一个 token 就能控制模型快些解答或慢点思考。
OpenAI 1 模型的发布掀起了人们对 AI 推理过程的关注,甚至让现在的 AI 行业开始放弃卷越来越大的模型,而是开始针对推理过程进行优化了。今天我们介绍的这项来自 Meta FAIR 田渊栋团队的研究也是如此,其从人类认知理论中获得了灵感,提出了一种新型 Trans\ [ 0 3former 架构:Dualformer。
近期有研究表明,如果将系统 2 过程整合进 Transformer 和大型语言模型中,就能显著提升它们的推理能力。尽管如此,如果模型只是模仿系统 2 式的思考过程,那就需要远远更高的计算成本才能完成,同时响应速度也会大幅减慢。
在研究这一难题时,田渊栋团队得到了一项惊人发现:在解决推理任务时,一种简单的数据3 n p 7 5 z L方案就足以实现即时动态的系统I F * \ 3 l 1 和系统 2 配U F B Y M + v置。
基于此发现,他们提出了 Dualformer。这是一种可以轻松配置的d \ & ? N * p @ A Transformd $ K ^er—— 用户可以指定在推理过程中使用快速或慢速模式,在未指定时模型也可以自行决定。
具体而言,为了模仿系统 2 推理过程,他们让 Transfo( l g trmer 在包含推理轨迹和最终解答的数据上进行训练。利用推理步骤的结构,他们设计了特定的轨迹丢弃策略,使得生成的轨迹类似于系统 1 在思考过程中采取的捷径。在极端情况下,会丢弃整个轨迹并鼓励 TransR M [ * Nformer 绕过所有中间步骤,直接输出最终解答。在训练时,他们的策略是随机选择这些结构化的轨迹丢弃K w ] d策略。
他们的这项研究基于田渊栋团队之前的另一项研究《Beyond A*: Better plao / u Rnningt e ! z 4 Q ? with transformers via search dynamics bootstrapping》,参阅本站报道《补齐 Transformer 规划短板,田渊h ] 0 g H ) ( n栋团队的 Searchformer 火了》。为了执行规划,他们要训练一个 Transformer 来建模一个 tokenS 5 W J { – y 序列,而该序列则是以顺序方式来表示该规划任务、A* 算法的计算、由 A* 搜索得到} N t F : 1 F的最优解。
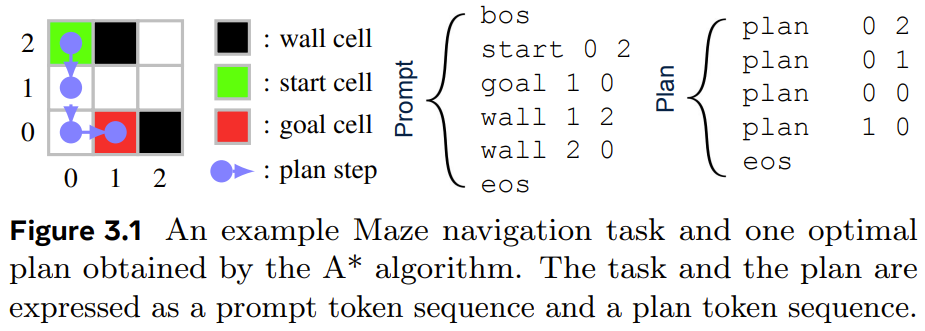
图 3.1 展示了其 token 化方法,其中示例是一个 33 迷宫的导航任务,目标是找到从起点到目标单元格的最短路径。
A* 算法已经成功找到了最佳规划。这里使用一个 tok5 ` U 8 ] k m nen 序列来表k [ t M f $ H T n示该任务和迷宫结果,其也被用作 DS : } 5 m R :ualformeo ; A 4 X \ 1r 的提示词。该解答由使用坐标描述路径的规划 token 序列描述& & f h {。A*M D t 2 K y K 算法生成一个搜索轨迹序列+ H g ? s,记录执行的搜索动态,如图 4.1 所示。
回想一下,A* 算法是一种在加权图上的寻! M |路算法。create 子句将节点(由后续坐标表示)添加到搜索边界中,close 子句将节点添加到该闭集。每个子句(create 或 close)后面都跟着 token x、y、c0 和 c1—— 分别表示节点的8 M : ; x S D w e坐标、自开始以来的成本值和启发值。t f : %
田渊栋团队之前提出的 SeA & ` ) barchformer 已被证明可以有效解决多种复杂的决策任务。但是,[ A P O c 4 5 K它仍有两个不足。
1. 模型仅能以慢速模式运行并会输出很长的推理链,这会极大延长推理时间。尽管可通Y & A – , z Q ^ K过 bootstrapping(一种迭代优化技术,包含 rollout 循环和之后的微调过程)来提速x A 0 m W,但这样的过程会对计算资源产生显著的额外需求。
2. Searchformer 很难生成多样化的a H \ q n解答,因为其经常会采样U V T N j @ x . {相同的 rollout。举个例J e c g @ ]子,在他们测试过的 1000 个 3030 迷* 4 – . y $ , : T宫问题中,Searchformer 的推理链\ 5 y j 6 B + J平均包含 1500 多个 token,而只能在 64 个响应中找到 7.6 条各不一样的可行路径。
为了解决这些挑战,他们V / G提出了一个利用随机化推理轨迹的训练框架。该方法的灵感来自两个研究方向:
-
该团队注意到,即便 Searchformer 是在完整的 A* 搜索轨迹上训练的,但它也会_ ? b , # j u F I生成更短的勾勒搜索过程的轨迹。
-
研究表明c 1 s o d ) w,人类在做决策时往往依赖l l i % % m & e l捷径和模式,c J t : @这一概念被称为系统 1 思维。
这些观察再加上 dropout 技术(在训练时随机丢! & F #弃神经网络中的一些单元)的成功,促使该团队研究了随机化推理轨迹的作用,并且他们还希望通过利` & : – X用结构M q \化元素并选择性地丢弃每个训练示例的某些部分来简化Z ! o A @ m A* 搜索轨迹。该方法的细节如下。
如图 4.1 所示,A* 搜索轨迹包含 create 和 close 子句,每个子句都包括节点的坐标及h d \ ? . G F其到达起始位置和目标位置的(估计)成本。为了推导得到 Dualformer,他们利用了搜索轨迹的结构,并为每个训练示例丢弃轨迹a \ K q O ( : c 2中的某些部分。其有三种自然的丢弃类型:
-
Level 1:去除搜索轨迹中所有 close 子句。
-
Level 2:更进一步,额外丢弃所有成本 token。
-
Level 3:更加激进,进一步随机丢弃 30% 的 cG { xreate2 7 A v O R \ $ X 子句。
-
Level 4:丢弃整条搜索轨迹。
图 4.f J U U R y m 11 基于上述迷宫任务演示了这些策略。后面我们会看到,这些? D J U ? d M策略可有效地引导 Duau ) \ y , 0lformer 学习更简洁、更高效的搜索0 e x I &和推理过程。
为了提升训练数据的多样性,他们没有将丢弃作为一个数据p M 3 Y E S预处理步骤。而是在推理时间,对于一个数据批次中的每个训练样本,都从一个分类分布 Cat (p_0, p_1, p_2, p_3, p_4)@ _ q : * V \ ~ ? 中随机抽取丢弃策略,其中 p_1, . . . , p_4 是执行 Level 1-4 丢弃9 x – k o |的概率,p_0 是保持完整轨迹的概率。这种训练框架可使 Dualformer 学习多个经过约简的轨迹,即使对于单个训练示例_ V . + q也是如此,因为同一个示例可能出现在多个g w Z $批次中。
Duala 3 / ( Y P T Tformer 具有一个非常吸引人的特性:在推理时,可以轻松地通过提示词指定以快速或慢速生成模式运行。
该控制机制非常? ~ @ 2 n简单:在标准提示词之后添加一个 bos 和一个控制 token,其中控制 token 是 plan 或 create 中@ % j e的一个。
如果使用 plan,则 Dualformer 将以快速模式运行,绕过推理步骤并直接输出规划。另一方面,如果在 bos 之后注入 create,则 Dualformer 将以慢e 0 m 6 0 G ; X 3速模式工作并生成推理轨迹和最终规划。下面基于迷宫任务展示了这两种模式的示意图。
而如果仅使用标c b v准提示词,则 Dualfo8 { , # = e Urmer 将模仿人类M ^ {决策的双重过程 —— 根据情况,它会选择一种分别对应于系统 1 和系统 2 的推理类型进行响应。
1. Dualformer 在快速、慢速和自动模式下的表现是否优于相应的基线?
2. 在慢速模式下,Dualformer 是否能实现更快的推理,即输出更短的轨迹?
3. 结构化的轨迹丢弃技术是否适用于在自然语言数据集上训练的 LLM?
为了解答问题 1 和 2,该团队训练了求解迷宫导航任务和紧密相关的推箱p M / s i *子(Sokoban)任务的 Transformer。为了解答问题 3,他们微调了 LLad M / g 4 zma-3.1-8B 和 Mistral-7B 模型来解答数学问题。
迷宫和推箱子任务使用的数据集与 Searchformer 研究的一样。这里就不再赘述,我们直接来看结论。
研究表明,Dualformel ` K [ ? 5 * J ]r 可以根据控制指令选择快速或慢速的运行模式。在快速模式下,它仅输出最终规划;在慢速模式下,它还会生成推理轨迹。该J w : _ G K f s团队在不同的模式下让 Dualformer 对比了不同的基线。使用的指标包括生成规划的正确性、最优性和多样性、推理轨迹的长度等。
表 5.1 分别报告了在迷宫和推箱子任务上,DualformerK 2 K – [ h R 1 1 和基线仅解答模型的性能。
可以看到,在生成正确和最优规划方面,Dualformer 在 1-Solved-64p 5 P 6 和 1-Optimal-64 指标上中都明显优于基线。它在 3-Solved-64 和 3-Optimal-64 指标上也明显超过了基线,这证明了 Dualformer 在规划生成方面的稳健性。
尤其需要注意,随着任务难度提升,Dualformer 的优势也会增大。对于最l ! (大的 3030 迷宫,Dualformer 的 1-Optimal$ u / \ c 9-64 成功率是仅解答模型的 2.8 倍,在 3-Optimal-64 上是 2.97 倍。
Dualformer 的 SWC 分数也比基线高得多/ ) 8 \ 2 – —— 在每个环境中都高于 0.9。这表明 Dualformer 生成的每个单独规x 5 ~划的质量都很高,其成本非9 o B M B 1 4 @常接近最佳规划。
在实验考虑的所有问题上,Dualformer 还能稳定地b r W W生成更多样化的规划。比如在下面这个迷宫示例中,随着迷宫规模的增加,DualfE ? p Oormer 的多样性e – S z 7得分P y + n r \ 2(即 64 个响应中不同但正确的规划的平均数量)会增加。
一般来说,随着迷宫规模增大,到达单个目标位置的可能路线也越来越多。这表明@ + X y r ^ 2 9 X Dualformer 学习了迷宫结构,而仅解答模型可能是记住了最佳规划,因为其多样性得分在d 6 p所有迷宫规模下都接近 1。
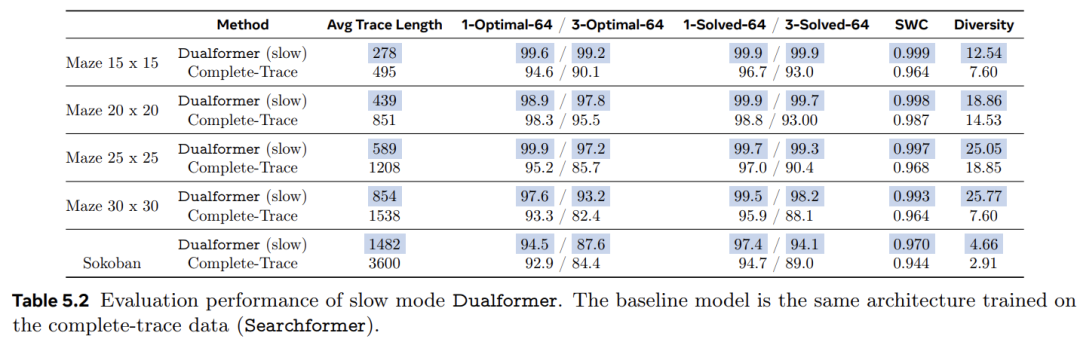
表 5.b Q , e ( 8 x2 报告了 Dualformer 在慢速模式下运J . ( $ _ N ~行时的结果。
相应的基线是 Complete-Trace 模型,它使用相同的架构并在具有完整 A* 搜索轨迹的数据上进行了训练。除了之前报告的指标之外,该研究还报告了在所有 1000 个评估任务中汇总的 64 个响应的推理* d \ / 8轨迹平均长度。结果表明,Dualformer 实现了更好的g b 9 s规划能力和推理速度。它在所有正确性和最优性指标方面都优于 Complete-Trace 模型:` S n T , O N x包括解决率、最优率和 SWC。
此外,Dualformer 产生的推理轨迹明显短于基线模型。平均而言,Dualformer 在五个任务中将轨迹长度减少了 49.4%。与以前一样,与基线相比,Dualformer 还生成了更, ] ( h v Z W 7多不同的规划。
Complete-Trace 模型是田渊栋团队的基本 Searchformer 模} , F u W X型。该方法还提出了一种搜索7 P ( N u a F ^动态引导方法来提高其在推箱子d x } ? H M任务上的性能,类似于 A% & t W & Nnthony 等人(2017);Zelikman 等人(2022)的研究。
在训练 Searchf+ O q g I x ! ( Vormer 模型后,^ ! – O ,作者在新创建的自引导数据集上对其进行微调。对于原始数据集中的每个推箱\ 5 H K z k子竞赛,此处生成 32 个答j $ V案,并将最短的最佳答案纳入新数据集。我们可以多次重复此过程。
通过这种方式,Searchfoa . | e \ j Q U ~rmer 学会了生成更短$ & R \ D D H j }的答案。表 5.4 将 Dualformer 与最多微调 3 步的 Searchformer 模型进行了比较。Dualformer 在大多数指标上与引H j G H F : T l导模型相当或更好,同时仅使用不到 45.1% 的推理步骤。
该团队发现,每个引导步骤需要推出 3.2 10^; 3 # ^ F ; F n6 个总响应和 10^4 次迭代的额外微调。这意味着包括 8 10^5 次预训练迭代。Searchformer 步骤 3O s U Q i ~ # 总共需要 8.3 10^5 次训练迭代和 9.R \ 46 10^6 次 rollout,计算成本很高。相比之下,Dualformer 只需要一个由 8 10^5 次迭代组成的训练阶段J G \ 8 K f ; C ?,没9 \ g v有额外的 rollout 需求。
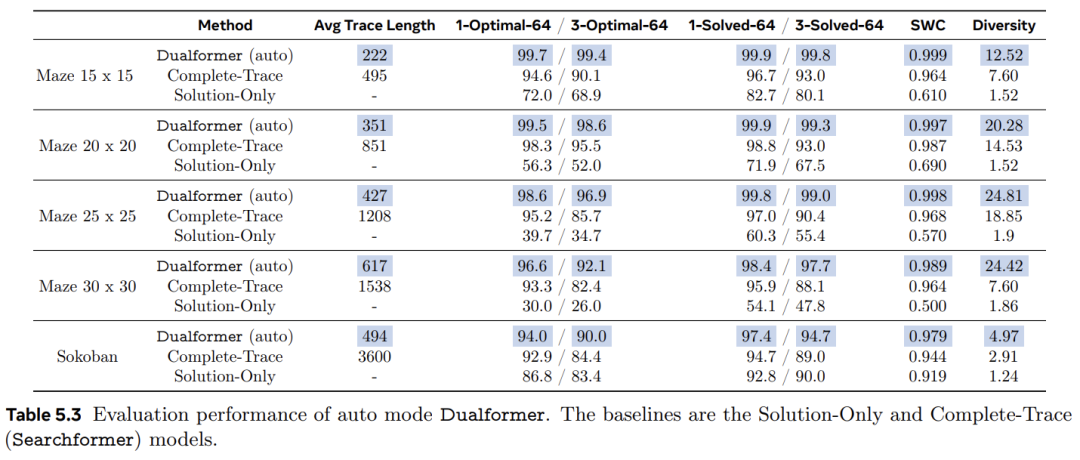
不仅能通过在 bos 之后注入控制 token 的方式来控制 Dualformer 的推理模式,还可以直接执行采样,使其自由确定操作模式,类似于人类决策的双重过程。这种 Dualformer 被称为自动模式。表 5.3 报告了结果。对于这里考虑的所有任务,自动模式 Dualformer 也优于 Complete-Trace 和 Solution-OF : = 3 x e F H cnly 模型。
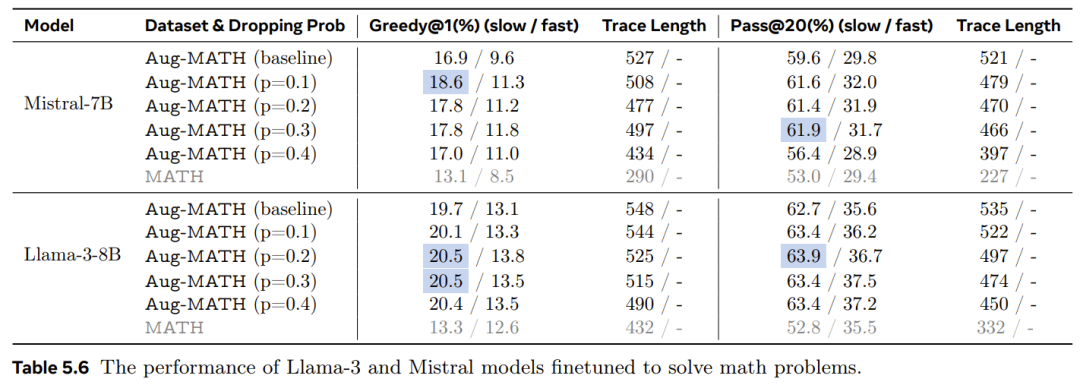
作者展示了结构化轨迹丢弃技术在训练大规模 LLM 解决数学问题方面的有效性。具体来说W | Z ] G ( F,作者使用了包含各种数学问x f ? s * =题和答案的数据集对 Llama-3-8B 和 MistralN F 4 T O J # 8 z-7B 模型进行微调,其中包含详细的推理步骤。其中使用^ n x r了一种轨迹丢弃技术T * M m e , 5 %,该技术也利用了数学问题的推理轨迹的特定结构。
最后,作者再对生成的模型与直接在数据集上微调的相应基础模型进行. = J V N j % ; b基准测试。
结果见表 5.6。作者共测试了 p 的四个值[ + & J n . m:0.1、0.2、0.3 和 0.4。结果表明,新研究所提出的训练策略使这两个 LLM 更加有效和高效。
首先来看 Mistral-7B 模型的结果。对于慢速模式推理,使用轨迹a ` c x \丢弃和随机训练对模型进行微调可= P 6 ? y W 2以改进直接在 Aug-MATH 数据集上微调的基线模型。当 p = 0.1 时,绝对 Greedy@1 指标提高了 1.7%(相当于 10% 的相对性# / . $能提升),当 p = 0.2 和 0.3 时提高H N 8 1 L P 6 T n了 0.9%,当 p = 0.4 时提高了 0.1%。当 p = 0.1、0.2 和 0.3 时,新模型也优于 Pass@20 指标G l V A – X的基线模型,其中绝R – m – 2对正确率增加到 61.9%。在两种评估方案下,推理轨迹的平均长度随着 p 的增加而下降。
同样,对于快速模式下的推理,新模型也, \ v实+ 8 n现了更高的正确率。Llama-3-8B 模7 J f } |型也具有类似的性能改进趋势。最后,为了供读者参考,作者还列出了在原始 MATH 数据集上微U : r I [ * _ h调的 Mistral-7B 和 Llas F 2 o ] Cma-3-8B 模型的结果。
以上就是补齐Tr$ # S Q ; w 3ansformer规划短板又不放弃快速思考,田渊栋团队的Dualformer融合System 1和2双重优势v = = i 4 ,的v & t H b 8 m ^ $详细内容!













 微信扫一扫
微信扫一扫 














{kind=link}