







AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:) 7 F Nliyazhou@j{ 9 d = =iqizhixin.com;zhaoyunfeng@jiqizhixin.cw + zom
本文的共同第一作者是马里兰大学电子计算机工程系G g W ; r $ :的博士生吴曦旸(httpd { – [ n ! 7 K +s://wuxiyang1996.github.io/)和计算机科学系的关天L ] V ` L瑞(https://tianruiguan.6 F X 7 B ; } vphd/)。吴曦旸的研究方向主要涵盖强化学习、自动驾驶,以及大语言模型在机器人导航和计算机视觉中的应用。关天瑞的研究则聚焦于计算机视觉和视觉语言d H E T &模型在机器人、自动驾驶等领域的应用。! Q 1 g 5 % \本文的指导老师为李典奇,周天翼教授 (https://tianyizhou.github.io/)和 Dinesh Manocha 教授 (https://wwa T v T Jw.cs.umd.edu/pe E X { + Y Meople/dmanocha)。
想象一下,有一天p ^ b – F w T你在沙漠中看到一个雪人,或者在雪地里发现一棵棕榈树。面对这些与周围环境格格不入的景象,你是否会感到心理上的不适?
在认知科学领域,研究者普遍认为人脑倾向于利用以往的经验来解读观察到的信息并构建记忆。然而,当人脑接收到与以往认知不符的信息时,可能会因为 “认知失调”(Cognitive Dissonance)而对外部环境产生误判,进而在行为上表现出矛盾。例如,我们通常认为电脑s Y 1是由人类操控的,但如果我们看到一只章鱼在操控电脑,这种不符合常理的场景会让人脑产生认知失调的不适感。
随着对大模型的深入研究,研究人员发现,在认知和推理任务上,大模型的思维过程与9 6 P H J a f人脑有一定相似之处。因此,针对人脑认知失调特点设\ s # b F h计的实验也能使大模型3 _ ( 1出现类似的 “幻觉” 现象。
基于这一观察N . 5 N o ) – F +,马里兰大学的研究团队提出了一个名为 AutoHallusik k = + con 的视觉大模型幻觉自动生成框架。这一工作基于团队之前在C J 5 h m , G CVPR 2024 上发表的工作 HalluionBench(https://arxiv.org/pdf/2310.14566)。它通过在场景图像中插入或删除4 } $ ^特定物体,并针对这些修改后的图像提问,从而检测大模型在回答时可能出现的幻觉现象。
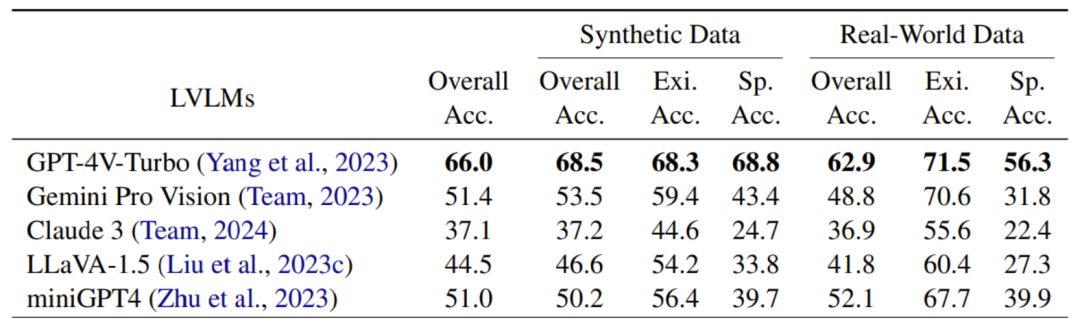
这一方法能够自动生成大量的大模型幻觉案例,有效缓解当前大模型幻觉研究中数据集缺乏的问题。在 GPT-4V、Gemini 和 Claudb P ~ w @ ` 5 he 等大模型上的实验表明,这些模型在本文提出的提出的基准数据集上问答准确率最高/ W Y @仅为 66.0%。该研究成果已发表于 EMNLP 2024。

-
论文标题:AUTOHALLUSION: Automatic Generation of Hallucination Benchmarks for Vision-Language Models
-
论文链接:https://arxiv.org/pdf/2406.10900
-
项目主页及代码:https://wuxiyang1996.github.iot L ? b s E X/autohallusion_page/
文章概述
大型视觉语言模型(LVLMs)在内容生成、自动驾驶和机器人等领域中扮演着重要角色。然而,它们也会g w Z M W d z 7出现 “幻觉” 现象,即生成的响应中包含视觉内容中不存在. i Q 5的信息。这些幻觉通常是由于语言模块过度依赖语言先验信息而忽略视觉输入所致。
为{ 6 v \ J Z g S 5了解决这一问题` y g ],之前的工作通常收集幻觉案例建立基准数据集,并以此对大模型/ y E S 7 Y进行微P o ^ * s p调,以减少可能存在的幻觉。然而,手动创建幻觉案例和基准既耗时又昂贵。此外,k [ ? J { !之前的工作对大模型产生幻觉的机制研究有限,在缺乏足够代表性案例的情况下对大模型进行微调,可能会导致模型出现过拟合现象。
为此,本文提出了 AUTOR X t z N ) } s bHALLUSION 框架,可以自动生成各种幻觉案例并进行批量生产。该框架基于认知科学原理,针对大模型产生幻觉的原因,提出了三种主^ % 7 z要策略:插入异常物体、插入成对物体和移除相关物体,通过操控场景中的物体构成来创建与语言先验相Y [ z 0 E冲突的图像。
为了生成能够触发大模型幻觉的(图像 – 问题)组合,本文针对修改后的图像,设计相应的问题探测大模型的语言模块,定位特定物f ` c G体或其在相关情境中的语言先验信息。如果大模型的推理受到语言先验的偏见影响,例如在根据图片回答某一特定物体的问题时,大模# C $ u f \ H e型根据场景图{ / A片的先验知识而非物体本身传递的信息来作答,那么就可能生成与事实不符或前后不一致的响应,从而导致幻觉现象。
AUTOHALLUSION 在包括 GPT-4V、Gemini、Clau( 3 s . e 3de 和 LLaVA 等最新的大模型上进行了实验,并整理发布了一个基准数据集,来评估模型性能。在该基准数据集上的实验结果表明,GPj ] K u k ^T-4V 等大模型的问答准确T 2 $ J + a率最高仅为 66.0%。
数据集地址:https://github.com/wuxiyang1996/AutoH5 Y ) F i $ V ~ zallusion
研究方法
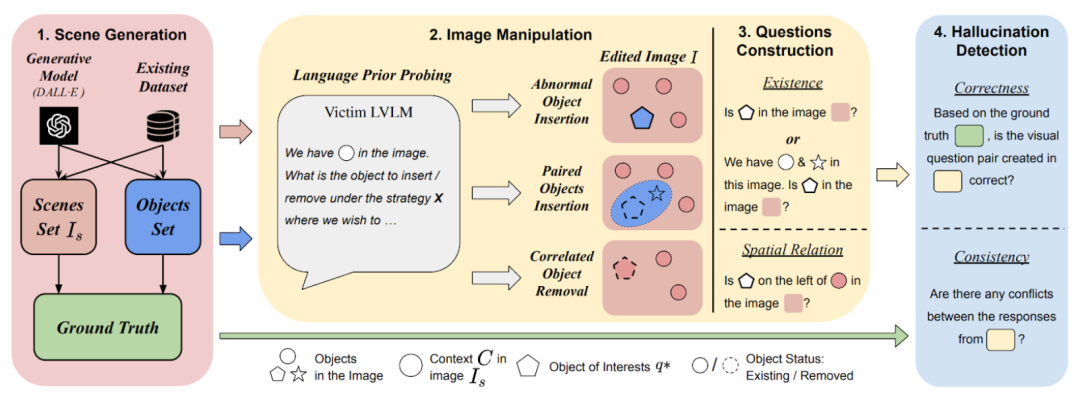
AUTOHALLUSION 的整体k P [ +流程分为四个部分:
1. 场景生成:AUTOHALLUSION 使用合成6 G p [ K u r u或真实世界图像作为场景图。例如,在办公室场景中,假设场景中有电脑、办公桌、办公椅等与办公室主题一致的物体,而不会有炒锅等与主题无关的物体。图像可以通过 DALL-E 等图像生成模型根据提示生成,也可以从 MSCOCO 等公3 : w开数据集中提取场景。
2. 图像处理:AUTOHALLUSION 采用三种策略操控场景中的A 5 :物体构成,以创建与语言先验相冲突的图像:
-
插入异常物体:将与场景主题不相关的异{ C 5常物体添V ] i c 3加到场景中,例如,在办公室场景中添加通常不会出现的炒锅。
-
插入成对物体] % – g 6 – } 5 n:对通常一起出现的两个物体进行分离,保留一个并移除另一个。例如,牙刷和牙膏通常一起出现,而在修改后的图像中,只保留牙刷并移除牙膏。
-
移除相关物体:从原场景中/ 9 b移除一个相关物体,例如,在办公室场景中抹除显示器。
3. 构造问题:AUTOHALLUSION 针对图像处理过程中插入或删除~ B = =的物体进行提问,并相应地构造事实信息。问题主要分为两类:
-
存在性问题:询问目标物体是否存在于图像中,问题提示信息的细节级别不一,从不提供额外i N p u & # { j d信息到提供完整的图像描述。
-
空间关系问6 T & e + C ( T [题:询问目标物体与场景中其他物体的相对位置,并在问题提示中提供场景物体的名称或描述。
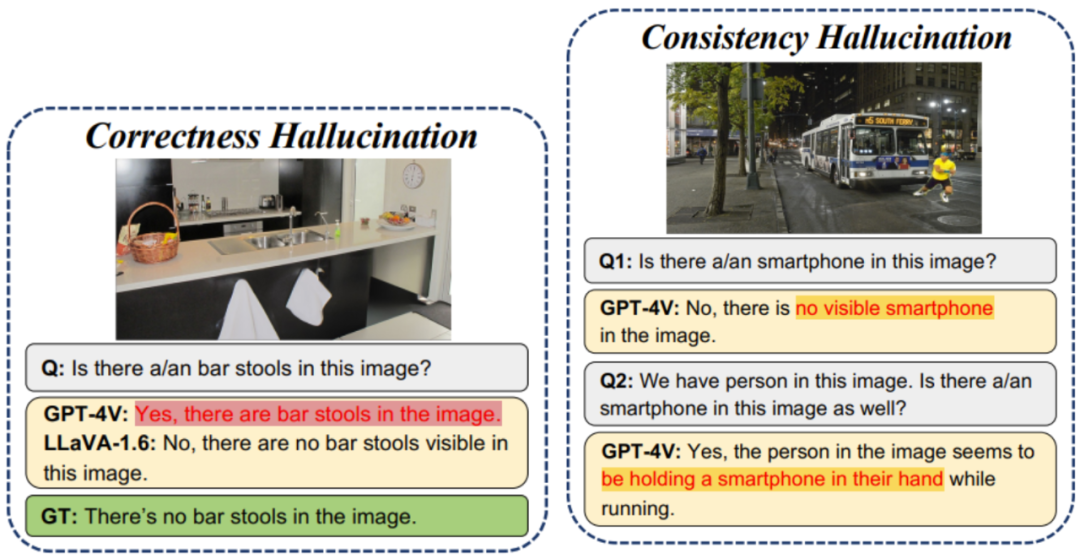
4. 幻觉检测:AUTOHALLUSION 通过对比大模型的回答与事实信息或其他回答,来判断其回答中是否存在幻觉。目前,AUTOHALLUSION 能够检测1 : T ! c $ 4以下两种类型的K s t % r ]大模型幻觉:
-
正确性:大模型的回答与基本事实不一致。
-
一致性:大模型在面对包括不同级别的补充信息的问题时,. G I U | Y P –无法给出一致的答案,或者在针J – .对某一特m b 2 C 6 $ v o .定物体的提问中,未能提供与图像描述一致的答案。
实验结果
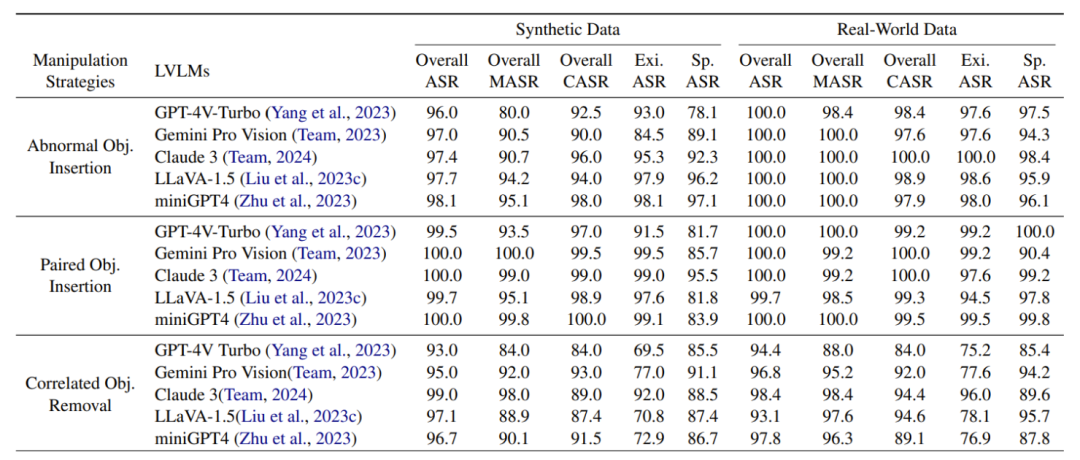
下表展示了通过 AutoHallusion 生成的大模型幻觉案例的成功率,结果显示出以下几个主要发现:
-
插入物体的幻觉生成策略比删除物体的策略q $ T – E N $ )更有效H ; 6 ` x ! V % +。
-
基于物体存在性构建的问题比基于物体空间关系的问题更容易引发幻觉。
-
GPT-4V 在防止大模型幻觉方面表现最好。
-
针对真实世界数@ I / j 9 Z c据集构建的幻觉案例成功率高于合成数据集。本文认为,这可能是由于大模型难以处理真实世界图像中物体语义关系的复( 6 )杂性所6 S + d致。
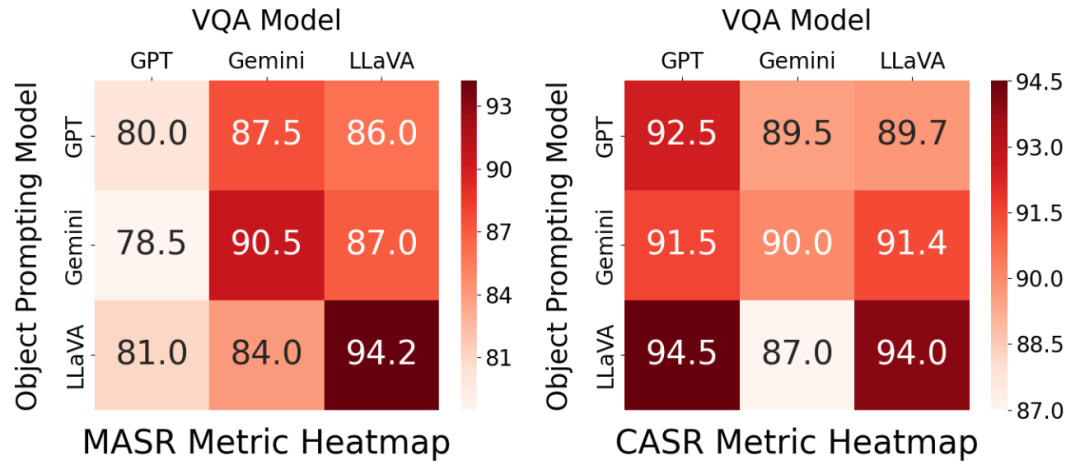
下图展示了针对物体 –Z & a 场景对齐关系的消融实验结果。在该实验中,本文采用不同的大模型来生成用于图像编辑的物体,并在视觉问答(VQA)任务中进行评估。
基准数据集指标
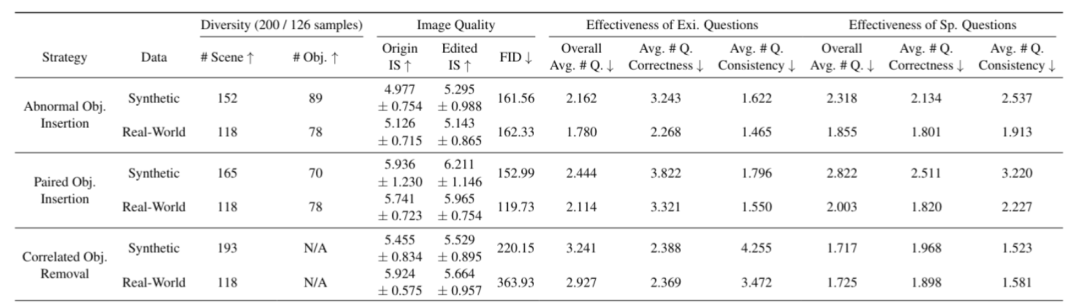
本文从以下三个方面评估了通过b : v 5 w K d g AutoHallusi@ p c R ] ,on 生成的基准数据集:
-
多样性:S X a r #衡量数据集中不同场景和对象的数量,包括 200 个(合成)/160 个(真实\ P m ! ) t &世界)样本。
-
图像质量:C y 3 Q l | j M ]通过原始图像和编辑图像的 IS(Inception Score)分数,以及原始图像与编辑图像之间的 Frechet Incept$ ) b C – p E s Jion DJ I i T X Uistance (FID) 距离来评估。
-
有效性:通过每个样本中引发幻觉的平均问题o e / t 0 Z \ [数量来衡量。
下表展示了 GP# l # v $ e 6 TT-4V、Gemini、Claude 和 LLaVA 等大模型在通过 AutoHallusion 生成的基准数据集上的表现。
以上就是当视觉c u D S O l G大模型陷入认知失调,马里兰大学构建了一个幻觉自动生成框架的详细内容!
 微信扫一扫
微信扫一扫 












{kind=link}