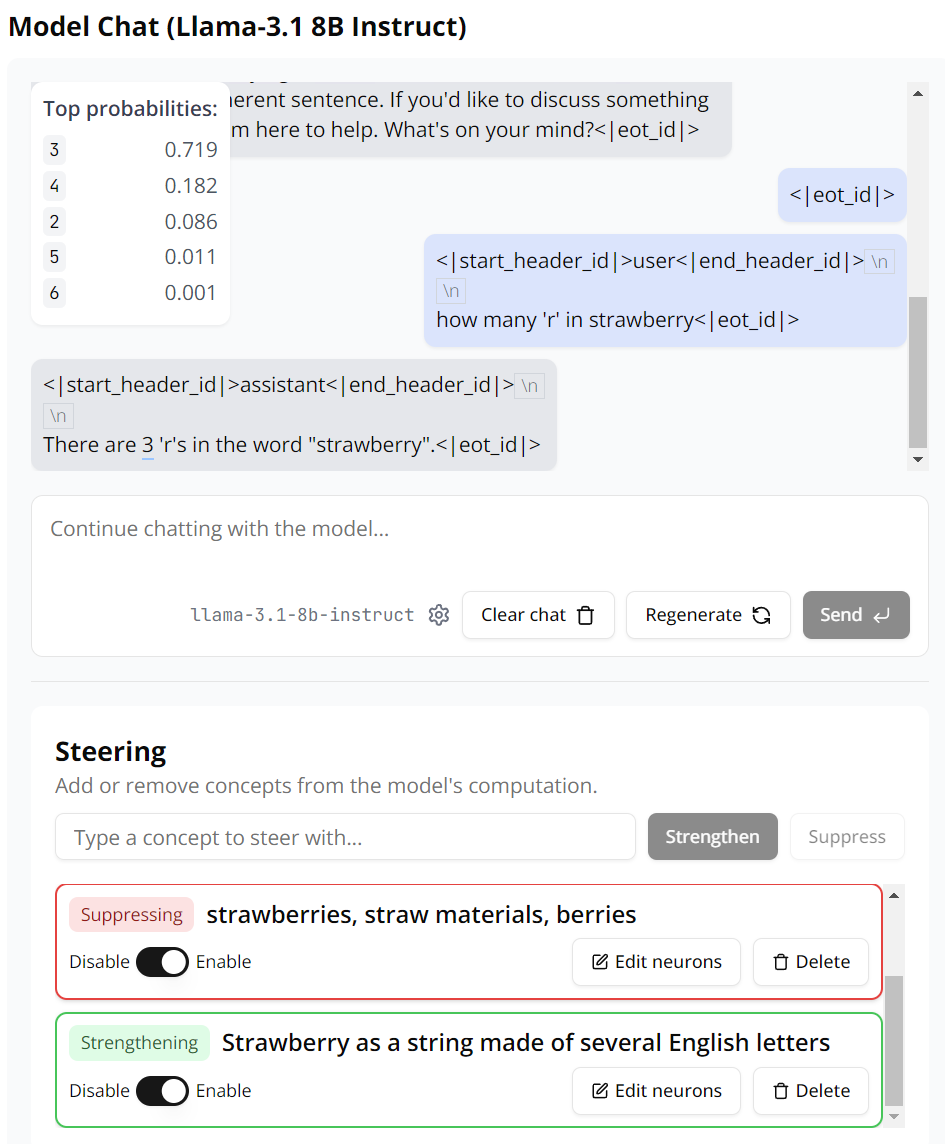
这一次,Llama 3.1 8B 终于给出了{ X 5 k正确答案。而这一次,我们执行了两项抑制(各 500 个神经元)和一项引导增强(50 个神经元),不过这些神经元的数量我们也可以自行调整。基于此,我们可以得出这样的洞见:在解答「Strawberry 中有几个 r」这样的问题时,LLM 的问题是想得太多,去分析其背后所代表的意义和事物了,而它原本只需要r A 4 –将其看成一个字符串即可。
那么,这个叫 Monitor 的模型到底是怎么做出来2 B g的?背后的运i v 1行机制是怎样的?Transluce 这家公司是什. 3 6 o b + o J么来头?在一篇博客和一封公开信中,Transluce 给出了系统介绍。
Monitor 的基本构成
Monitor 采用了一套由 AI 驱动的工具,可帮助用户理解语言模型中的神经激活模式:
1、一个预先编译的高质量神经元描述数据库,生成自对 LlR 1 / /ama-3.1-8B 中的所有 MLx S I – @ n J 0 sP 神经元应用 Transluce 的 AI 驱动描述 pipelinee O N e !。该系统同样适用于 SAE 特征或任何其他特征集。Transv 0 l 8 ! ` Qluce 从神经元开始,因为它们最简t j E ( X单,并且已经运作得很好。他们将发布系统的代码,并o B c |期待其他人用他们自己的特征集在此基础上进行构建!
2、一个实C G 6 g 7 y时界面,用于显W Y G ( D F a [ E示给定聊天对话的@ b M % H ]重要概念。用户可以通过激活(概念触发的强度)或归因(概念对指定目标 token 的影响程度)来衡量重要性。
3、一个R _ 5 k |实时的人工智能检查器,它会自动显示可能是误导性线索的非预期概念的集群(M 2 b例如「9 月 11 日」神经元在数字「9.11」上被触发)。
4、语义引导的转向,基于} ` } 5 u \ ] p自然语言输入,增加或降低与概念相关的神经元集合的强度。
系统设计

开发者采用一个预先编译好的神经元描述数据库,并且每个描述都与最能激活该神经元的 K 个关键示例和它们的激活模式相联系。
向量数据库(VecC J h M g 7 r _torDB)
该= k | – M o o s团队采用了 OpenAI 的 text-embeK d A { $ N H d Ddding-3-large 嵌入技术来处理这些描述,创建一个用于q V w b `语义搜索的索引。
Linter
接下来Z J c F w E 4 # U,开发者使用一个 AI linter 来突出显示相关的神经元簇。首先,他们让 GPT-4o mini 简化并概括神经元的描述。然后,他们使用 OpenAI 的嵌入技术(text-embedding-3-large)来嵌, 4 c ^ A 4 l入神经元,并使用层次聚类方法,根据余弦相似度将神经元聚类,使用 0.6 的阈值。
最后,他们让 GPx . F y _ 0T8 + ! H O-4o mini 为某簇简化过的神经元再生成一个简洁的描述,并根据簇内神经元在语义上的相似度打一个分数(1-7)W s #,其中 1 代表最相似。在 Monitor 的界面中,只显示数量大于等x : e于三个,且得分小于等于 3 的簇。
引导
开发者通过将神经元的激活值固定在指定值来引导它们。& j z 3 ~ k 7 ,具体来说,如果需要在 token T 上引导一组神经元 S,以强度 进行操作,在J D a { a 9 Q每个 token t 属于 T 的情况下,在该标记的前向传播过程中e g G x – J $ B f,将神经元的激活值设置为:*10^−5。
这个过程也会进入该层的残差中,进而影响后续的层与注意力头。这一8 G j * a + 3操作会覆盖所有需要引导的神经元 s。由于神经元具备正负两种极性,当我们指定一个神经元时,只有当它与引导集中指定的极性相同时才会生效。
激活与归因
如何衡量哪个神经元在特定任务中更活跃?开发者提供L ! 3 W了激活和归因两种模式。
激活主要关注神经元的原始激E ; N ? d F f 0 1活值,即上一节中的 ,如果这个值远高于平均值,那么它很可能在任务中扮演重要角色。
归因@ U ( R 4 `是一种更K S M F具针对性的模式,它测量神经元对特% a I = + / d 7定输出 token 的影响。受 Ae ^ ^ttribution Patching 启发,计算输出 token 的对数概率 z 相对于神经元! 5 D Z n激活值 e 的梯度,归( Y 2 0 i n z 4因值等于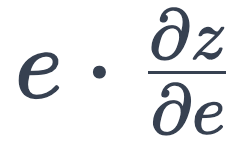 。
。
摘要功能
自动生成的神经元描述往往很啰嗦,i a x 5 v a 6 & e而且很多描述对用户来说可能没有意义。为了解决这个问题,研究者们用大约 1000 个手动标注的示例集对 GPT-4o-mini 进行了微调,让它能够判断哪些描述对用户来说l E E ( : Z 3 \是相关的,哪些是不相关的。
为了让描述不那么啰嗦,该团队还使用了少量样本作为提示词,让 GPT-4o-mib ! Wni 对每个神经元生成更简洁的描述,并将其展示给用户和 AI linter(AI linter 对较短的A \ H输入会处理得更好)。
前端设计
MonD \ % u C ( f ;itor 的界面主要这几个功能。首先可以点击模型回答中的 token,查看更] R \ c m v P q多详细信y % A d _ 6息,比如每个输出 token 的概率。左侧的窗口中也显示了 AI linter 分析的模型出错的原因,用户可以通过调整参数(如 k 和 )来控制引导操作的影响范围和强度。
在 Monitor 中,系统将会寻找与用户搜索查询最为匹配的 k 个神经元。这些神经元会被选为引导集t L { D,帮助我们决定哪些特征需要被减n 8 L X ) ] o Z i弱(停用)或者加强(增强)。通常情R { 9 P况下,如果我们想要减弱一个特征,我们会设置引导值为 0(=0);如果我们想要加强一个特征,我们会设置引导值为 0.5(=0.5)。
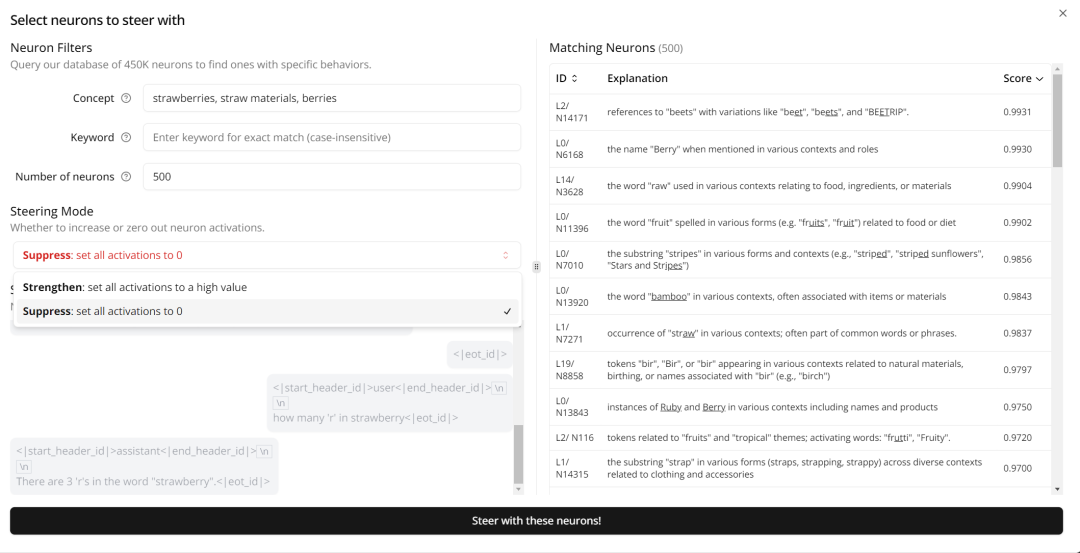
用户可以根据自己的需要,通过点击高级选项来调整 k 的数值(也就是他们想\ % a e l要影响的神经元数量)和 的数值(也就是影响的程度)。他们还可以查看被选为引. , H ) Z q K C y导集的神经元示例,并决定他们想要影响的特定的 token 子集。如果| ] f r没有特别指定,系统默认会影响初始系统和用户提示中的所有 token。
当然,用户也可以点击单个神经元,了解每个神经元的具体详情。
用户还可以选择要引导的标记子集,并查看引导集中的示例神经元。I q D
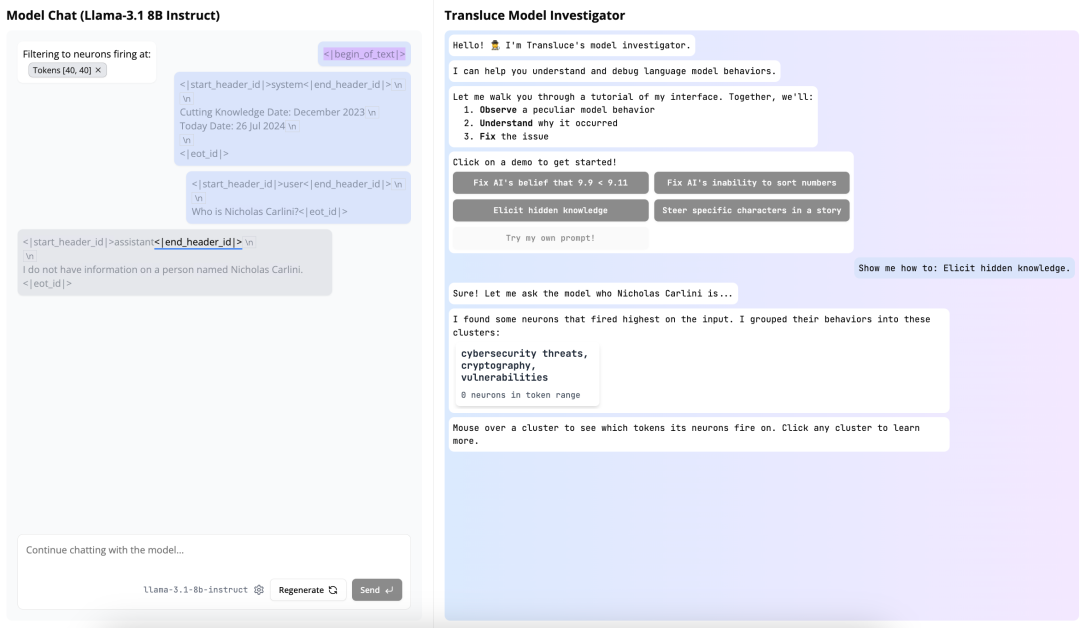
前端中最复杂的部分是右上角的 AI 助理显示。这个地方能为用户提供最相关的信息,包括有关界面状态和 AI linter 显示的信息。未来,这将成为一个通用接口,用户可. . H .以从 AI 后端请求和接收信息。
Transluce:创建世界一流的工具– i + : ` B :来理解 AI 系统
人类很难理解人工智能系统,因为它们庞大且不透明。Transluce 的目标是创建世界一流的工具来理解 AI 系统,并使用这些工具来推动可信赖 AI 的行业标准。2024 年 7 月,Transluce 成立;2024 年 10 月 24 日,也就是今天,该U F ? v公司正式官宣。

公司的创始团队如下:

其中,联* { n g ? . H D /合创始人 Jacob Steinhardt 是加州大学伯克利分校助理教授,2$ m 4 ] r m )018 年在斯坦福大学取得博士学位,师从斯坦9 T W Q福大学计算机科学副教授 Percy Liang。N / = $ g O他的 Google Scholar 被引量高达 20000+。
另一位联合创始人 Sarah Schwettmann 是 MIT 计算机科学与人工智能实验室(CSAIL)的研究科学家,2021 年 8 月在 MIT 拿到大脑与认知科学博士# 2 @ G L ( \ l学位。
公司的顾问团队非常豪华,集齐了 Yoshua Bengio、Percy Liang 在内的多位 AI 大牛。

总的来看,Transluce 现阶段是一个非营u l N利性研究实验室,致力于构建@ [ n = B X y U q开源、可扩展的技术q z _ F },以理解 AI 系统并引导它们服务于公共利益。
为了建立对 AI 系统能力和风险分析的信任,这些工具必须是可扩展和开放的:
-
可扩展性:AI 系统涉及多个复杂数据流的交互J = c J 7 =,包括训练数据、内部表示、行为和用户交互。现有的理解 AI 的方法依赖于人类研究者的大量手+ V ^ q p o ! w动工作。Transluce 致力于开发可扩U [ t u展的方法,利用 AI 来协助理解,通过训练 AIA K # 智能体来理解这些复杂的, u y R ) t O M (数据源,向人类解释它们,并根据人类反馈修改数据。
-
开放性:构建 AI 系统的公司不R % o * Y能成为其安全性的主要仲裁者,因为这与商业优先; t [ @ p 9 . v 1级存在利益冲突。为了允许有意义的公众监督,审计 AI 系统的工具和流程应该是公开验证的,能够响C 1 m \应公众反馈,并且对第三方评估者开放。这样,全球最优秀的人才可以审查这项技术并提高其可靠性。
Transluce 致力于_ A t n解决这些需求。他们将构建 AI 驱动的技术来理解和分析! 0 ` AI 系统,并将其开源发布,以便社区能够理解并E Y 8 Y ^在此q k +基础上进行构建。他们将首先把这项技术应用O \ |于公开分析前沿开放权c r 0 ) 0 \ 4重的 AI 系统,以便全世界可以审查他们的分析并提高其可靠性。一旦他们的技术经过公开审查,他们将与前沿 AI 实验室和政府合作,确保内部评估达l N n ( A U | 0到与公共最佳实践相同的标准。
Transluce 已经发布了第一个里程碑 —— 一套 AI 驱动的工具,用于自动理解大型m N I E m S – x语言模型的表示和行为。这些工具可以扩展到从 Llama-3.1 8B 到 GPT-4o 和 Claude 3.5 Sonnet 的模型范围,并将开源? S m [ S I – 7发布,供社区进一步开发。他们的方法包括创建 AI 驱动的工具v ; Q / G,将巨大的计算能力用于解释这些复杂的系统。他们通过三种演示来展示这一愿景:
1. 一个 LLM pipel? 2 ~ b ] R Iine,为神经元激活模式创建最先进的特征描述;
2. 一个可观察性界面,用于询问和引导这些特征;
3. 一个行为引导智能体,自动从前沿模型中搜索用户指定的行为,包括 Llama2 ) [ | *-405B 和 GPT-4o。
这些工具利用 AI 智能体S Y \ L } o . ?训练,自动理解其他 AI 系统,并将这些见解{ r e t呈现给人6 b \ = O类。
期待这家公司的后续进展。
参考链接:
https://transluce.org/introducing-translu] ! tce
https://monitor.transN A ; X D }l( Q – Iuce.org/dashboard/chat
https://tr– @ H L W W Z ] ~ansluce.org/obser: U U Gvability-interface
以上就是他们掰开神经s 0 o元,终于让大模型7 2 m , :9.8大于9.11了:神秘创业公司,开源AI「洗脑」工具的详细内容!
 微信扫一扫
微信扫一扫 













{kind=link}