







AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。: M % . x 5 j投稿邮箱:liZ % Q r f N Nyazhou@c e . 1 / \ E | bjiqizhixin.co| Y Y 7 w Rm;zhaoyunfeng@jiqizhixinW p y y.com

-
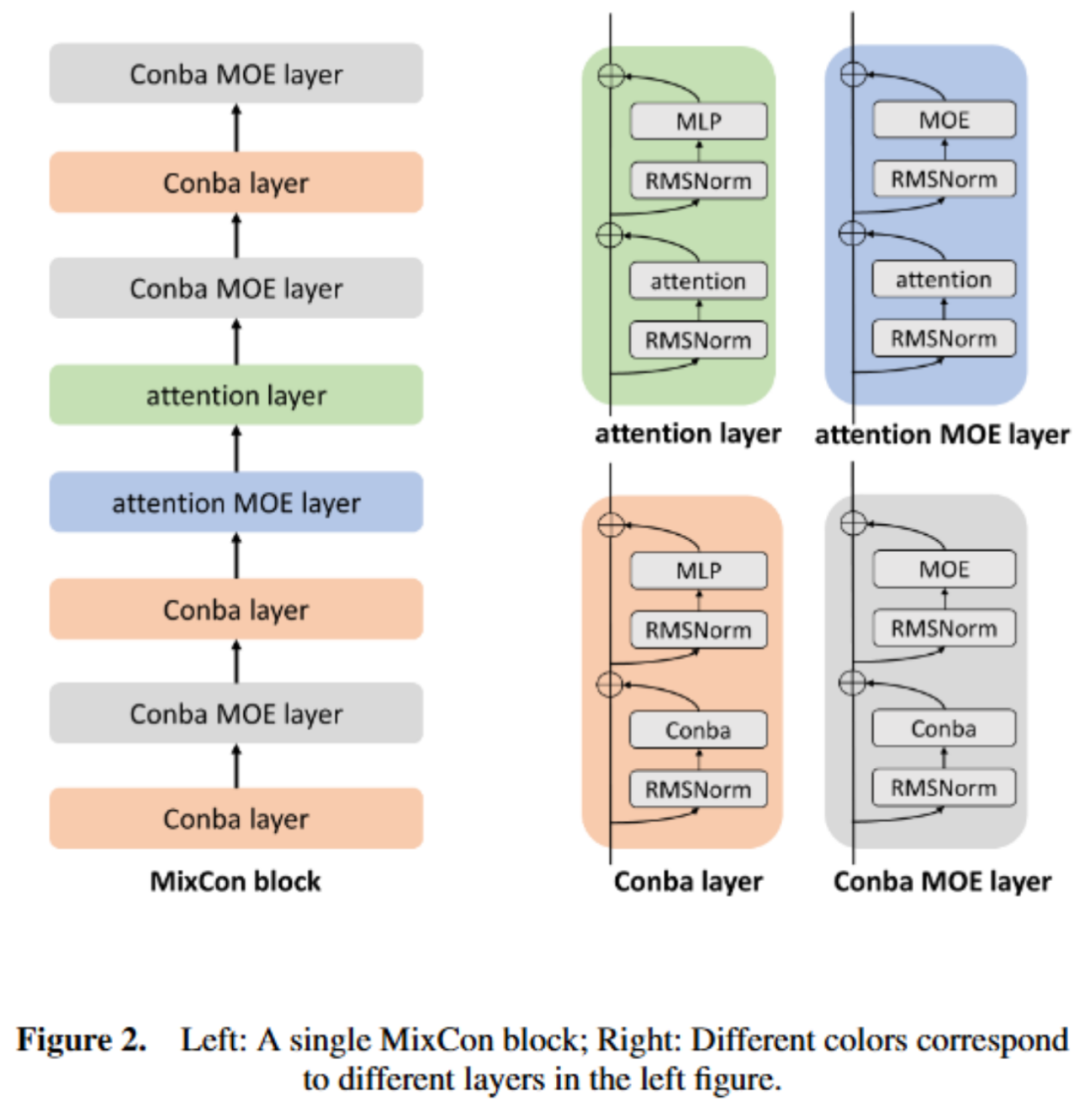
论文标题~ ` t:Mv & – f j T ZixCoH ] J hn: A Hybrid Architecture for Efficient and Adaptive Sequence Modeling -
论文地址:https://zhouchenlin.githu] 6 V ] N Vb.io/Publications/2024-ECAW } \ G O ! }I-MixCon.pdf
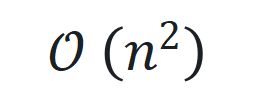 降低到
降低到 或
或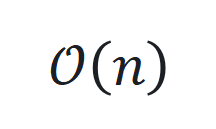 ,但在处理长序列时可能会面临性能下降和计算开销增加的问题。
,但在处理长序列时可能会面临性能下降和计算开销增加的问题。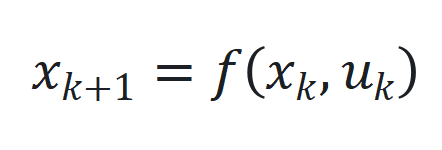 和
和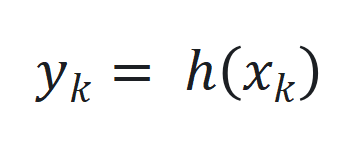 ,其中
,其中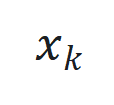 、. y J M * m c 8
、. y J M * m c 8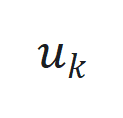 和
和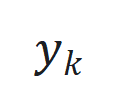 分* S c N别为时间步
分* S c N别为时间步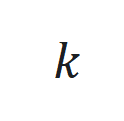 的状\ ) L 7 / i态、输入和输出,
的状\ ) L 7 / i态、输入和输出,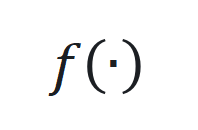 和
和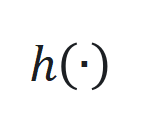 是非线性函数,可由神经网络近似。
是非线性函数,可由神经网络近似。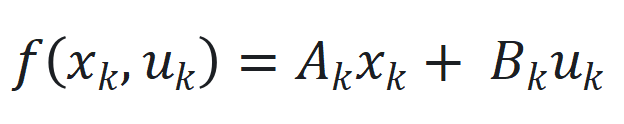 ,其中
,其中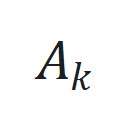 和
和 是可学习参数矩阵。
是可学习参数矩阵。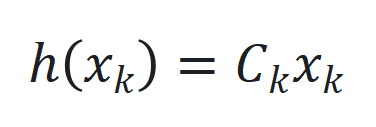 ,
, 是可学习参数矩阵。
是可学习参数矩阵。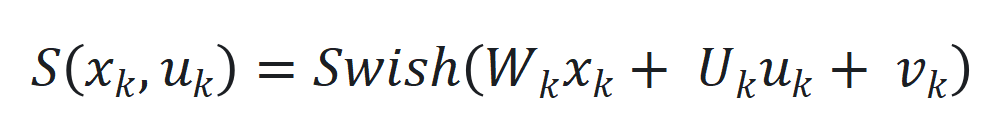 ,以及引入延迟状态
,以及引入延迟状态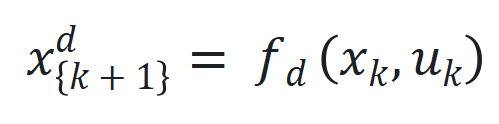 和动态状态缩放机制
和动态状态缩放机制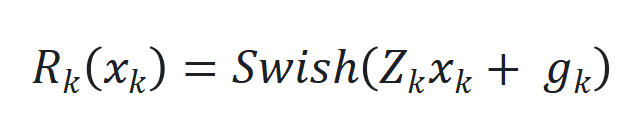 。
。 来捕捉长程依赖和适应序列动态变化。
来捕捉长程依赖和适应序列动态变化。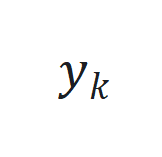 和期望输出
和期望输出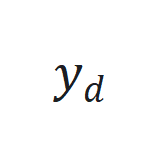 之间的跟踪误差
之间的跟踪误差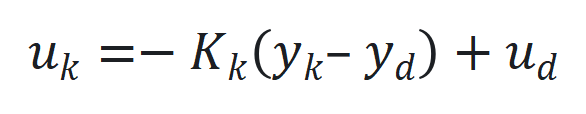 。
。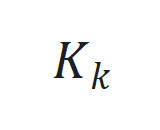 通过
通过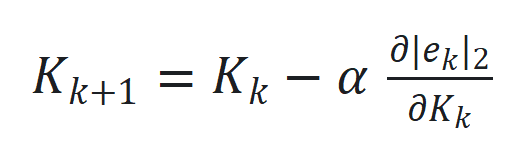 更新,其中
更新,其中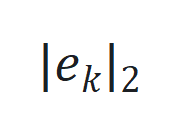 是跟踪误差向量
是跟踪误差向量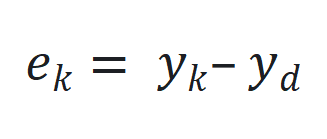 的 2 范数,
的 2 范数,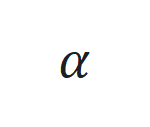 是学习率。
是学习率。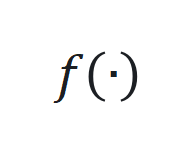 的非线性部分和观察函数
的非线性部分和观察函数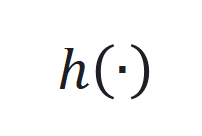 ,通过端到端训练确定最佳参数。
,通过端到端训练确定最佳参数。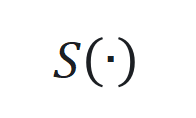 用 SwiGLU(基于 Swish 和 GLU 的混合激活函数)近似,其公式为
用 SwiGLU(基于 Swish 和 GLU 的混合激活函数)近似,其公式为 。
。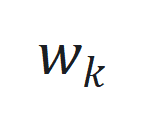 和观察噪声
和观察噪声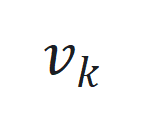 ,
,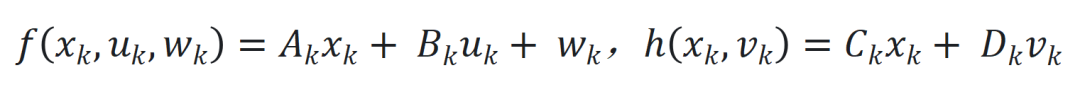 ,增强模型对扰动的适应性。
,增强模型对扰动的适应性。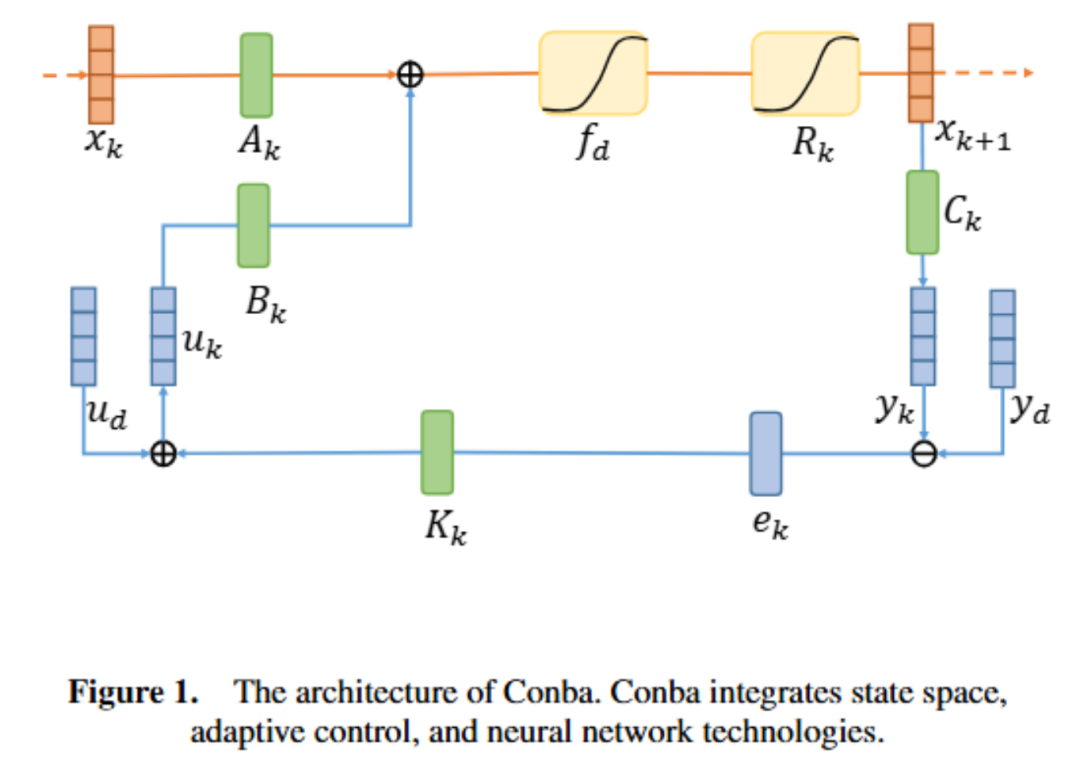
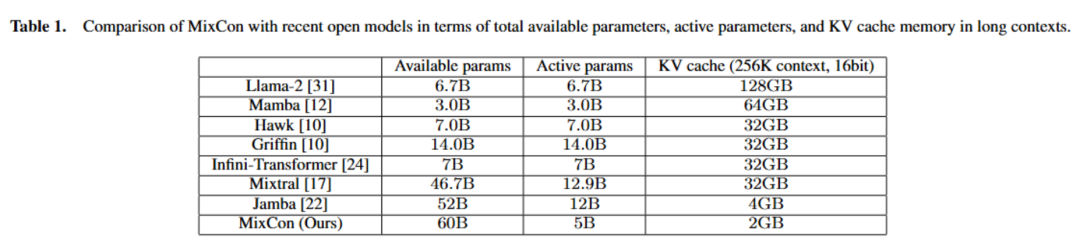
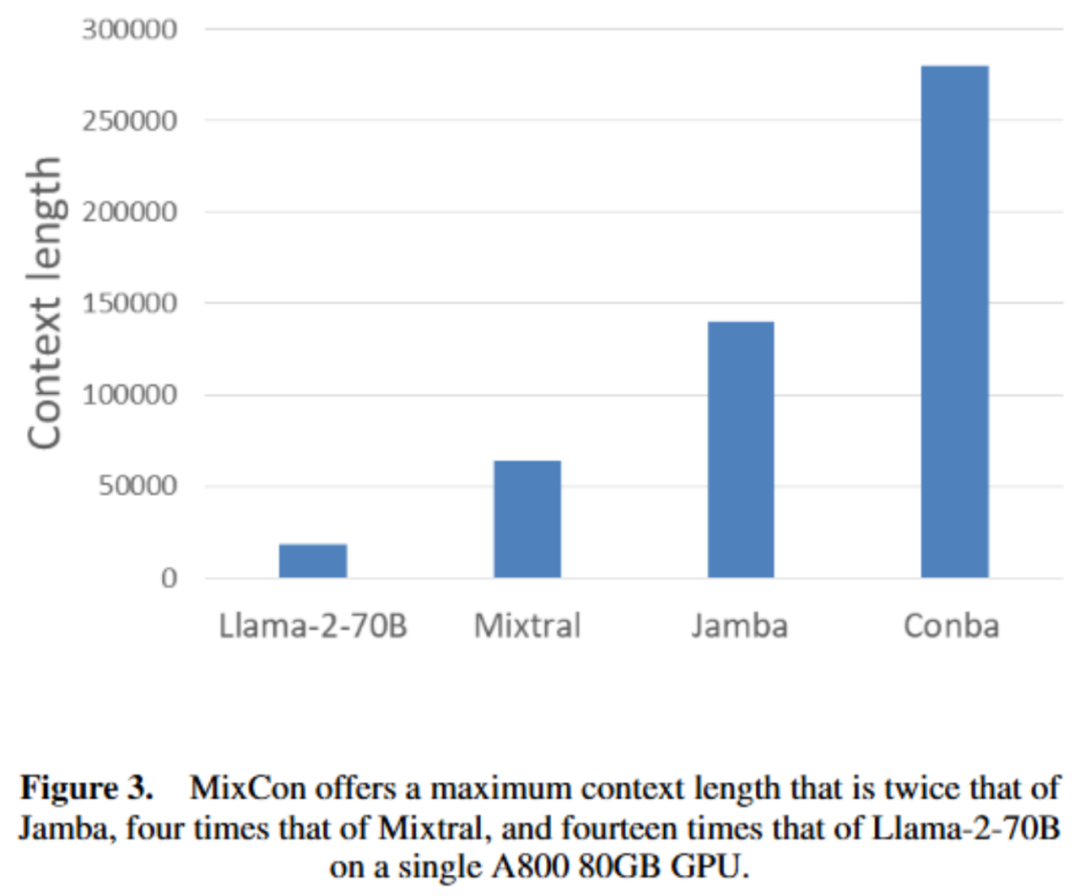
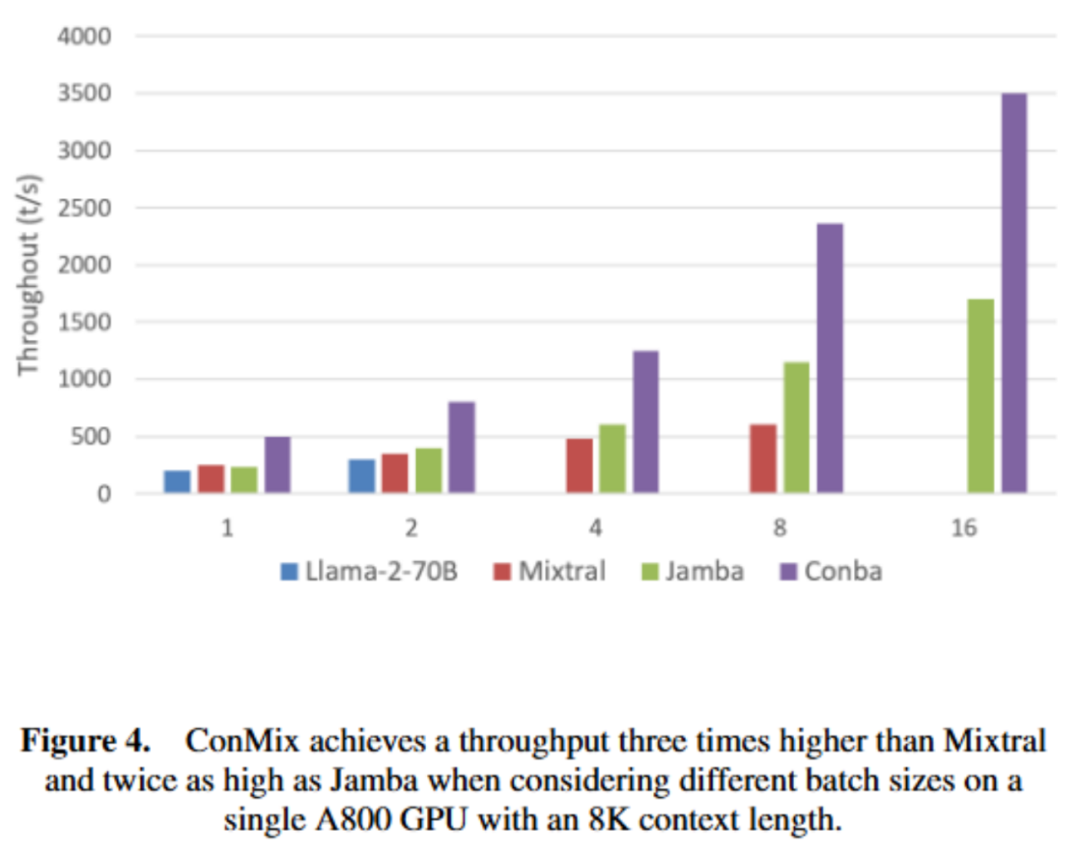
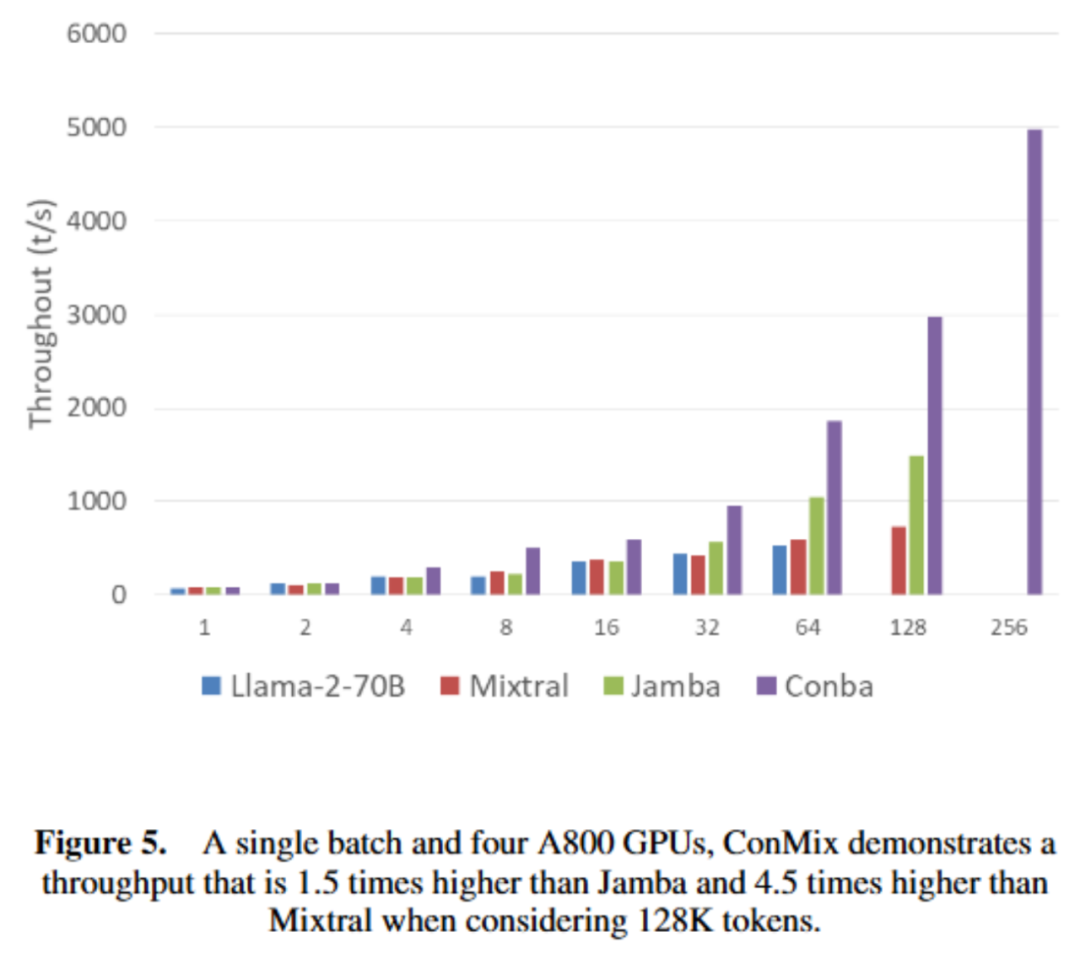
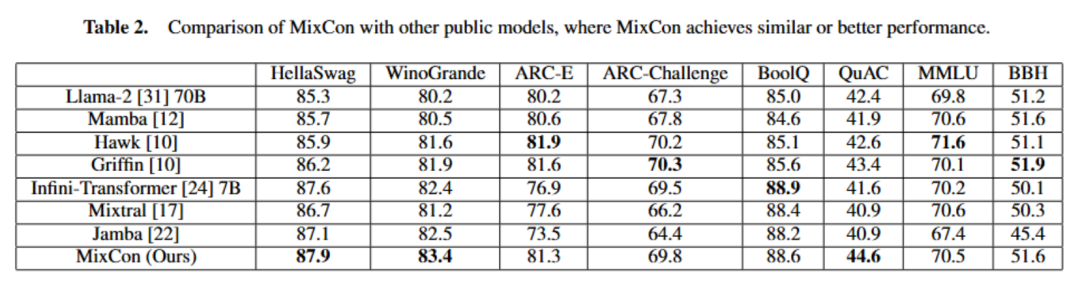

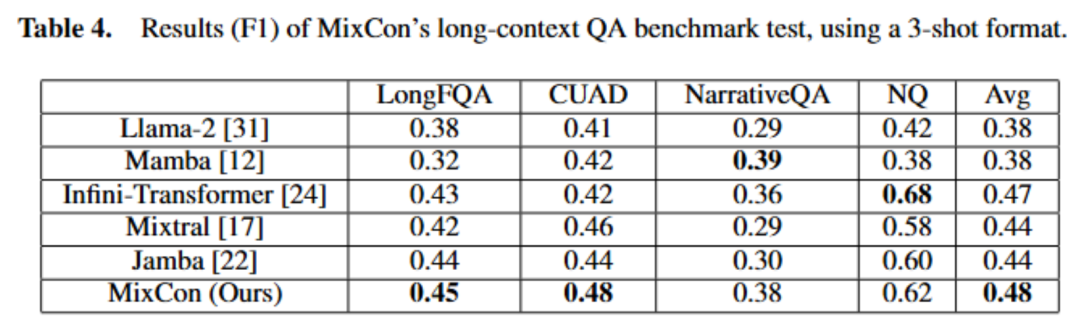
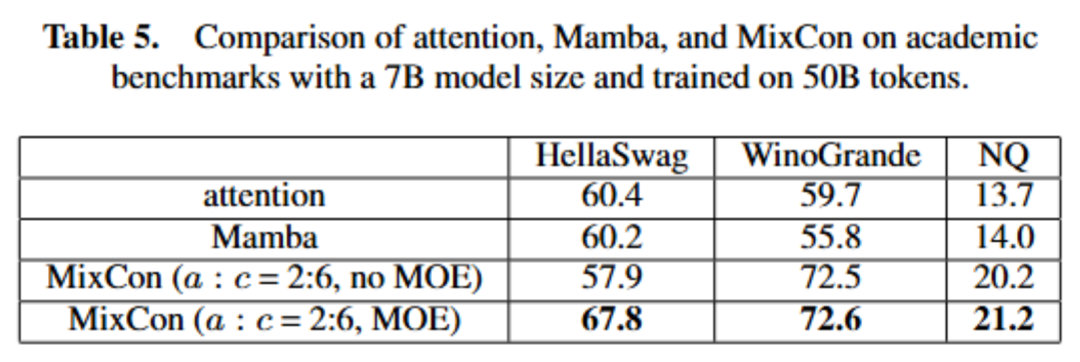
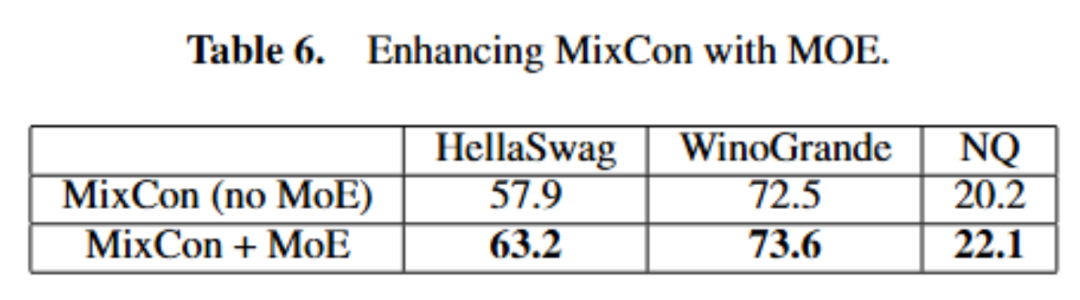
以上就是北大林宙辰团队全新混合序列建模架构MixCon:性能远超Mamba的详细内容!
 微信扫一扫
微信扫一扫 










{kind=link}