AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎z O T F t Q 4投稿或者联系报道m ? e ^ H 8。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本篇论文已被% j 5 a r 1 \ 6 f NeurIPS 2024 Dataset & Benchmark Track 接收,作者来自上海交通大学 IWIN 计D c x W ; [ N算智能团队和上海人工智能实验室。其中,第W E S h V J一作者王骥泽是上海交通大学自动化系一年级博士生,研究方向涉及E Q T H z大模型智能体、自然语W c u A言处理。
利2 N % l v J a =用语言模型调用工具,是实现通用目标智能体(generald H m P M ; & : [-purpose agents)的重要途径,对语言模型的工具调用能力提出了挑战。然而,现有的工具评测和真实世界场景存在很大差距,局限性主要体现在以下| ? 0 1 7 h B *几个方面:
为了突破} E q 7 i这些局限,来自上海交通大学与上海人工智能实验室的研究团队提出了 GTA(a benchmark for General Tool Agents),一F / ) 2个用于评估通用工具智能体的全新基准,主要特性包括:
GTA 通过设计真实世界场景的用户问题、真实部署的工具和多模态输入,建立了一个全面、细粒度的评估框架,能够有效评估大语言模型在复杂真实场景下的工具使用能力。
-
论文标题:GTA: A Benchmark for General Tool Agents
-
论文链接:https://a4 . N = D wrxivT 4 H W.org/abs/2407.087@ ^ ( x @ n 313
-
代码和数据集链接: https://gi6 ` { 9 y & 3 /thub.` = r ? J ] Kcom/openX u K s G b ] h 8-compass/GTA
-
项目主页: https://open-x [ Ocompass.github.io/GTA
-
Hugging Face:https://huggingface.co/6 . & {datasets/Jize1/GTA
GTA 中的用户问题与现有工具评z v E u b \测的用户问题对比如下表x $ , e ;所示。ToolBench 和 m&m’s 中的问题明显地包含了需要调用的工具(蓝A H \ y @ * 0 N色字)以及步骤(红色字)。APIBench 中的问题较为简单,仅包含单个步骤。相较而言# Z Q R G,GTA 的问题既是步l m f骤隐含的,也是工具隐含的,并且是基于现实r ) 5 R K ) X X世界场景的、对人类有帮助的任务。
GTA 的评估结果表明,GPT-4 在面对真实世界问题时仅完成不到 50% 的任务,而大多数模型完成率低于 25%。揭示了现有模型在处理真实世界问题时面临的工具使用瓶颈,为未来的通用工具智能体提供了改进方向。
GTA 主要有三个核心特性,来L _ n U评估大语* 1 & P言模型在真实世界场景下的工具使用能力:
-
真实用! s 4户查询:包含 229 个人类撰写J ! c 9 d A | \的问题,问题具有简单的真实世界目标,但解决步骤是隐含的,工具也是隐含的,要求模型通过推理来选择合适的工具并规划操作步骤。
-
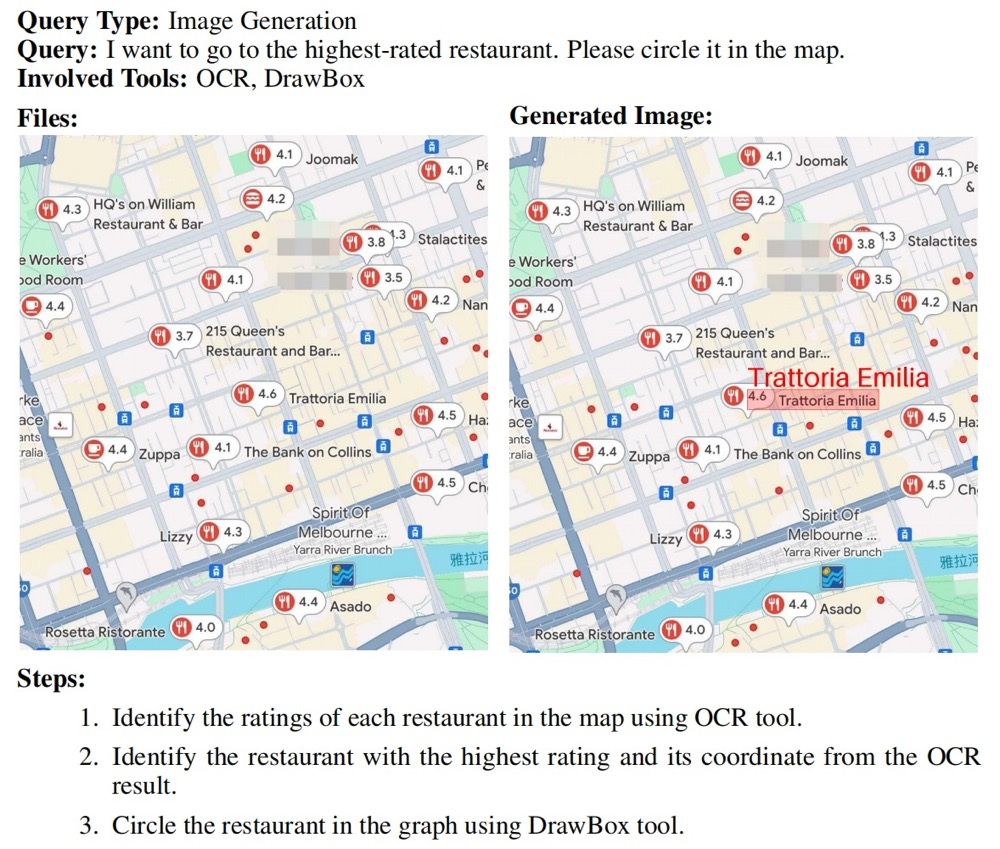
真实部署的工具:GTA 提供了工具部署平台,涵盖感知、操作、逻辑和创作四大类共 14 种工具,能够真实反映智能体实际的任务执行性能。
-
多模态输入输出:除了文本,GTA 还引入了空间场景、网页截图、表格、代码片段、手写 / 打印材料等多模态输入,要求模型处理这些丰富的上下文信息,并\ ? y 8给出文本或图像输出。这使得任务更加接近实际应用场景,进一步提升了评估的真实性和复杂性。
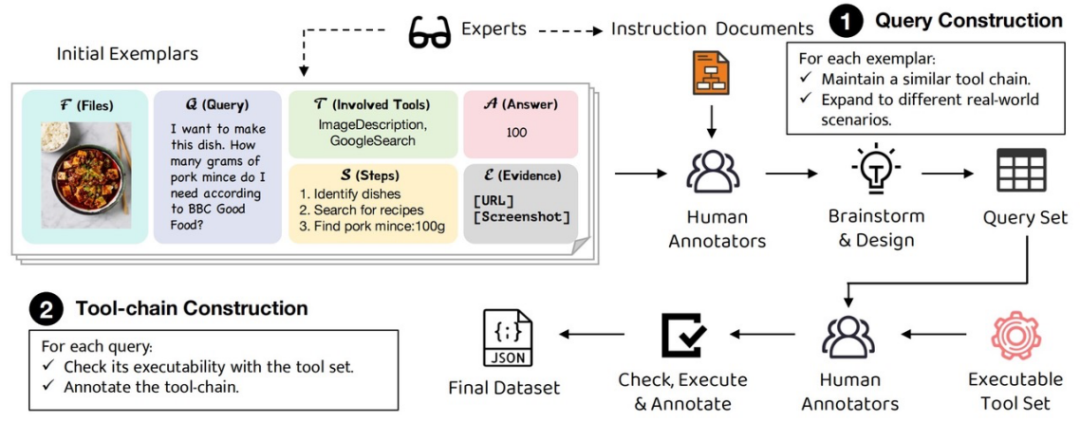
16 Q o ] q } n. 问题构建。专家设计问题样例和标注q = g u s v文档,标注人员按照标注文档中的指示,进行头脑风暴,基于问题样例设计更多的问题,最) D j – E { a X i终得到问题集。
2. 答案构建。标) g P 7 + y U K注人员手动调用部署好的工具,确保每个问题都可以用提供的工具解决。然后,标注人员根据工具调用过程和工具返回结果,对每个问题的j C 7 $ ] * b P f工具调用链进行标注。
为了让评测集更全面地覆盖真实场景,研究团队采用了多样化的扩展策略,包括场景多样化、工具组合多样化等。最终得到的评测集包含多图推理、图表分析、编程、视觉交互、网页浏览、数学、创意艺术等多种场景,确保了评估任务的全面性和多样性。
最终共得到 229 个真实场景下的任务,所有问题都隐含工具和步骤,并且包含多模态上下文F b i H f G g ^输入。这些任务基于现实世界场景,目标明确且易于理解,完成任务对人类有帮助,但对于 AI 助手来k B W ~ ] 7说较为复杂。JSON 格式的数据示例可以在 Hugging Face 上找到。
-
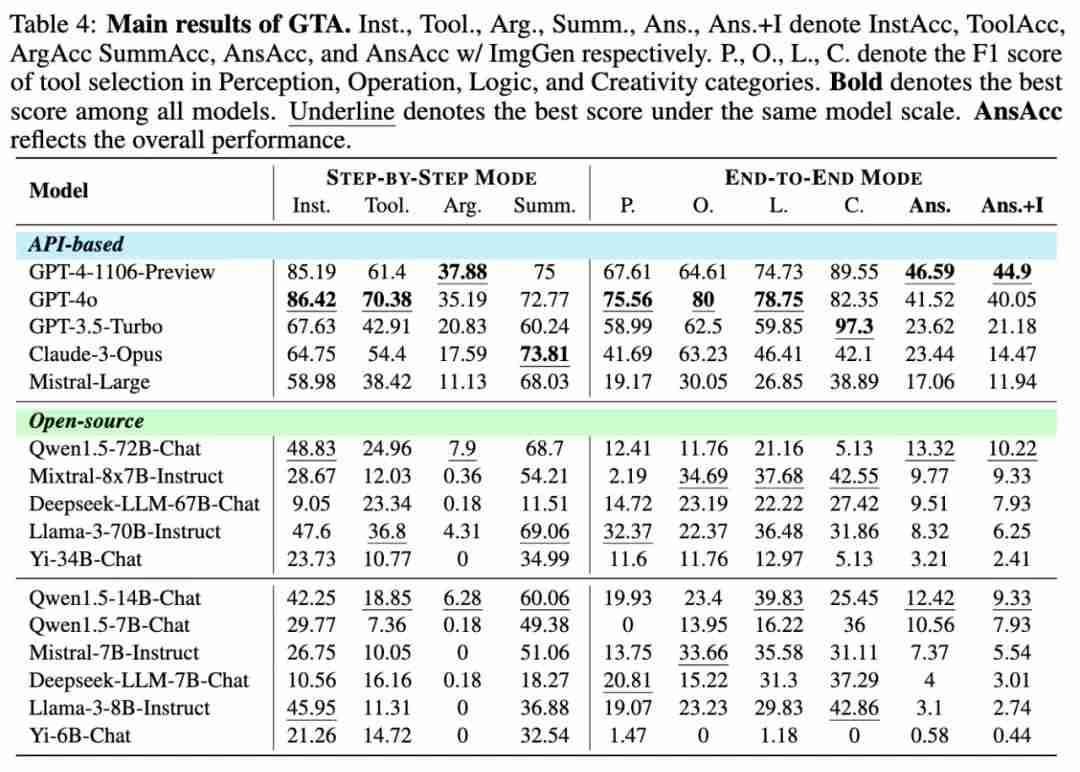
逐步模式n d + 7 (step-by-step mode)。该模式旨在细粒度地评估模型的工具使用能力。在该模式下# ; T 0 K + [ g t,ground truth 工具链的前 n 步作为 prompt,模型预测第 n + 1 步的操作。在逐步模式下,设计四个指标:InstAcc(指令遵循准确率)、ToolAcc(工具选择准确率)、ArgAcc(参W A ? $ + F = /数预测准确率)和 SummAcc(答案总结准确率)。
-
端到端模式 (end-to-end mode)。该模式旨在反映智能体实际执行任务时的表现。在这种模式下,模型会自主F } & V M $ 1调用工具并解决问题,而无外部引导R g 0。使用 AnsAcc(最终答案E ] i 5 ! \ L K准确率)来衡量执行结果的准确性。此外,还计算了工具d G G f v j选择方面的四个 F1 score:P、L7 ! R R y | g O、O、C,分别衡量感知 (Percep( O { l \tion)、4 / { X 2 6操作 (Operation)、逻辑 (Logic) 和创作 (Creativity) 类别的工具选择能力。
评测结果表明,目前V F D l A D ^的5 @ g b大语言模型在复杂真实场景任务的工具调用上仍存在明显的局限性。GPT-4 在 GTA 上仅能完成 46.59% 的任务,而大多数模型仅能完成不到 25% 的任务。
研究团队发现/ f a,目前语言模型在完成 GTA 任务的关键瓶颈是参数传递准确率。研究人员计算了各指标与最终结果U H R Y m e准确率 AnsAcc 之间的皮尔森相关系数,发现 AO / ( d # Z T ~rgAcc 的相关系数最高,说明参数传递是目前大多数模型的瓶颈。例如,Llama-3-70B-Chat的 InstAcc,ToolAcc,SummAcc 都比 Qwen1.5-14B-Chat高,但 ArgAcc 比Qwen1.5-14B-Chat 低,导致最终结果准确率更低。
为了进一步理解模型在参数传递上的失误原因,研究团队选择两个典型模型 GPT-4-1106-Preview 和 Llama-3-8B-Instruct,对它们进行了深入的错误原因分析,如下表所示。
分析显示,GPT-4 与 Llama-3 的错误分布存在显著差异。GPT-4 模型倾向于生成 “无动作”(No Action)的响应,在 38.7% 的错误中,GPTP ) % W , } & {-4 尝试与用户互动,错误地认为问题表述不够明确,要% V A 8 R L I R求提供额外信息。而在 50% 的错误中,模型仅生成内部思考过程,而未采取实际行动。
而Llama-3的大部分错误来自于格式错误,特别是调用工具或生成最终答案时。45.4% 的错误是由于参数未能遵循合法的 Jx D F P ^SO– 7 ` y ( k 6N 格式。此外,在 16.5% 的情况下,Llama-3试图同时调用多个工具,这并不被智能体系统支持。19.6% 的错误则源于生成冗余信息,导致参数解析不正确。
本文构建了面向复杂真实场景的通用工具智能体(General Tool Agents)评测基准:
-
构建了通用L G K z [ Z h S工具智能体的评测数据集。问题由人类设计,是步骤隐含、工具隐含的,且立足于真实世界场景,并提供了多模态语境输入。每个问题都标注了可执行的工具链,以支持细粒度的工具使用能力评测。
-
提供了包含感知、操作、逻辑、创作类5 } P别工具的评测平台。针对工具调用设计了细粒度的评测指标,揭示工具增强的语言G f U模型在真实世界场Z W s ^ = (景中的推理和规划能力。
-
评测和分析了主流大语言模型。从多个维度评测了 16 个大语言模型,反映了目前的语言模型在真实世界场景下的工具调用能力瓶颈,为通用目标智能体的发展路径提供建议。
以上就是NeurIPS 2024 | 真实世界复杂任务,全新基准GTA助力大模型工具调用能力评测的详细内容!















 微信扫一扫
微信扫一扫 














{kind=link}