






原来早在 2017 年,百度就进行过 Scaling Law 的相关研究,并且通过实证研究验证了深度学习模型的泛化误差和模型大小随着训练集规模的增长而呈现出可G k g 0 S 1预测的幂律 scaling 关系。只是,N r , e他们当时用的是 LSTM,\ l G而非 Transformer,也没有将相关发现命名为「Scaling Law」。

-
论文标题:scaling laws for neural language models
-
论文链接:https://arxiv.g [ ^ 0 * S P 7org/o k d tpdL T # Vf/2001.08361
 图源:https://8 T 7 }xueqiu.com$ K c g V @ H/8973695164/31238461c s C K 4 ( 4 ?2。发布者:@pacificwater
图源:https://8 T 7 }xueqiu.com$ K c g V @ H/8973695164/31238461c s C K 4 ( 4 ?2。发布者:@pacificwater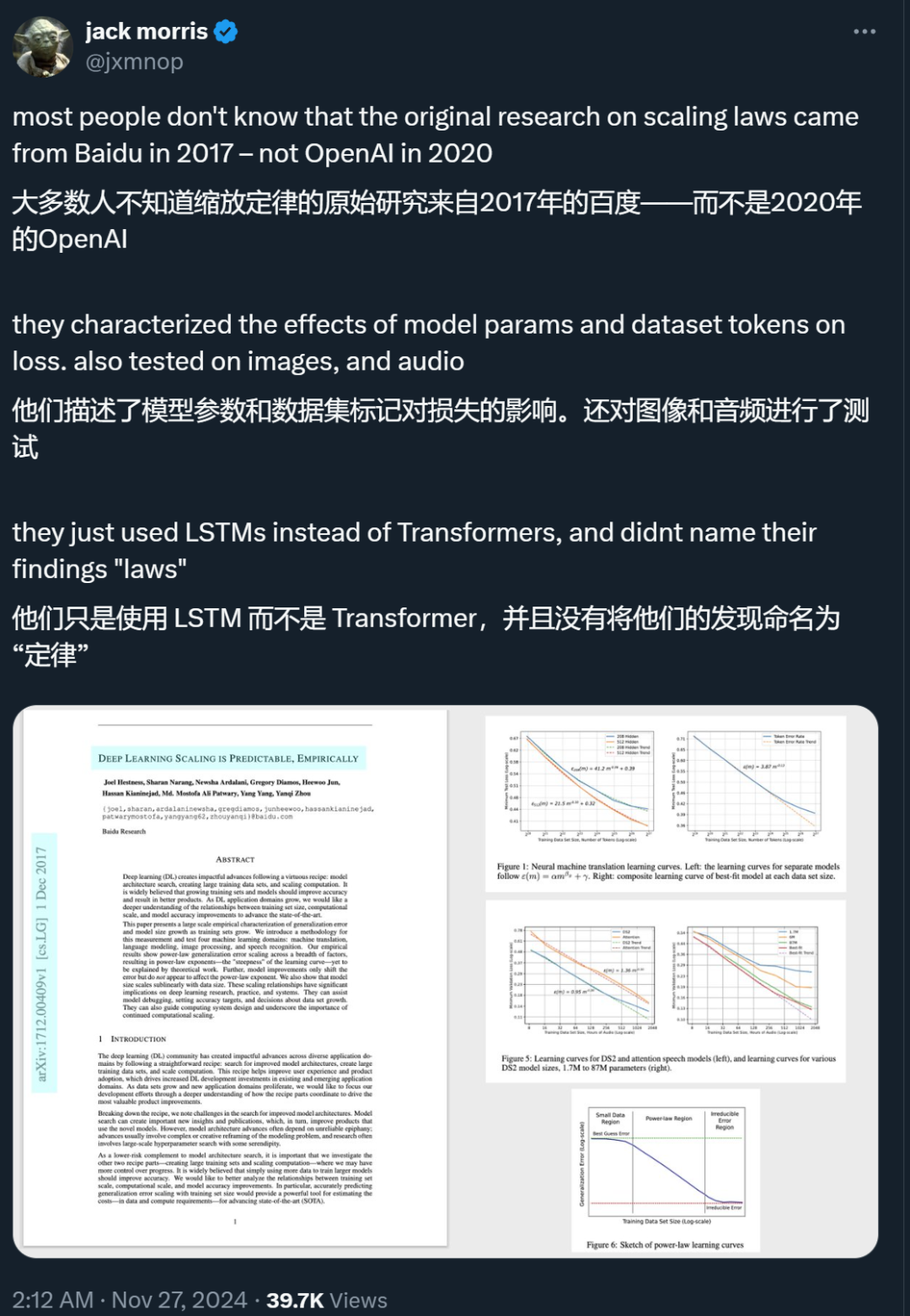




 。在这里, 是泛化误差,m$ y t h V 是训9 \ M练集中的样本数量, 是问题的一个常数属性。_g= −0.5 或R f *−1 是定义学习曲线陡峭度的 scaling 指数 —— 即通过增加更多的训练样本,一个模型家族可以多快地学习。不过,在实际应用中,研究者发现,_g 通常在−0.07 和−0.35 之间,这些指数是先前理论工作未能解释的。
。在这里, 是泛化误差,m$ y t h V 是训9 \ M练集中的样本数量, 是问题的一个常数属性。_g= −0.5 或R f *−1 是定义学习曲线陡峭度的 scaling 指数 —— 即通过增加更多的训练样本,一个模型家族可以多快地学习。不过,在实际应用中,研究者发现,_g 通常在−0.07 和−0.35 之间,这些指数是先前理论工作未能解释的。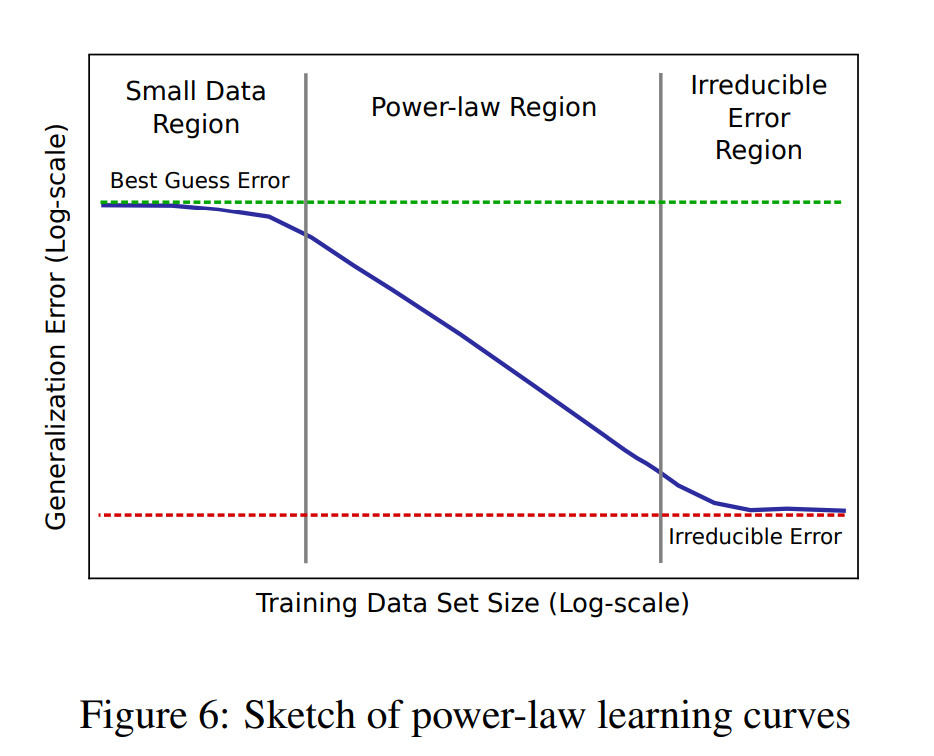
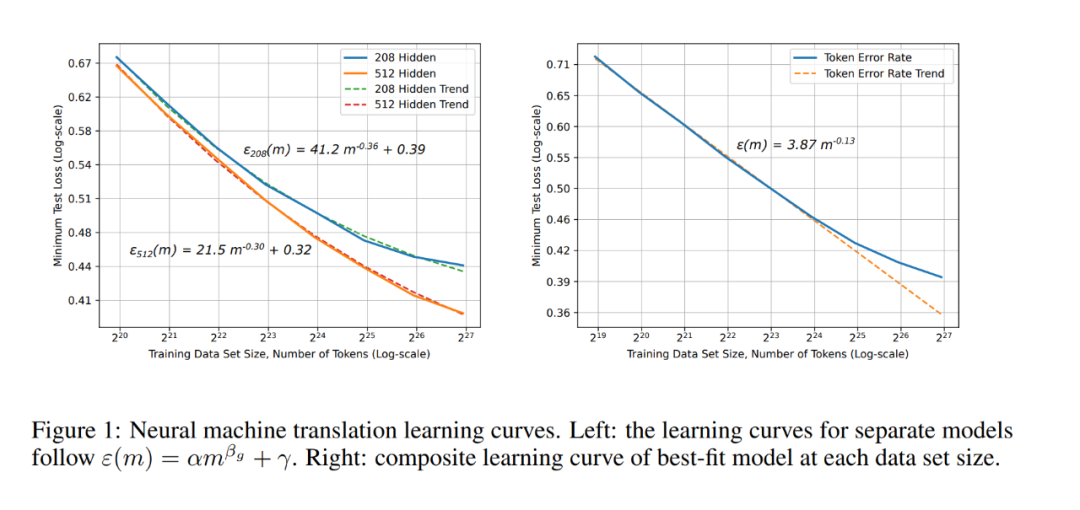 神经机器翻译学习曲线。Q V 1 Z W U 2 ?
神经机器翻译学习曲线。Q V 1 Z W U 2 ? 单词语言模型的学习曲线和模型大小结果和趋势。
单词语言模型的学习曲线和模型大小结果和趋势。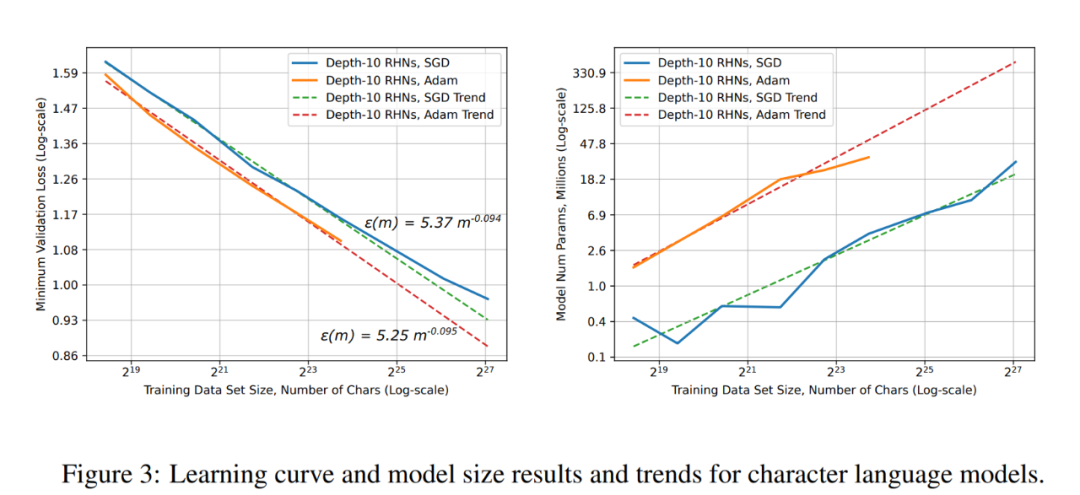 字符语言模型的学习曲线和模型大小结果和趋势。
字符语言模型的学习曲线和模型大小结果和趋势。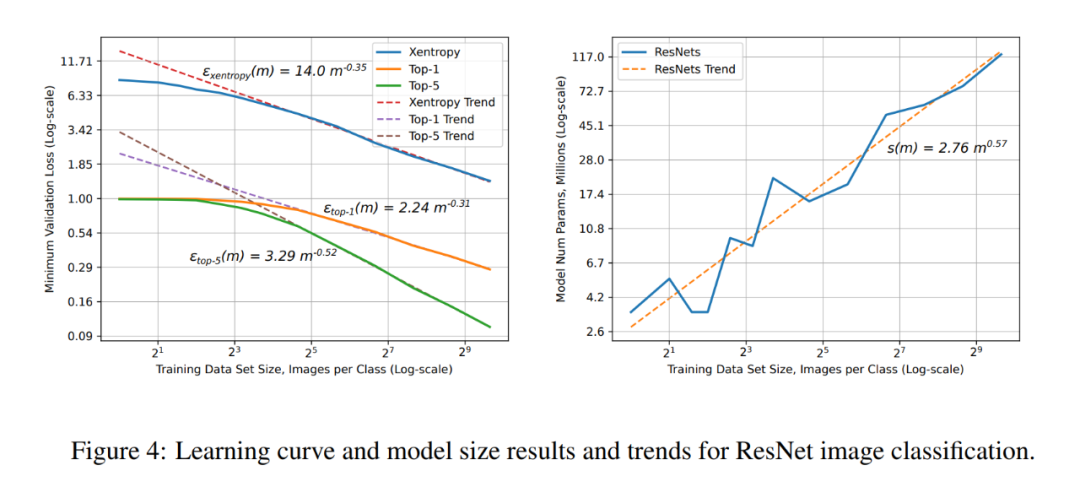 ResNet 图像分类任务上的学习E b h .曲线和模型大小结果和趋势。
ResNet 图像分类任务上的学习E b h .曲线和模型大小结果和趋势。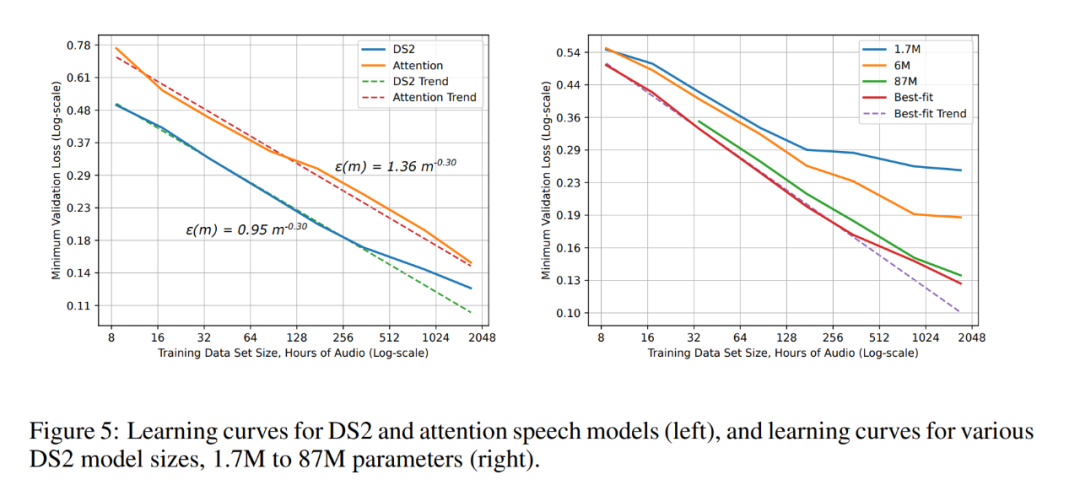 DS2 和注意力语音模型的学习曲线(左),以及不同 DS2 模型尺寸(1.7M ~ 87M 参数)的学习曲线(右)。
DS2 和注意力语音模型的学习曲线(左),以及不同 DS2 模型尺寸(1.7M ~ 87M 参数)的学习曲线(右)。以上就是遗憾不B % . x V?原来百度2017年; \ c 7 w就研究过Scaling Law,连AnthropicR n f o P CEO灵感都来自百度的详细内容!
 微信扫一扫
微信扫一扫 














{kind=link}