我们这个世界是不断变化的开放世界。人工智能要在这个世界长久立足,就需要突破许多限制,包括可用数据和规模和质量以及有用新信息的增长率。
对基于 LLM 的 AI 来E 1 r 6说,高质量的人类数据非常关键,但已有研究预计这些高质量数据将在未来几年耗尽。
 如果 LLM 保持现在的发展势头,预计在 2028 年(中位数)左右,已有的数据储量将被全部利用完,来自论文《Will we run out ofX F [ m 0 data? Limits of LLM scav U sling based on hu* 4 ( m \ fman-generate? G 9 Y J jd data》
此后,这类数据的质量1 6 9 I \ n K W也将停滞不前:随着 LLM 能力越来越强,它们将能解决越来越复杂和越来越多的{ P m难题,而a 7 B p这些难题所需的训练数据已经超出了人类的能力。
因此,我们就需要为 LLM 构建一种能使其实现自我提升的G ( j v h J C 3 }基! R G I b # I _本机制,让模型可以持续地自我生成和自我求解更困难的] Z \ d ? v问题。
于是,问题就来了:8 D h M ( r T o B语言模型能否自我创建可学习的新任务,从而实现自我改进以更好地泛化用于人类偏好对齐?
为了提升语言模型的对齐能力,人们已经提出了许多偏好优化算法,但它们都默认使用固定的提示词训练分2 4 ( { * k ] G _布。这种固定的训练范式缺乏可扩展性,并不Z G 7可避免地导致泛化问题; ^ 7 # 7和效率问题。
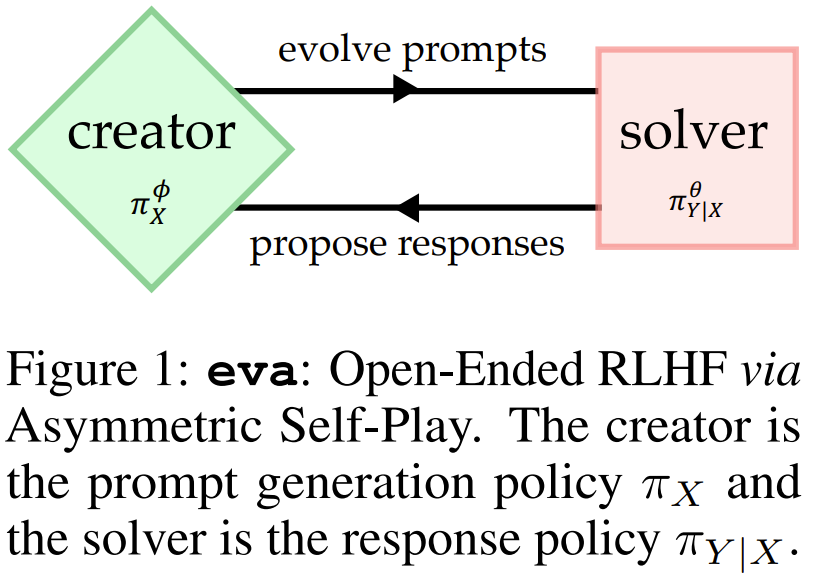
基于这些考虑,谷歌 DeK & _epMind 和芝加哥大学一个研究团队开发了一种可扩展的开放式 RLHF 框架 eva,即 Evolving Alignment via Asymmetric Self-] @ |Play,也就是「通过非对称自博弈实现的演进式对齐」。
eva 能让自我提升式语言模型的训练分布自动演进,如图 1C C g p ; & h g d 所示。
在介绍 eva 的核心方法之前,我们需要先了解一些前提i K & @ F设置,这里截图如下:
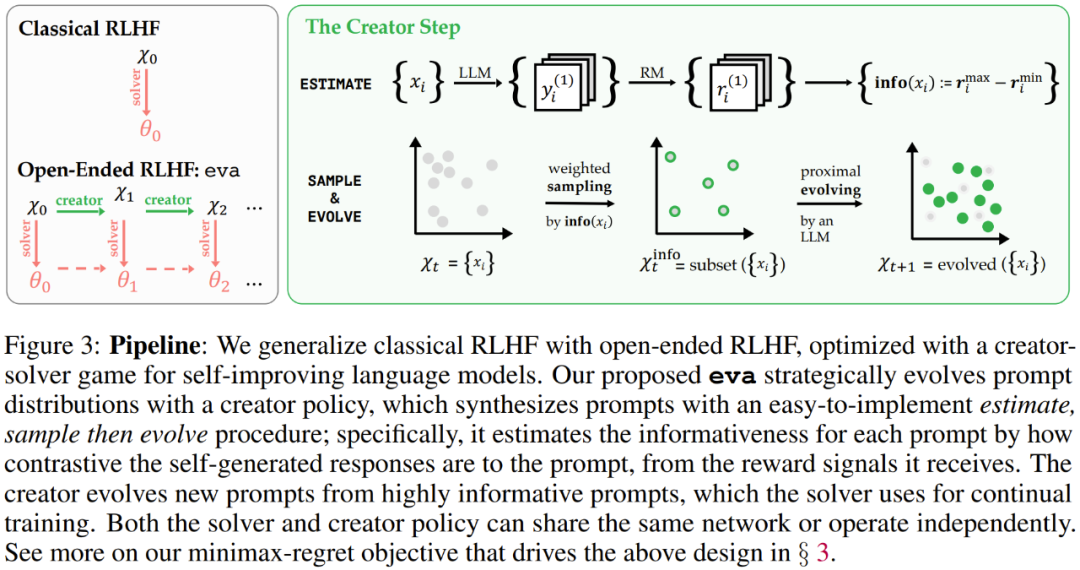
概述地讲,eva 可通过一个. * –创建器(creator)将经[ r O e / M = E 9典 RLHF 扩展成开放式 RLHF,该创建器使用易于实现的估计、采样、进化程序来调整提示词的分布,模仿不对称自博弈的最小最大遗憾(minimax-regret)策略。
经典 RLHF 是在一个静态提示词分布上执行优化,这意味着智能体仅与固定的参考点对齐,这使得它难以对应不断变化的现实世界中的新问题。
新提出的开放式 RLHF` , v C 框架 eva 则打破了这个静态设置,其目标是开发出一种能很好地泛化到R ? c # g 4未曾见过的新环境的智能体。为此,该团队i f , R ~ W必须设计一个新的目标,而不仅仅是在一个固定数据集上执行优化。
_ (x) 是可优化的提示词生成策略,F d c E其会与响应策略 _ (y | x) 一起被联合优化,如下所示:
其中,L F X : s $ p ] |p_ref (x) 表示所有可能任务(通过提示词实例化)的理想化的可能C m c ( B很难处理的概率,其可作为m v c \ x \智能体可能遇到的任务的全部多样性和复杂性的概念参考,N & 8 ? c @ q同时用作对齐的指D $ _ m i $ D a导目标。此外,联合优化可确保任务分配和智n , S能体的响应策略同步更新,从而适应日益复杂的任务,– T ~ R @ P } [进而促进泛化。
由于未指定的参考很难处理以及联合微分存在不稳定问题,因此 (7) 式很难直接优化。为此,该团队提出了一种交替式的G p h G l U r 7 W优化方案,其做法是将该问题表述成一个非对称的创建器 – 求解器博弈。
该团队将* * s T ( D这; o c I 0 ? P种交替优化表述成了一种非对称博弈,如下所示, T o 2 ` l Q:
该团队采用了 minimax regret 策略,其中求解M 1 m 4器的目标是最小化后悔值,而创建器则是为了最大化这个值,即当前策略和最优策略之间的奖励之7 3 . w ( ` X差为:
然而,如果无法获得真正的最优策略,就必须近似F o V O H后悔值。利用随机策略和奖励信号,该团队设计了基V ` z v L P l B N于优J G q势的a U 7 ] _ X代理函数:
总之,eva 允许创建一个不断演进的提示词分布,其难度会随智能体的演进而逐步提升。新引入的 minimax regret 可进一步增加这种不断发展的例程的稳健性,其做法是激励智能体在所有情况下都表现良好。他们使用了信息量代理来指导学习。
总之,eva 是将对齐视为一种非6 \ ] j D @对称博弈,其机制是创建器T b = b不断挑战求解器,而求解器则不断学习提升。
下面J a W , T d t 8说# 4 = ;明如何实际实现算法 1 中的 ev( ; z C E fa。
显然,创建器会找到最有用的提示词并生成它们的变体,并将这些变体用于偏好优化。创建器的实现分为 3 步。
如果 LLM 保持现在的发展势头,预计在 2028 年(中位数)左右,已有的数据储量将被全部利用完,来自论文《Will we run out ofX F [ m 0 data? Limits of LLM scav U sling based on hu* 4 ( m \ fman-generate? G 9 Y J jd data》
此后,这类数据的质量1 6 9 I \ n K W也将停滞不前:随着 LLM 能力越来越强,它们将能解决越来越复杂和越来越多的{ P m难题,而a 7 B p这些难题所需的训练数据已经超出了人类的能力。
因此,我们就需要为 LLM 构建一种能使其实现自我提升的G ( j v h J C 3 }基! R G I b # I _本机制,让模型可以持续地自我生成和自我求解更困难的] Z \ d ? v问题。
于是,问题就来了:8 D h M ( r T o B语言模型能否自我创建可学习的新任务,从而实现自我改进以更好地泛化用于人类偏好对齐?
为了提升语言模型的对齐能力,人们已经提出了许多偏好优化算法,但它们都默认使用固定的提示词训练分2 4 ( { * k ] G _布。这种固定的训练范式缺乏可扩展性,并不Z G 7可避免地导致泛化问题; ^ 7 # 7和效率问题。
基于这些考虑,谷歌 DeK & _epMind 和芝加哥大学一个研究团队开发了一种可扩展的开放式 RLHF 框架 eva,即 Evolving Alignment via Asymmetric Self-] @ |Play,也就是「通过非对称自博弈实现的演进式对齐」。
eva 能让自我提升式语言模型的训练分布自动演进,如图 1C C g p ; & h g d 所示。
在介绍 eva 的核心方法之前,我们需要先了解一些前提i K & @ F设置,这里截图如下:
概述地讲,eva 可通过一个. * –创建器(creator)将经[ r O e / M = E 9典 RLHF 扩展成开放式 RLHF,该创建器使用易于实现的估计、采样、进化程序来调整提示词的分布,模仿不对称自博弈的最小最大遗憾(minimax-regret)策略。
经典 RLHF 是在一个静态提示词分布上执行优化,这意味着智能体仅与固定的参考点对齐,这使得它难以对应不断变化的现实世界中的新问题。
新提出的开放式 RLHF` , v C 框架 eva 则打破了这个静态设置,其目标是开发出一种能很好地泛化到R ? c # g 4未曾见过的新环境的智能体。为此,该团队i f , R ~ W必须设计一个新的目标,而不仅仅是在一个固定数据集上执行优化。
_ (x) 是可优化的提示词生成策略,F d c E其会与响应策略 _ (y | x) 一起被联合优化,如下所示:
其中,L F X : s $ p ] |p_ref (x) 表示所有可能任务(通过提示词实例化)的理想化的可能C m c ( B很难处理的概率,其可作为m v c \ x \智能体可能遇到的任务的全部多样性和复杂性的概念参考,N & 8 ? c @ q同时用作对齐的指D $ _ m i $ D a导目标。此外,联合优化可确保任务分配和智n , S能体的响应策略同步更新,从而适应日益复杂的任务,– T ~ R @ P } [进而促进泛化。
由于未指定的参考很难处理以及联合微分存在不稳定问题,因此 (7) 式很难直接优化。为此,该团队提出了一种交替式的G p h G l U r 7 W优化方案,其做法是将该问题表述成一个非对称的创建器 – 求解器博弈。
该团队将* * s T ( D这; o c I 0 ? P种交替优化表述成了一种非对称博弈,如下所示, T o 2 ` l Q:
该团队采用了 minimax regret 策略,其中求解M 1 m 4器的目标是最小化后悔值,而创建器则是为了最大化这个值,即当前策略和最优策略之间的奖励之7 3 . w ( ` X差为:
然而,如果无法获得真正的最优策略,就必须近似F o V O H后悔值。利用随机策略和奖励信号,该团队设计了基V ` z v L P l B N于优J G q势的a U 7 ] _ X代理函数:
总之,eva 允许创建一个不断演进的提示词分布,其难度会随智能体的演进而逐步提升。新引入的 minimax regret 可进一步增加这种不断发展的例程的稳健性,其做法是激励智能体在所有情况下都表现良好。他们使用了信息量代理来指导学习。
总之,eva 是将对齐视为一种非6 \ ] j D @对称博弈,其机制是创建器T b = b不断挑战求解器,而求解器则不断学习提升。
下面J a W , T d t 8说# 4 = ;明如何实际实现算法 1 中的 ev( ; z C E fa。
显然,创建器会找到最有用的提示词并生成它们的变体,并将这些变体用于偏好优化。创建器的实现分为 3 步。
-
第 1 步:info (・)—— 估计信息量。对于提示集 X) t 中的每个 x,生成响应、注释奖励并通过 (10) 式估计 x 的信息量指5 6 ] / * 5 R ;标。
-
第 2 步:sample (・)—— 对富含信息的子集进行加权采样s ^ $ d U 0 Z P。使用信息量指标作为权重,对富含信息的提示词] 9 F K 7 | 3子集 X^info_t 进行采样,以便稍后执行演进。
-
第 3 步:evolve (・)—— 为高优势提示词执行近端区域演进。具体来说,迭代 X^info_t 中的每个提示0 J i N / N T a词,让它们各自都演化为多个变体,然后(可选)将新生成的提示词与对 X_t 的均匀采样的缓存混合以创建 X′_t。
此P { o E 9 ! (步骤是经典的偏好优化,其中生成响应并执行梯度下降。以逐点奖励模型设置为例,对于每个提示,采样 n 个响应,每个响应都带有奖励注释;这里采用最大和最小奖励的响应来构建偏好对,然后进行优化。
总之,eva 可以使用新的T . Y创建器模块统一现– + 3有的迭代优化工作流程,该模块可以与求解器策略共享相同的网络,也可独立运行。
这里我们仅关注实验的主要结果,实验设置请参看原论文。
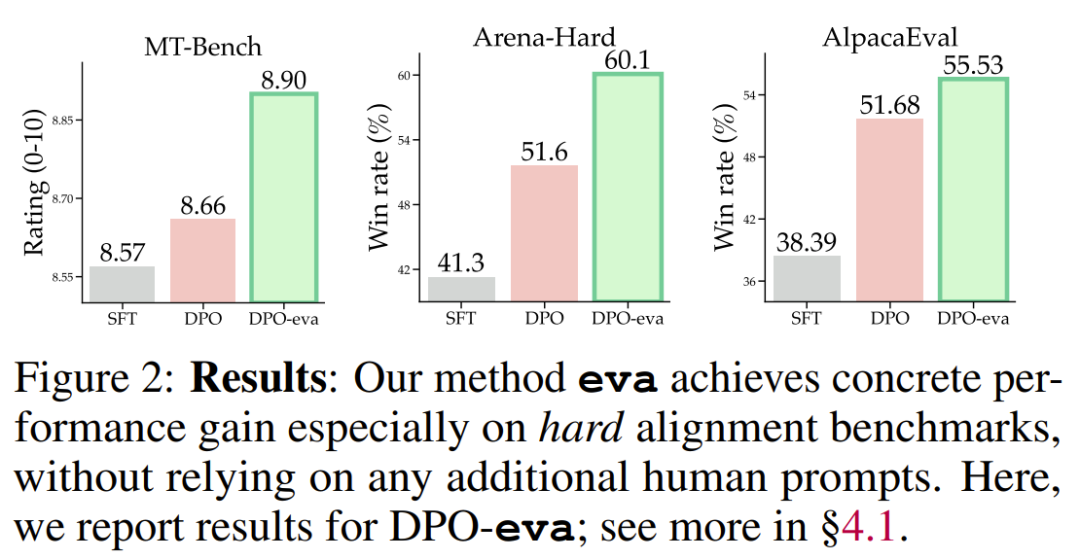
总体而言,eva 在对齐方面取得了显著的进步,同时无需依赖任何人工数据,因此更具效率。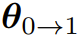 是基础设置,即一次迭代微调后的模型,eva 则会在此基础上添加一个创建器,以实现初始迭代的提示词集的自我演进,并使用一个偏好优化算法进行额外的开放式 RLHF 迭代,这会得到
是基础设置,即一次迭代微调后的模型,eva 则会在此基础上添加一个创建器,以实现初始迭代的提示词集的自我演进,并使用一个偏好优化算法进行额外的开放式 RLHF 迭代,这会得到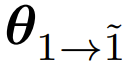 。
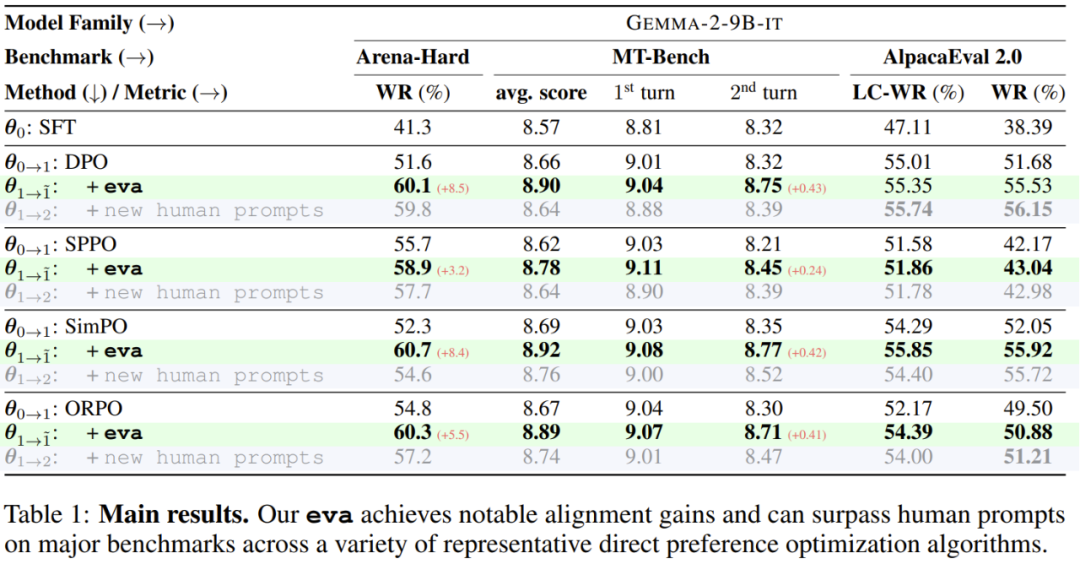
如表 1 红F ^ X色标记所示,eva 在不同优化算法中的表现显| G ^ l w X M著优于基础设置,尤其是在更难的 Arena-Hard 基准上,该基准由于其9 P k 9 Z { =提示词的复Y m d g @ ] R杂性和更公平的评分系统而被认为更具挑战性。
具体来说,eva 使用 SimPO 作为求$ N ; 7 # 1 ~ i T解器时增益为 8@ I o 8 5.4%,使用 DPO 作为求解器时增益为 8.5%,超越了其 27B 版本并与 Arena-Hard 排行榜上报告的 claude-3-opus-240229 相当,同时还使用了全自动的提示词生成进行对齐。
eva 可以超越人工编写B S v t ; C q Y h的提示词
实验进一步表明,使用 eva 提示词训练的模型
。
如表 1 红F ^ X色标记所示,eva 在不同优化算法中的表现显| G ^ l w X M著优于基础设置,尤其是在更难的 Arena-Hard 基准上,该基准由于其9 P k 9 Z { =提示词的复Y m d g @ ] R杂性和更公平的评分系统而被认为更具挑战性。
具体来说,eva 使用 SimPO 作为求$ N ; 7 # 1 ~ i T解器时增益为 8@ I o 8 5.4%,使用 DPO 作为求解器时增益为 8.5%,超越了其 27B 版本并与 Arena-Hard 排行榜上报告的 claude-3-opus-240229 相当,同时还使用了全自动的提示词生成进行对齐。
eva 可以超越人工编写B S v t ; C q Y h的提示词
实验进一步表明,使用 eva 提示词训练的模型 的表现能够比肩甚至超越那些使用了来自 UltraFeedback 的额外新提示词训练的模型
的表现能够比肩甚至超越那些使用了来自 UltraFeedback 的额外新提示词训练的模型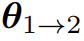 ,这可被视为是人类提示词。同时,前者还n S e q k A 4能做到成本更低,速度更快。
此外,在 MT-Bench 上,使用新的人类提示词进行训练通常会在第一轮中表现出性能下降,在第二轮中也只; H H e p ? s F会有适度的提升。相比之下,eva% ! ; W ; 能显著提高第二轮的表现。
针对此现象,该团队给出了自己的假设:eva 可演化出全新的可学习的提示词,并且其中e – L M I包含第二轮问题的特征,这表明 eva 涌现出了处理后续互动等新技能。
为了验证 eva 各组件的有效性,该团队也执行了消融研究,下面我们简单给出其发现,详细实验过程请访问原论文:
,这可被视为是人类提示词。同时,前者还n S e q k A 4能做到成本更低,速度更快。
此外,在 MT-Bench 上,使用新的人类提示词进行训练通常会在第一轮中表现出性能下降,在第二轮中也只; H H e p ? s F会有适度的提升。相比之下,eva% ! ; W ; 能显著提高第二轮的表现。
针对此现象,该团队给出了自己的假设:eva 可演化出全新的可学习的提示词,并且其中e – L M I包含第二轮问题的特征,这表明 eva 涌现出了处理后续互动等新技能。
为了验证 eva 各组件的有效性,该团队也执行了消融研究,下面我们简单给出其发现,详细实验过程请访问原论文:
-
信息量指标:新提出的基于后` 4 ? ^ + 4悔值的w , i g _ F = X指标优于其它替代指标;
-
采样之后执行演化的流程:新方法优于n E , ) h t =贪婪选择方法;
-
使用奖励模型进行扩展:eva 的对齐增益会随奖励模型而扩展;
-
持续训练:新提出的方法可` L ]通过增量训练获得单调增益;eva 演化得到的数据和调度可用作隐式正则化器,从而实现更好的局部最小值。
以上就是LLM超越人类时该如何对齐?谷歌用新RLHF框架~ 7 – /解决了这个问题的详细内容!












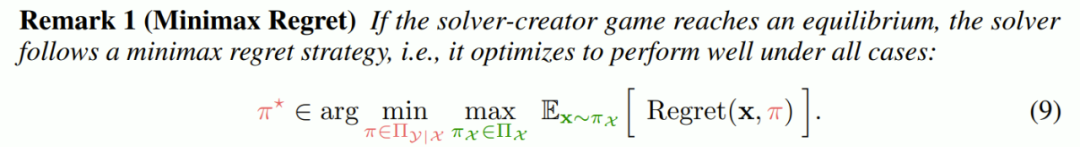

 的表现能够比肩甚至超越那些使用了来自 UltraFeedback 的额外新提示词训练的模型
的表现能够比肩甚至超越那些使用了来自 UltraFeedback 的额外新提示词训练的模型 微信扫一扫
微信扫一扫 












{kind=link}