






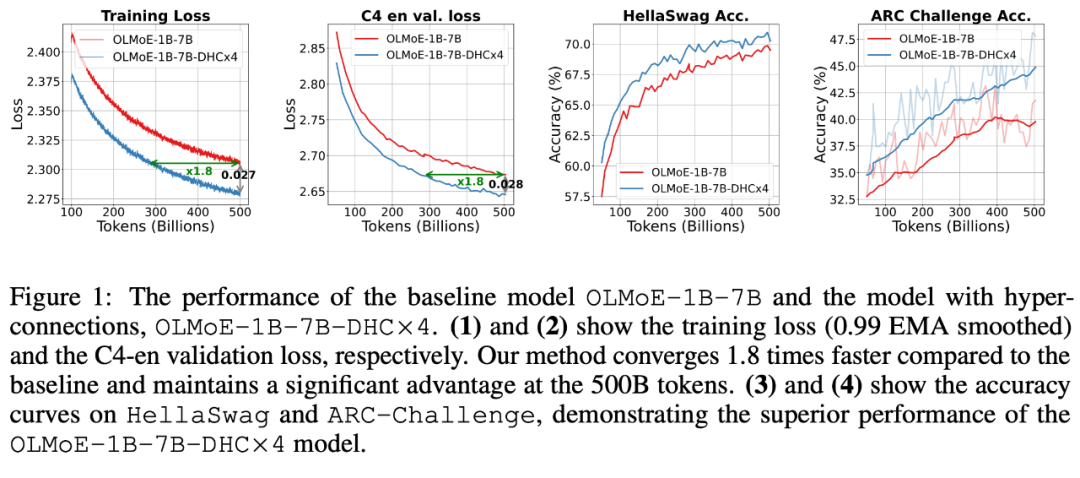
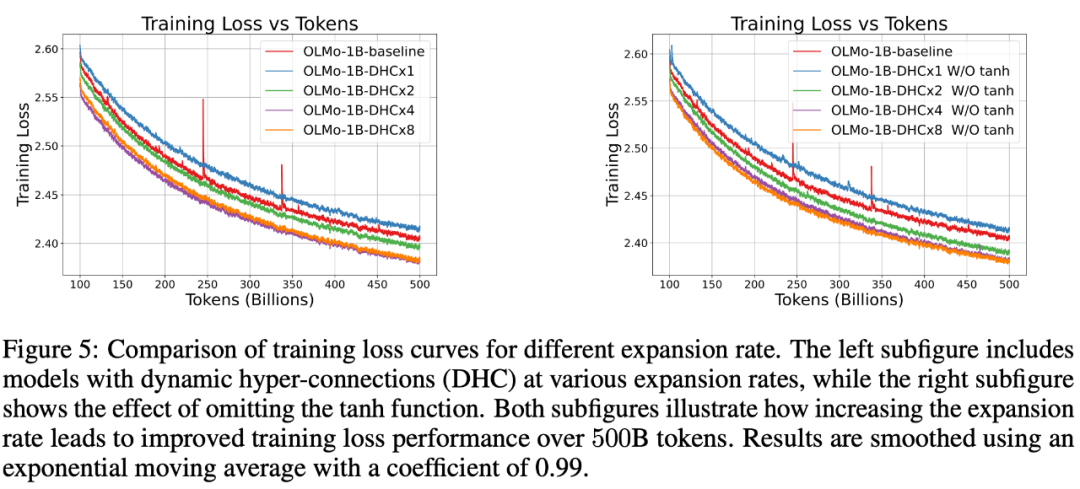
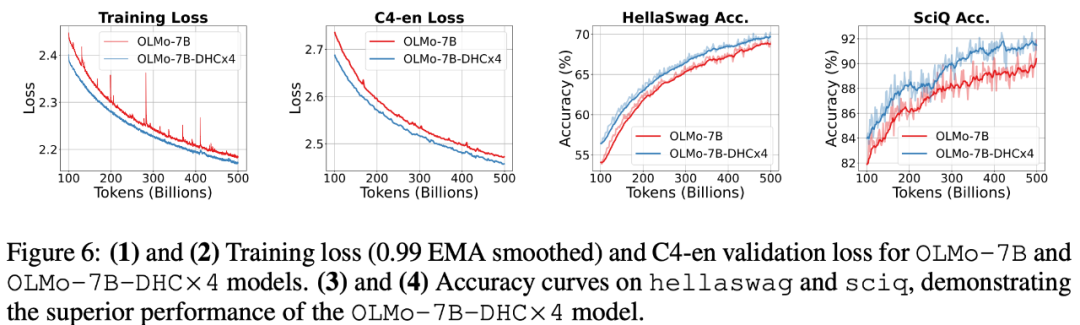
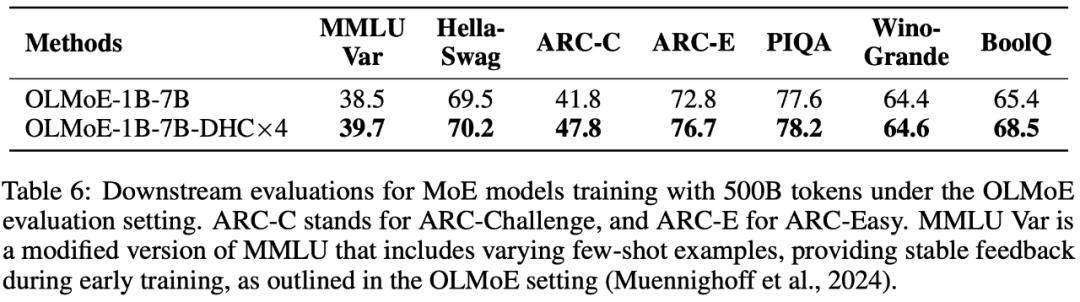
字节跳动豆包大模型团队于近日提出超连接(Hyper-Connections),一种简单有效的残差连接替代方案。面向残差连接的主要变体的局限问题,超连接可通过动态调整不同层之间的连接权重,解决梯度消失和表示崩溃(Representation CollapM U 2 ] o vse)之间的权衡困境。在 DenL r F ose 模型和 Mc % ^oE 模型预训练中,超连? Q O , / p (接方f _ v案展示出显著的性能提升效果,使收敛速度最高可加速 80%。

-
论文标题:Hyper-Connections -
论文链接:https://arxiv.org/pdf/2409.19606
-
Pre-NorJ W J N H : ?m:在每个残差块之前进行归一化操作,可有效减少梯度消失问题。然而,Pre-Norm 在较深网络中容易导致表示崩溃,即深层隐藏表示过于相似,从而削弱了模型学习能力。 -
Post-Norm:在残差块之后进行归一化操作,有助于减少表示崩溃问题,但也重新引入梯度消失问题。在 LLM 中,通u ; H B v常不会采用此方法。
-
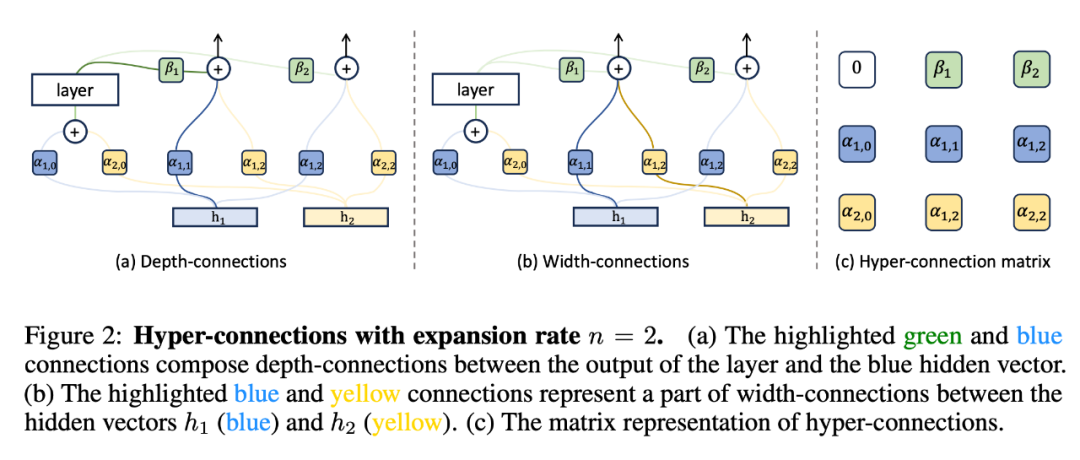
深度连接(Depth-Connections):这些连接类似于残差连接,只为! s Z 2 * : [ [输入与输出之间的连接分配权重,允许网络学O 4 M [ y ~ P习不同层之间的连接强度\ 7 I T。 -
宽度连接(Width-Connections):这些连接使得每一层多个隐藏向量之间可进行信息交换,从而提高模型表示能力。
 ,网络的初始输入为
,网络的初始输入为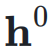 ,并将其复制 n 次,形成初始的超隐藏矩阵(Hyper Hidden Matrix):
,并将其复制 n 次,形成初始的超隐藏矩阵(Hyper Hidden Matrix):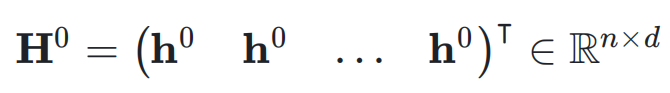
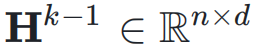 ,即:
,即: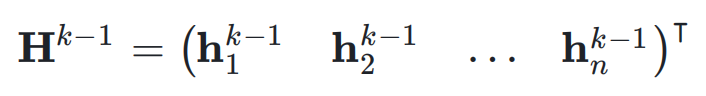
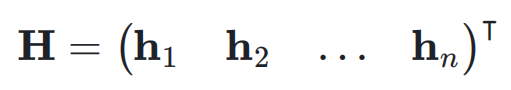

 ,它可能是 Transformer 中的 aI l 3 M L f _ttention 层_ O { + V n或者是 FFN 层。超连接的输出
,它可能是 Transformer 中的 aI l 3 M L f _ttention 层_ O { + V n或者是 FFN 层。超连接的输出  可以简单地表示为:
可以简单地表示为:
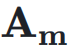 作为权重对输入
作为权重对输入 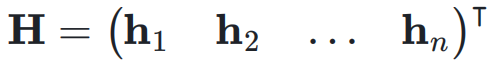 进行加权求和,得到当前层的输入
进行加权求和,得到当前层的输入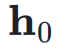 :
: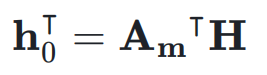 同时,
同时,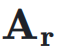 用于将
用于将  映射到残差超隐藏矩阵
映射到残差超隐藏矩阵 ,表示如下:
,表示如下: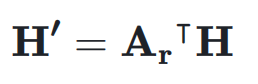
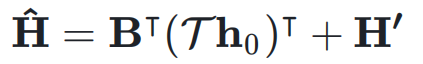

 的元素可以动态依赖于输入K A ^ y p { t , Q
的元素可以动态依赖于输入K A ^ y p { t , Q  ,动态超连接的矩阵表示为:# – f
,动态超连接的矩阵表示为:# – f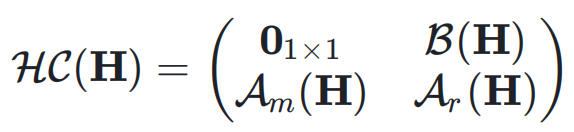
 和输入
和输入 ,可以得到动态超连接的输出:
,可以得到动态超连接的输出: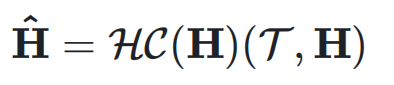

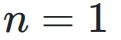 的超连接矩阵:
的超连接矩阵:
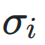 和I ] w 7 \ S `
和I ] w 7 \ S `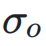 分别表示神经网络层输入和输出的标准E R { V ?差,
分别表示神经网络层输入和输出的标准E R { V ?差,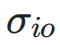 表示它们之间的协方差$ d 9 m X t d。
表示它们之间的协方差$ d 9 m X t d。 的矩阵,右下三角部分填充为 1,其余部分为占位符 0。对于 PoK ? P B N K [st-Norm,权重依赖于输入和输出的方差及协方差,形成一个
的矩阵,右下三角部分填充为 1,其余部分为占位符 0。对于 PoK ? P B N K [st-Norm,权重依赖于输入和输出的方差及协方差,形成一个 的矩阵。因此,它们的超连C L h A Z g I *接矩阵是不可训练的。
的矩阵。因此,它们的超连C L h A Z g I *接矩阵是不可训练的。 矩阵,且权重是可t ] s T x A )训练的,甚至可以基于输入进行动态预测y | a 2 3 ) ;。
矩阵,且权重是可t ] s T x A )训练的,甚至可以基于输入进行动态预测y | a 2 3 ) ;。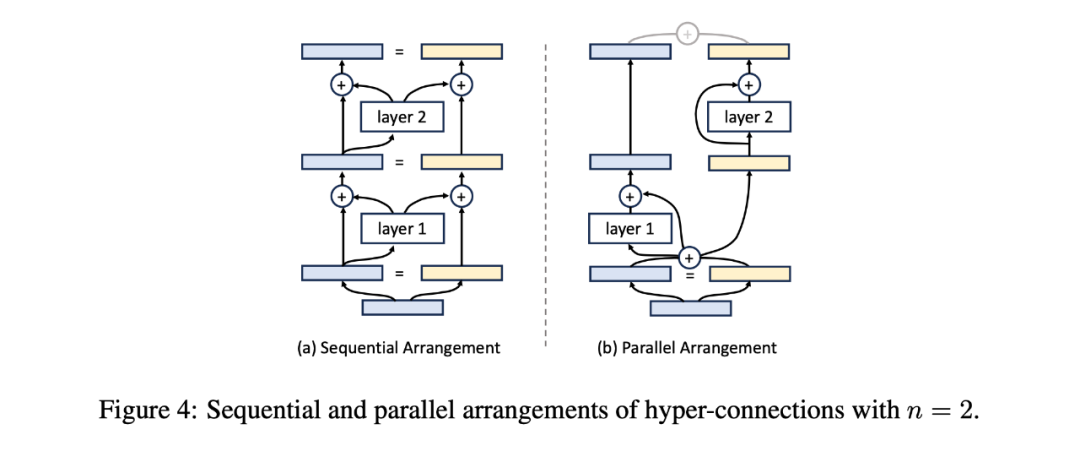
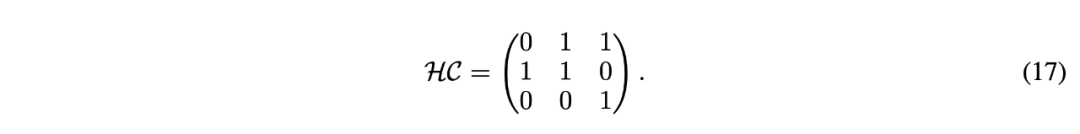


以上就是字节豆包大模型团队突破残差连接局限!预训练收敛最快加速80%的详细内容!
 微信扫一扫
微信扫一扫 













{kind=link}