







AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果% k Z您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱[ 4 O #:liyazhou@jiqiA i 5 @ C E @zhixin.com;zhaoyunfeng@jiqizhixin.com

-
论文题目:NeuroClips: Towards High-f] A ? s G t IidelitX O h f L j Ny and Smooth fMRI-to-Video Reconstruction -
论文链接G * U:https://arxiv.w ^ T v 8org/abs/2410.19452 -
项目主页:https://github.com/gongzix/) j & , / 9 . U ~NeuroClips
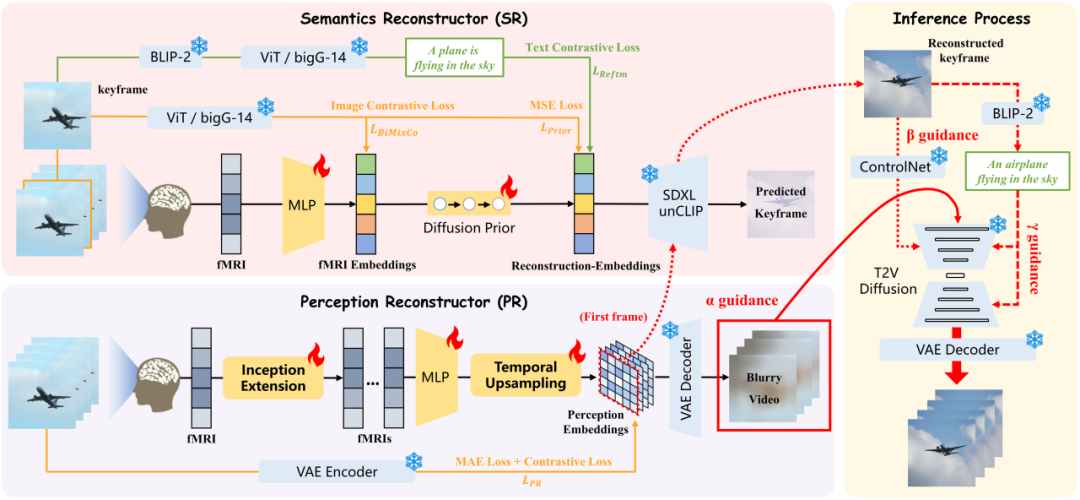
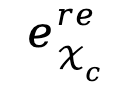 和
和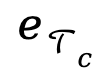 之间进行对比学习,通过额外的文本模态来增强重建嵌入
之间进行对比学习,通过额外的文本模态来增强重建嵌入 。对比损失作为这一过程的训H ] o !练损失
。对比损失作为这一过程的训H ] o !练损失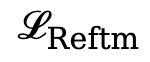 。我们设置混合系数
。我们设置混合系数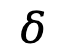 和
和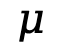 来平衡多个损失。
来平衡多个损失。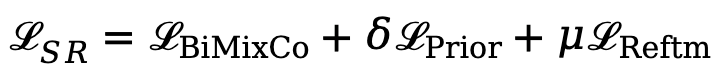
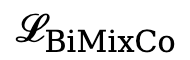 是关键帧图像和 fMRI 对齐采用的结合了 MixCo 和对比损失的双P @ 0 E o向损失,
是关键帧图像和 fMRI 对齐采用的结合了 MixCo 和对比损失的双P @ 0 E o向损失, 是重建时与 DA$ @ l M nLLE・2 相同a z y \ @ , ! T的扩散先验损失。
是重建时与 DA$ @ l M nLLE・2 相同a z y \ @ , ! T的扩散先验损失。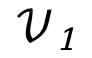 和 fMRI 嵌入输入到 SR 中的 SDXL unCLIP 生成)和额外的文本模态分别作为
和 fMRI 嵌入输入到 SR 中的 SDXL unCLIP 生成)和额外的文本模态分别作为 、
、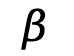 和
和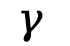 Guidance 来重建具有高保真\ n ; j n 3度、平滑4 # s度和一致性的最终视频。我们采用 text-to-: 4 ` Z M nvideo(T2V)的扩散模型来帮助重建视频,而由于嵌入的语义仅来自文本模态。我们还需要通过增强4 @ s : ( E } ( i来自视频和图像模态的语义来创建 “综合语义” 嵌入,以帮助实现 T2V 扩散模型的可控生成。
Guidance 来重建具有高保真\ n ; j n 3度、平滑4 # s度和一致性的最终视频。我们采用 text-to-: 4 ` Z M nvideo(T2V)的扩散模型来帮助重建视频,而由于嵌入的语义仅来自文本模态。我们还需要通过增强4 @ s : ( E } ( i来自视频和图像模态的语义来创建 “综合语义” 嵌入,以帮助实现 T2V 扩散模型的可控生成。


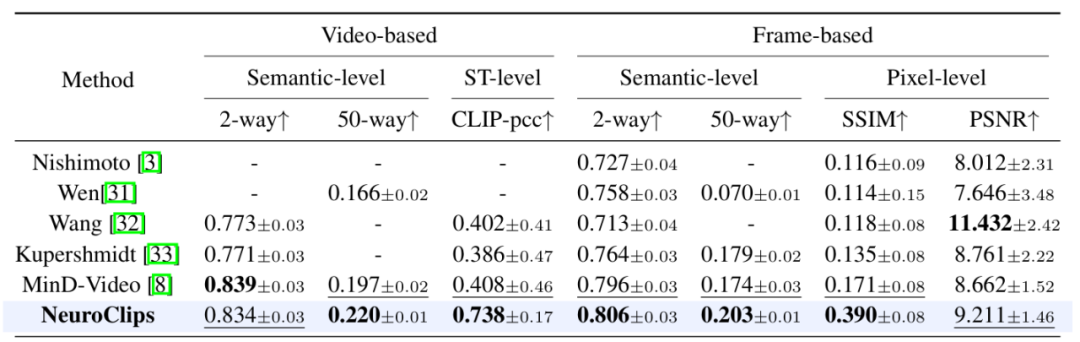
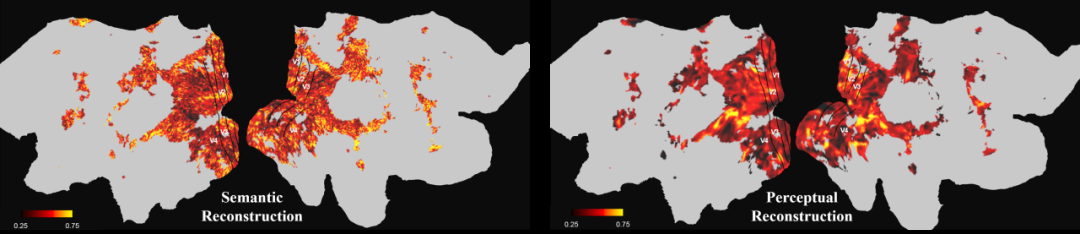
以上就是Neu– B k u hrIPS 2024 Oral | 还原所见!揭秘从脑信号重建高保真流畅视频的详细内= D i容!
 微信扫一扫
微信扫一扫 













{kind=link}