







AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎w C 6 j = 1 c z投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com@ i 2 6;zhaoyunfeng@^ ) m e ! 6 Qjiqizhixin.com
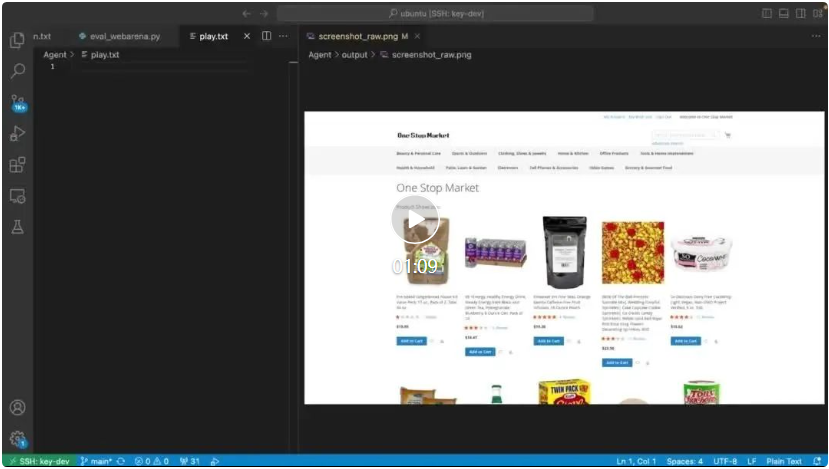 帮你写email
帮你写email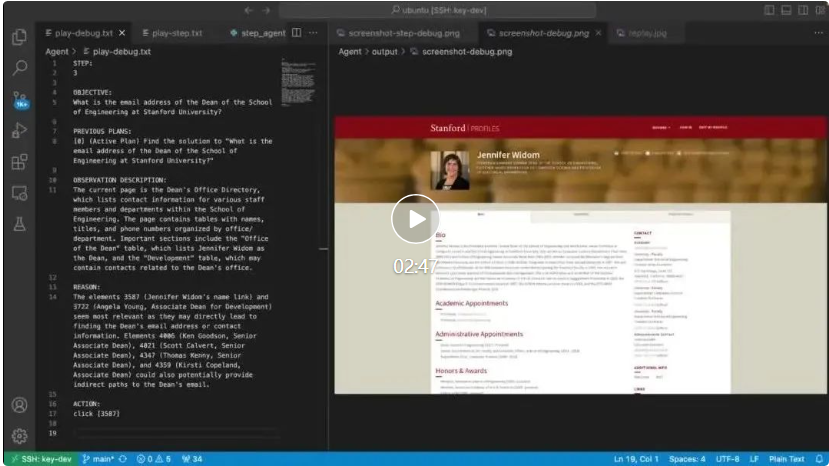

-
论文链接:https://arxiv.org/ax Y e Pbs/2410.13825
-
论文名:AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web Agents
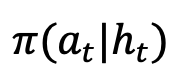 ,最大化预期累积奖励,其中 h_t 表示观测历史
,最大化预期累积奖励,其中 h_t 表示观测历史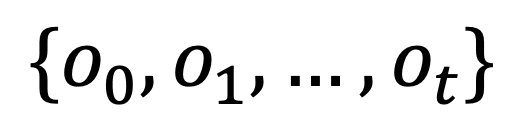 。
。
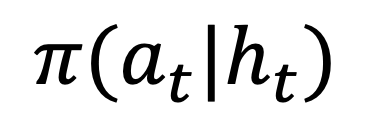 。
。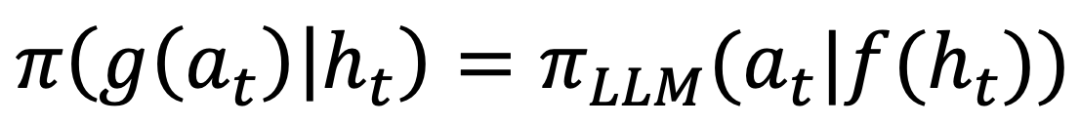 ,其中 f 和s P o + P d g 是处理观测和行动空间的基于规则的函数,该团队将其称为「观测和行动空间对齐问题」。
,其中 f 和s P o + P d g 是处理观测和行动空间的基于规则的函数,该团队将其称为「观测和行动空间对齐问题」。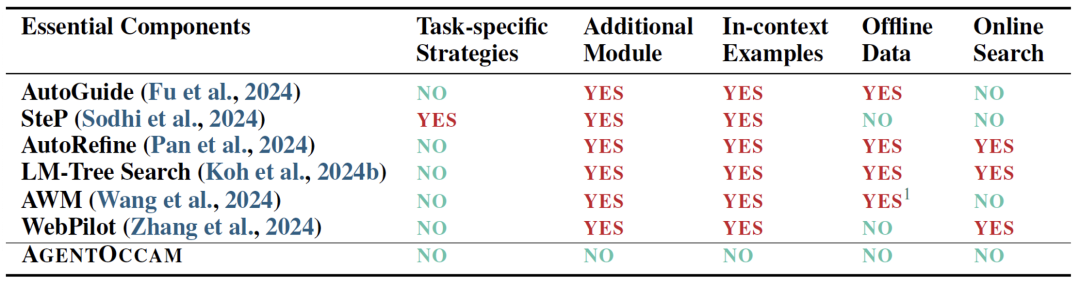
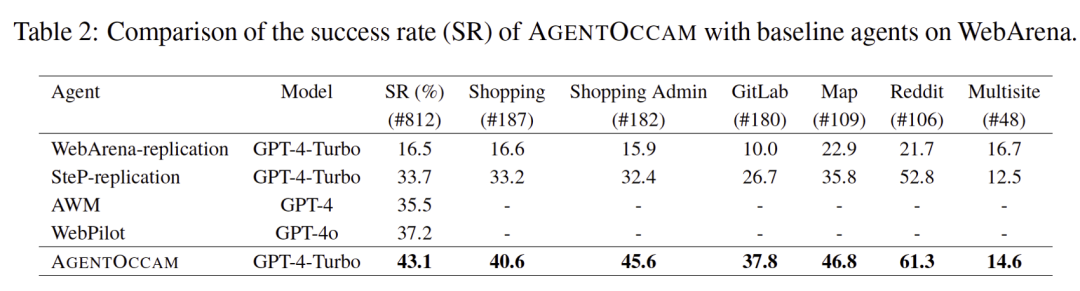
 构建一个强大的网络智能体?这是 AgentOccam 关注的6 1 J P a w R问题。
构建一个强大的网络智能体?这是 AgentOccam 关注的6 1 J P a w R问题。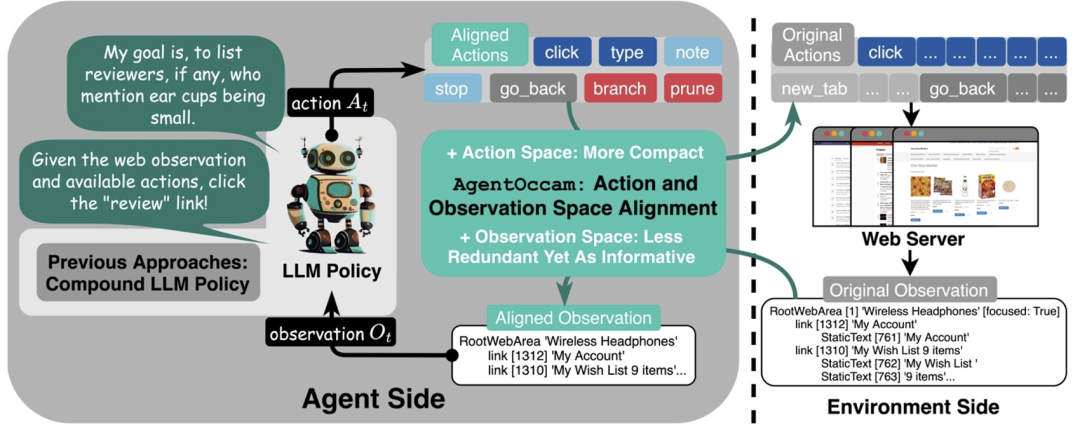
-
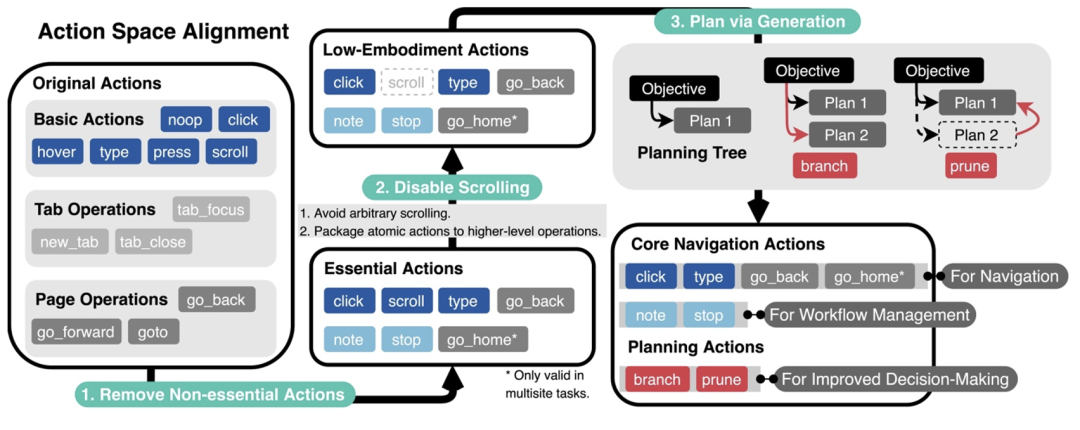
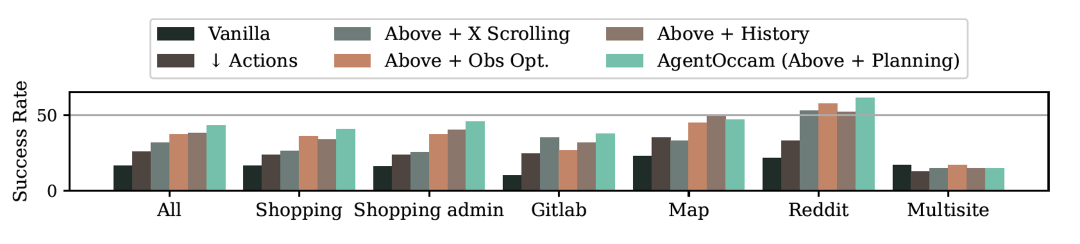
首先,减少非必要的网络交互动作,让智能体的具身和琐碎互动需求达到最小;
-
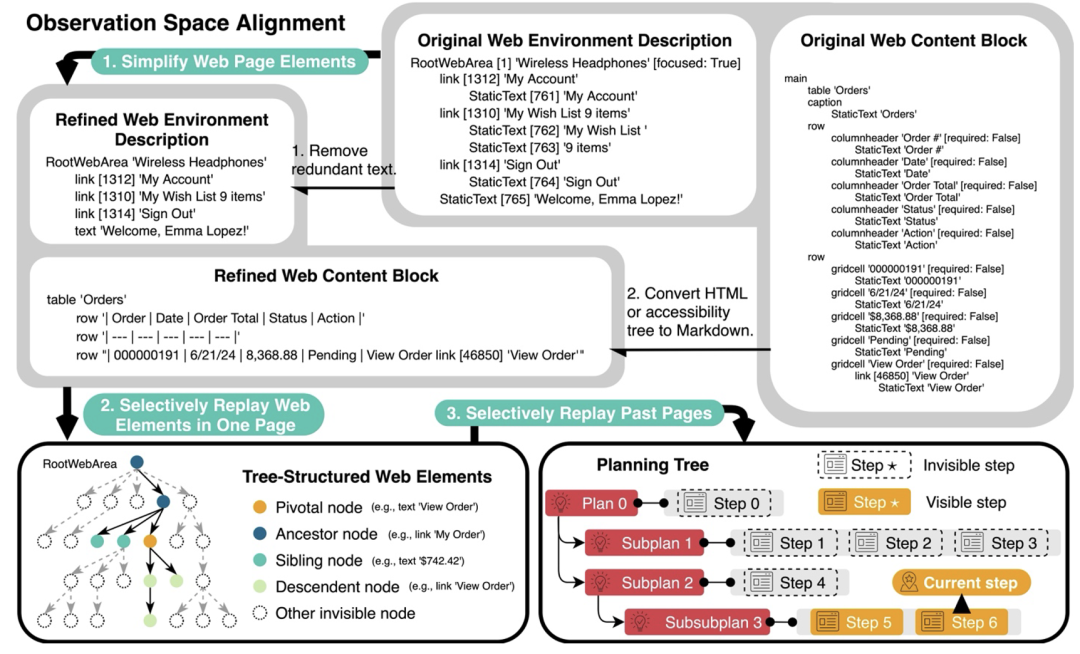
其次,消除冗余和不相关的网页元素,并重构网页内容块,以获取更简洁但同样信息丰富的表示,从而精炼观察空间6 $ 3 p +;
-
最后,引入两个规划动作(分支和修剪)z e ? {,这使得智能体能够以规划树结构自组织导航工作流,并使用相同结构过滤历史步以进行回放。



以上就是不靠更复杂的策略,仅凭和大模型训练对齐,零样本零经验单LLM调用,成为网络任务智能体新SOTA的详细内容!
 微信扫一扫
微信扫一扫 













{kind=link}