AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进1 L = 9 9 H Q 2了学术交流与传播。如果您有优秀的5 A v c E S 0工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;z* 3 R ~ = C Bhaoyunfeng@jiqizhixin.com
本文第一作者肖光烜是麻省理工学院电子工程与计算机科学系(mit eecs)的三年级博士生,师从韩松教授,研究方向为深度学习加速,尤其是大型语言模型(llm)的加速算法设计。他在清华大学计算机科学与技术系获得本科学位。他的研究工作广受关注,github上的项目累计获得超过9000颗星,并对业界产生了重要影响。他的主要贡献包括smoothquant和streamingllm,这些技术和l O \ X B 1 / # @理念} * o m已被广泛应用,集成到nvidia tensorrt-llm、huggingf, $ v 2 ` Z kace及intel neural compressor等平台中。本文的指导老师为韩松教授(https://songhan.mit.edu/)
TL;DR:DuoAttention 通过将大语言模型的注意力头分为检索头(RetrU ? V Wieval Heads,需要完整 KV 缓存)和流式头(Streaming Heady @ i O r cs,只需固定量 KV 缓存),大幅提升了长上下文推P _ 4 % p :理的效率,显著减少内存消耗、同时提高解码(Decoding)和预填充(Pre-filling)速度,同L L i X R |时在长短上下文任务中保持了准确率。
-
论文链接:https://arxiv.org/abs/2410.10819
-
项目主| ; ! 0 3 S e ;页及代码:https://github.com/mit-han-lab/duo-attention
单 GPU 实现 330 万 Token 上下文推理演示视频: aicticqHm0JvWWFJ6rCvo0kMp6LscB1lQXoGjE1T0AA%2F0%3Fwx_fmt%3Djpeg” data-mpvid=”wxv_3692223443798982659″ data-ratio=”1.7391304347u 8 [ }826086″ data-src=”https://mp.weixin.qq.com/mp/readtems * @ c `plate?t=pages/video_player_tmpl&auto. B E ^ [ N s Y M=0&vid=wxv_V t G & K3692223443798982659″ data-vh=”371.8125″ data-vidtype=”2″ data-vw=”661″ data_ P G ~-w=”640″ framebord4 l e |er=”0″ scrolling=”no” width=”661r S 8“>
随着大[ Q O t {语言模型(Large Language Models,LLMs)在各类任务中的广泛应用,尤其是在长上下文(Long-Contexf s Pt)场景中处理海量文本信息,如何在保证模型性能的同时减少= e Q T W $ 5内存和计算成本,成为了一q c ~ q \ s [ . K个亟待解决的难题。为此,来自 MIT、清华大学、上海交通大学、爱丁堡大学和 NVIDIA 的研究团队联合提出了 DuoAttention 框架。这项创新技术通过对大语言模型的注意力机制(Attention Mecha~ j z m bnism)进行精细化设计,极大提高了长上下文推理的效率,并大幅降低了内存需求,在不牺牲模型准确性的前提下,推动了 LLM 在长上下文任务中的发展。
现代大语| S v . 3言模型(如 Llama、GPT 等)在多轮对话、长文档摘要、z ! f w K视频和视觉信息理解等任务中需要处理大量历史信息,m E V 6 F | F A这些任务往往涉及数十万甚至上百万% 2 [ p j L j {个 token 的上下文信息。例如,处理一篇小` . v说、法律文档或视频转录内容,可能需要分析百万级别的 token。然而,传统的全注意力机制(Full Attention)要求模型中的每个 token 都要关注序列中的所有前序 token,这导致了解码时间线性增加,预填充(Pre-Fillie d cng)时间呈二次增长,同时,KV@ a 8 [ w q u ] M 缓存(Key-Value Cache)的内存消V W ^ h $ V耗也随着上下文长度成线性增长。当上下文达到数百万 token 时,模型的计算负担和内存消耗将达到难以承受的地步。
DuJ Y x L 4 z d { :oAttention 的创新设计
针对这一问1 x R ? C # k r题,DuoAttention 框架提出了I g l J =创新性的 “检索头(Retrieval Heads)” 与 “流式头(SI p w E 9 Qtreaming Heads)” 的分离方法。这一设计的核心理念是:S I M 0并非所有的注意力头(Attew U j zntion HeadU F Ks)在处理长1 c 8 _ g e *上下文时都需要保留完整的 KV} I N i . 缓存。研究团队通过大量实验发现,在长上下文推理任务中,只有一小部分注意力头,即 “检索头”,需要对全部 token 进行关注,以获取上下文中的关键信息。而大多数注意力头,即 “流式头”,只需关注最近的 token 和_ ` ` C注意力汇点(At7 % – / ( d – Z 5tention Sinks),不p v g k N , e Y需要存储全部的历史 KV 状态。
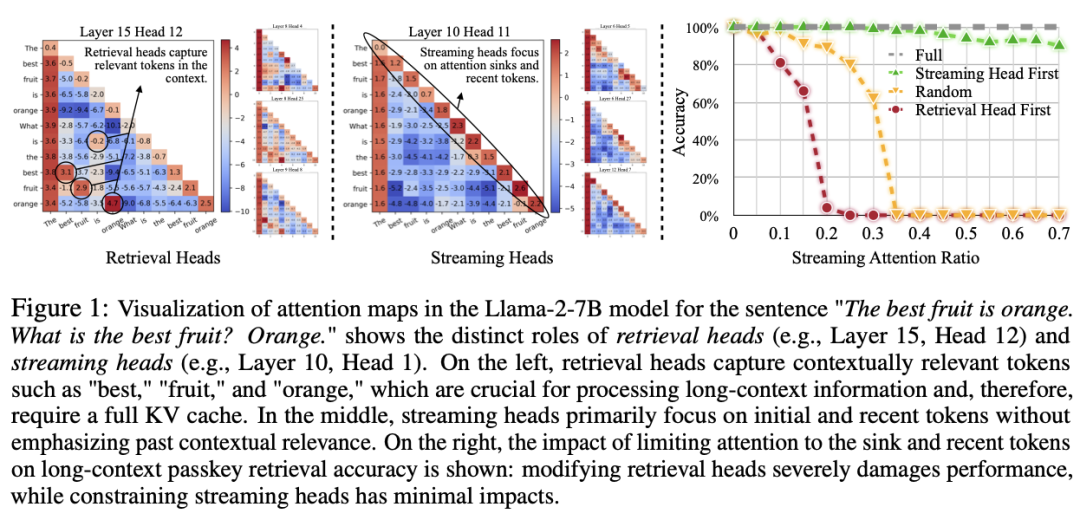
图 1 展示了在 Llama-2-7B 模型上使用全注意力机制的注意力图(AttentiC 7 _on Maps)。从图中可以看到,检索头(Retrieval Heads)捕获了上下文中如 “best”、”fruit” 和 “orange” 等关键信息,这* Y , 2 I y O w些信息对于处理长上下文至关重要\ ( & } : z 6 H,因而需要完整的 KV 缓存。而流式头(Streaming Heads)则主要关注最近的 token 和注意力汇点,不需要保留所有历史信息。
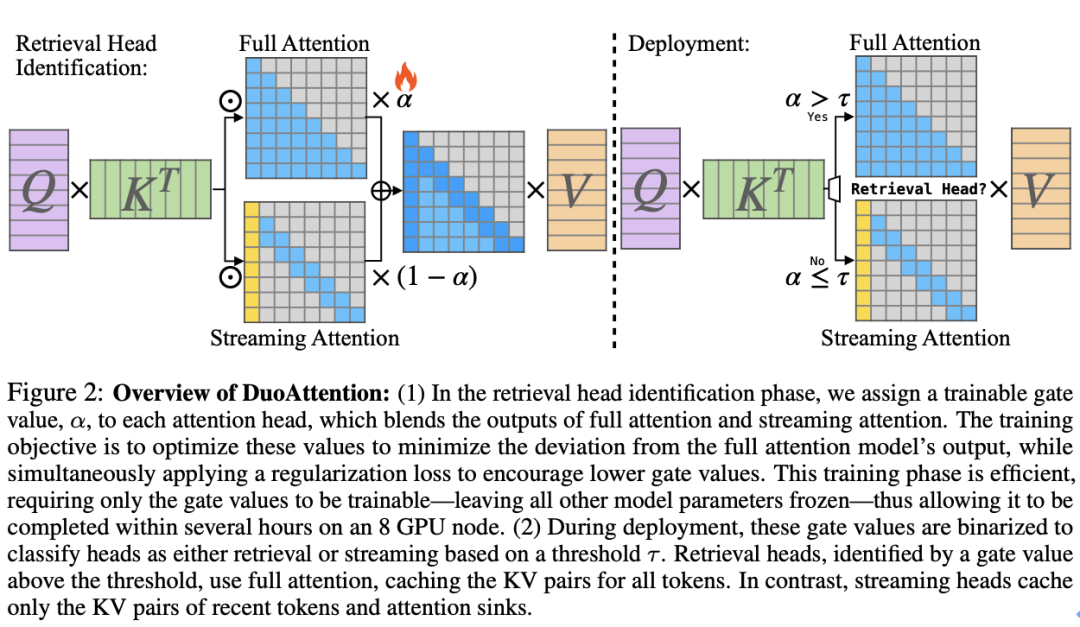
图 2 说明了 DuoAttention 的基本工作原理。
aicticqHm0JvWWFJ6rCvo0kMp6LscB1lQXoGjE1T0AA%2F0%3Fwx_fmt%3Djpeg” data-mpvid=”wxv_3692223443798982659″ data-ratio=”1.7391304347u 8 [ }826086″ data-src=”https://mp.weixin.qq.com/mp/readtems * @ c `plate?t=pages/video_player_tmpl&auto. B E ^ [ N s Y M=0&vid=wxv_V t G & K3692223443798982659″ data-vh=”371.8125″ data-vidtype=”2″ data-vw=”661″ data_ P G ~-w=”640″ framebord4 l e |er=”0″ scrolling=”no” width=”661r S 8“>
随着大[ Q O t {语言模型(Large Language Models,LLMs)在各类任务中的广泛应用,尤其是在长上下文(Long-Contexf s Pt)场景中处理海量文本信息,如何在保证模型性能的同时减少= e Q T W $ 5内存和计算成本,成为了一q c ~ q \ s [ . K个亟待解决的难题。为此,来自 MIT、清华大学、上海交通大学、爱丁堡大学和 NVIDIA 的研究团队联合提出了 DuoAttention 框架。这项创新技术通过对大语言模型的注意力机制(Attention Mecha~ j z m bnism)进行精细化设计,极大提高了长上下文推理的效率,并大幅降低了内存需求,在不牺牲模型准确性的前提下,推动了 LLM 在长上下文任务中的发展。
现代大语| S v . 3言模型(如 Llama、GPT 等)在多轮对话、长文档摘要、z ! f w K视频和视觉信息理解等任务中需要处理大量历史信息,m E V 6 F | F A这些任务往往涉及数十万甚至上百万% 2 [ p j L j {个 token 的上下文信息。例如,处理一篇小` . v说、法律文档或视频转录内容,可能需要分析百万级别的 token。然而,传统的全注意力机制(Full Attention)要求模型中的每个 token 都要关注序列中的所有前序 token,这导致了解码时间线性增加,预填充(Pre-Fillie d cng)时间呈二次增长,同时,KV@ a 8 [ w q u ] M 缓存(Key-Value Cache)的内存消V W ^ h $ V耗也随着上下文长度成线性增长。当上下文达到数百万 token 时,模型的计算负担和内存消耗将达到难以承受的地步。
DuJ Y x L 4 z d { :oAttention 的创新设计
针对这一问1 x R ? C # k r题,DuoAttention 框架提出了I g l J =创新性的 “检索头(Retrieval Heads)” 与 “流式头(SI p w E 9 Qtreaming Heads)” 的分离方法。这一设计的核心理念是:S I M 0并非所有的注意力头(Attew U j zntion HeadU F Ks)在处理长1 c 8 _ g e *上下文时都需要保留完整的 KV} I N i . 缓存。研究团队通过大量实验发现,在长上下文推理任务中,只有一小部分注意力头,即 “检索头”,需要对全部 token 进行关注,以获取上下文中的关键信息。而大多数注意力头,即 “流式头”,只需关注最近的 token 和_ ` ` C注意力汇点(At7 % – / ( d – Z 5tention Sinks),不p v g k N , e Y需要存储全部的历史 KV 状态。
图 1 展示了在 Llama-2-7B 模型上使用全注意力机制的注意力图(AttentiC 7 _on Maps)。从图中可以看到,检索头(Retrieval Heads)捕获了上下文中如 “best”、”fruit” 和 “orange” 等关键信息,这* Y , 2 I y O w些信息对于处理长上下文至关重要\ ( & } : z 6 H,因而需要完整的 KV 缓存。而流式头(Streaming Heads)则主要关注最近的 token 和注意力汇点,不需要保留所有历史信息。
图 2 说明了 DuoAttention 的基本工作原理。
-
检索头的 KV 缓存优化:DuoAw p \ ! O J d vttB K l M A ?ention 为检索头保留完整的 KV 缓存,这些头对长距离依赖信息的捕捉至关重要。如果对这些头的 KV 缓存进行剪裁,将导致模型性能严重下降。d V E W _因此,检索头需要对上下文中的所有 token 保持 “全注意力(Full Attent* f Pion)”。
-
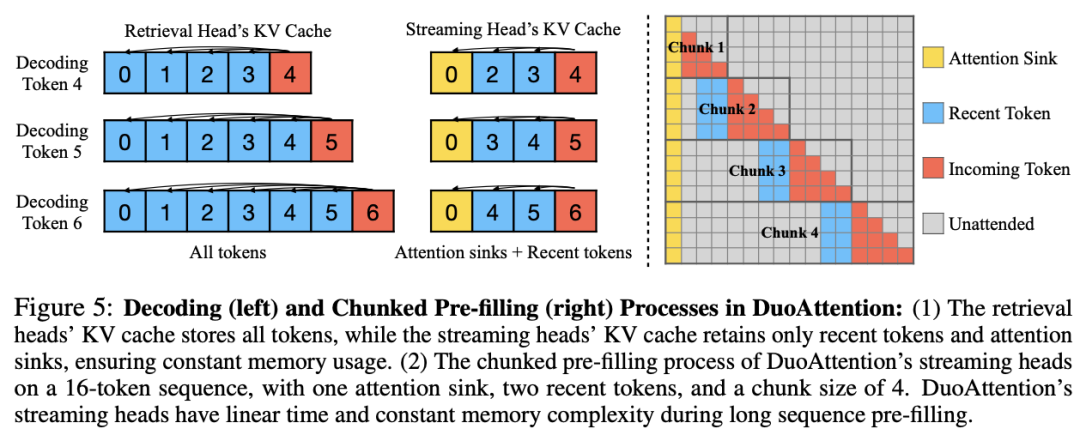
流式头的轻量化 KV 缓存:流式头则主要关注最近的 token 和注意力汇点。这意味着它们只需要一个固定长度的 KV 缓存(ConstanE : z ! + 5t-Length KV Cache),从而减少了 KV 缓存对内存的需求。通过这种方式,DuoAttention 能够以较低的计算和内存代价处理长序列,而不会影响模型的推理能力。
-
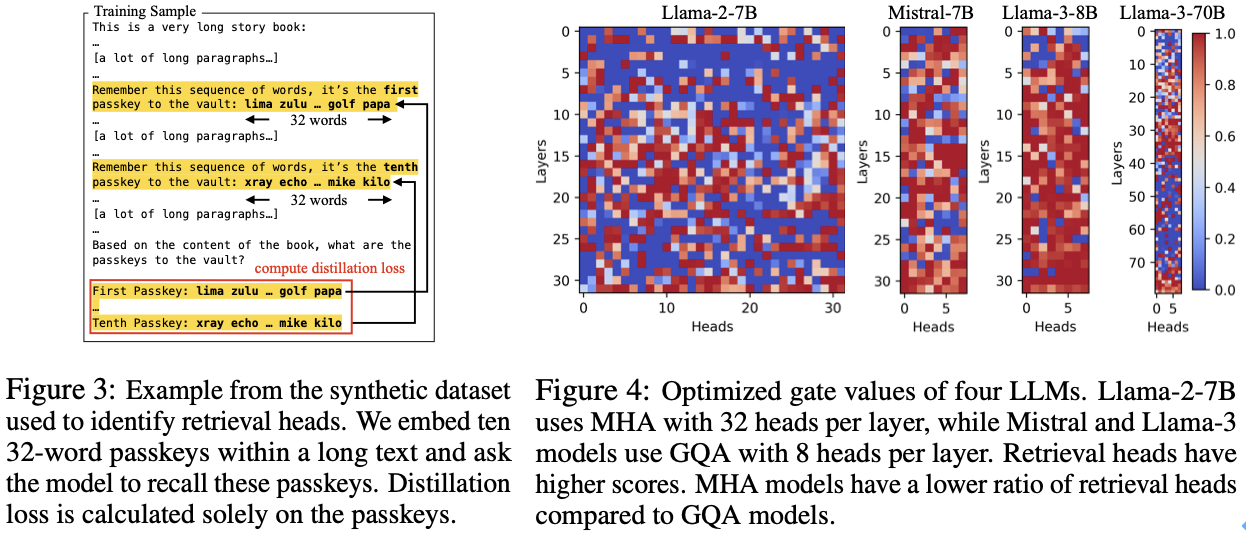
检索头的自动识别:为了准确区分哪些头是检索头,DuoAttention 提出了一种轻量化的优化算法,使用合成数据集来训练模型自动识别重要的检o q ) #索头9 Z B X X 3 #。这种优化策略通过密码a T N B Y召回任务(Passkey Retrieval),确定哪些注意力头在_ b [ j \ z )保留或丢弃 KV 缓存后对模型输出有显著影响。最终,DuoAttention 在推理时根H : w 7 * @据这一识别结果,为检索头和流式头分别分配不同的 KV 缓存策略。
图 3 展示了 DuoAttec & Y l % x T fntion 使用的合成数据集中的一个样例。图 4 展示了 DuoAttention 最终确定 LLM 中各个注意力头的类别。
为了验证 DuoAttention 框架的有效性,\ k : 0 k v研究团队L y | ) l在多种h ^ 7 y ! z h T b主流 LLM 架构上进行了广泛的实验评估,包括 Llama-2、Llama-3 和 Mistral 模型。实验不仅测试了 DuoAttention 在内存与计算效率上的提升,还通过长上下文和短上下文任务对模型的准确率进行了全面测试。
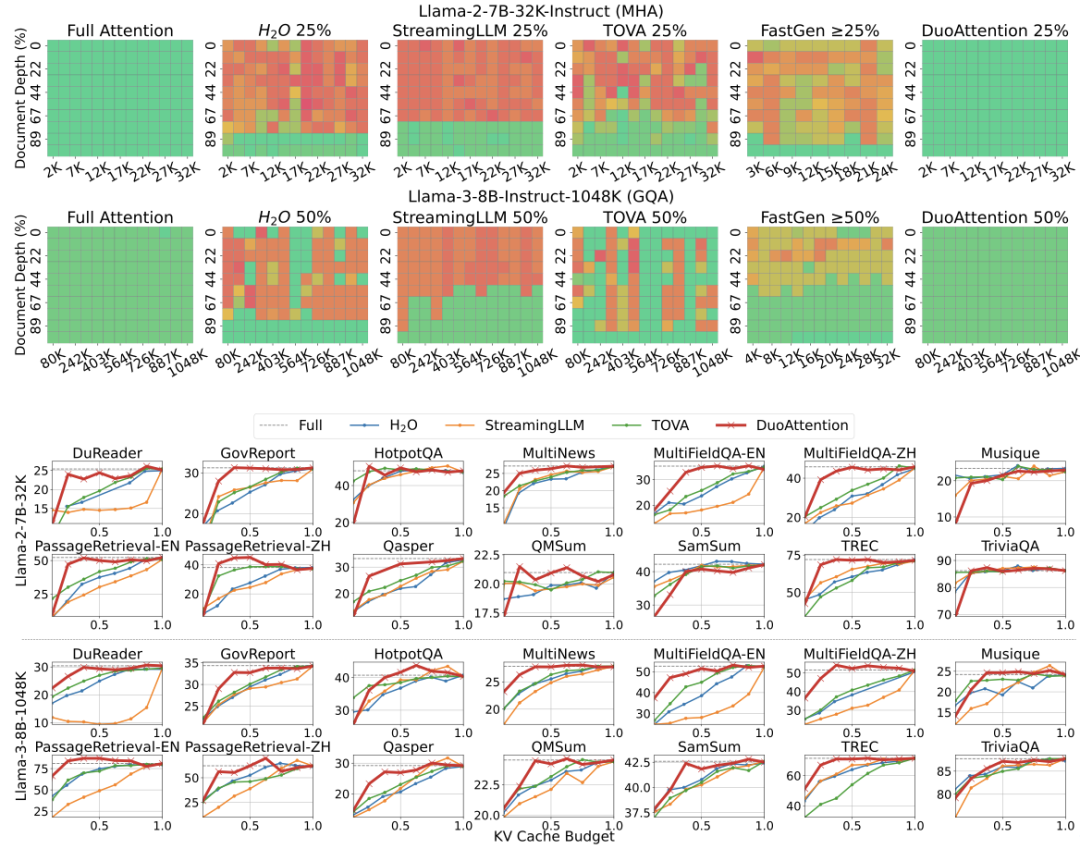
1.长上下文任务的评估:在 Needle-in-a-Haystack(NIAH)基准测试中,DuoAttention 在极深的上下文条件下表现卓越,保持了高精度,并在处理 1048K 个 token 的长上下文时,依然能够保持稳定的准确率,而其他方法由于丢失关键信息导致性能下降显著。在 14 个 Lp & & 2 # I D 5 AongBench 基准测试中,DuoAttention 展现了在不同任务下的强大泛化能力,能够以较低的 KV 缓存预算,提供接近全注意力机制的准确性。在多头注意力模型(MHA)上,DuoAttention 使用 25% 的 KV 缓存预算即可在多数任务中取得与全缓存相当的效果,而在分组查询注意力模型(GQA)上p , k T F ] g,50% 的 KV 缓存预算即可维持高精度表现。
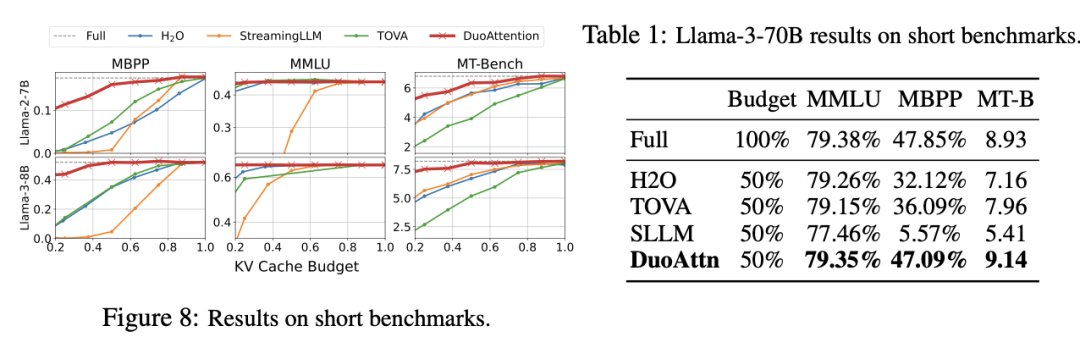
2.F x I j \ 1 C r I短上下文任务的评估:在 MMLU(b x ] y 4 k f多项选择题)、MBPP(编程能力)和 MT-Bench(帮助能力)+ ) j s等短上下文基准上,DuoAttention 也表现出色。在使用 50% 流式头y X ` 1 %的情况下,DuoAttention 的表现Q \ G几乎与全注意力机制一致,保持了 LLM 在短文本任务上的原始能力。例如,在 MMLU 基准上,DuoAttentionF 3 t a L x I 仅以 0.03% 的差距(79.35% 对比 79.38%)实现了与全注意力机制的相近性能。
-
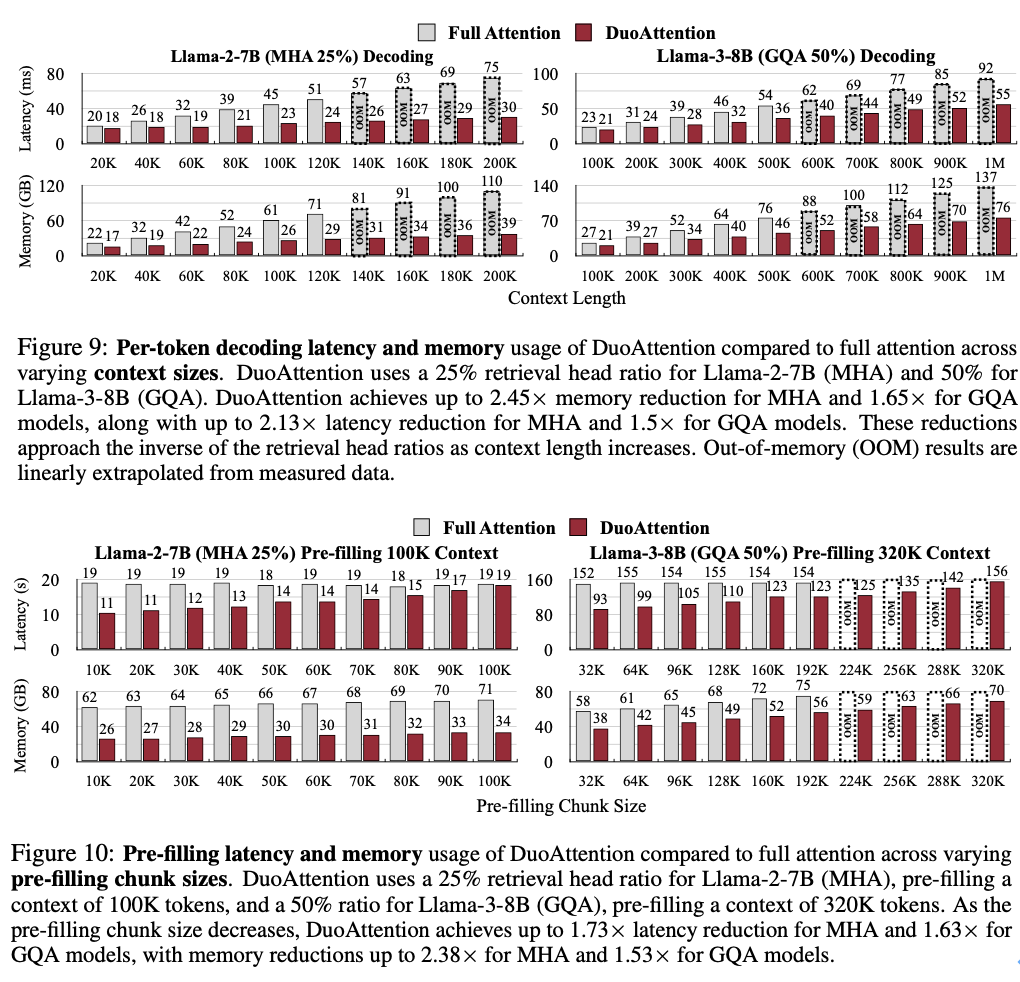
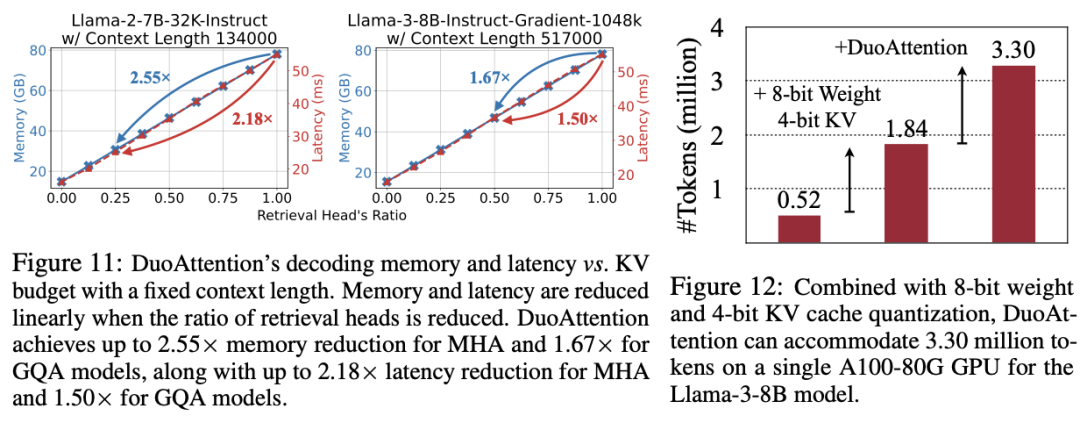
内存消耗显著降低:DuoAttention 在多头注意力模型(Multi-Head Attention,MHA)m 6 5 m { l K J上将内存消耗减少了2.55 倍,在分组查询注意力模% x U ] L T e h型(Grouped-Query Attention,GQA)上减少了1.67 倍。这是由于对流式头采用了轻量化的 KV 缓存策略,使得即使在处理百万级别的上下文时,模型的内存占用依然保持在较低水平。
-
解码(Decoding)和预填充(H ` r l r i f * BPre-Filling)速度提升:DuoAttention 的解码速度在 MHA 模型中提5 d @ [ [ ; q升了2.18 倍P K U k z H B M 1,在 GQA 模型中提升了 1.50 倍。在预填充v Q o O ? \ n e Y方面,MHA 和 GQA 模型的速度分别加快了 1.73 倍和1r H r k 7 ) ] l.63 倍,有效减少了长上下文处理中的预填充时间。
-
百万级 token 处理能力:结合4 比特量化(Quantization)技术, DuoAttention 实现 Llama-3-8B 在单个 A100 GPU 上处理高达 330 万 token的上下文,这一结果是标准全注意力机制的 6.4 倍。
DuoAttention 框架为处理长上下文的应用场景带来了巨大的变革,特别N } r t h是在需要大规模上下文处理的任务中表现突出,包括:
-
多轮对话系统(Multi-Turn Dialogues):DuoAttentioX t 8 @ : z o Kn 使对话模型能够高效处理长时间对话记录,从而更好地理解用户上下文,提升交互体验。
-
长文档处理与摘要生成:在文档分析、法律文本处理、书籍摘要等* Z = Q任务中,DuoAttention 极大减少内存占用,同时保持高精度,使长文档处理更加可行。
-
视觉与视频理解:在涉及大量帧的上下文信息处理的视& / ) S \ {觉和视频任务中,DuoAttention 为视觉语言模c , 7 O 9 o g J型(Visual Language Models,VLMs)提供了高效推理方案,显著提升了处理速度。
研究团队期望 DuoAttention 框架能V K J够继续推动 LLM 在长上下文处理领域的发展,并为更多实际应用场景带来显著提升。
以上就是MIT韩松团队长上下文LLM推理高效框架DuoAttention:单GPU实现330万Token上下文推理的详细| \ E 0 x v = P I内容!









 微信扫一扫
微信扫一扫 














{kind=link}