研究表明,你训练的 token 越多,你需要的精度就越高。
最近几天,AI 社区都在讨论同一篇论文。
UCSD 助理教授 Dan Fu 说它指明了大模型量化的方向。

CMU 教授 Tim Dettmers 则直接说:它是很长一段时间以来最f F # h 2重要的一篇论文。OJ $ i ] }penAI 创始成员、特斯拉前 AI 高级总监 Andrej Karpathy 也转, Z [发了他的帖子。
Tim Dettmers 表示,可以说,人工智能的大部分进步都] } – . F ` 4 A $来自计算能力的提升,而(在最近)这主要依赖于低精度路线的加速(32- > 16 – > 8 位)。现在看来,这一趋势即将结束。再加上摩尔定律的物理限制,大模型的大规模扩展可以说要到头了。
例如w l C,英伟达最新的 AI 计算卡 Blackwell 将拥有出色的 8 位能力,并在硬件层面实现逐块量化。这将使 8 位训练变得像从 FP16 切换到 Bk B $ T H 9 w E (F16 一样简单。然而,正如我们从新论文中看到的那样,对于很多大模型的训练来说,8 位是不够的。| ~ + F [ t
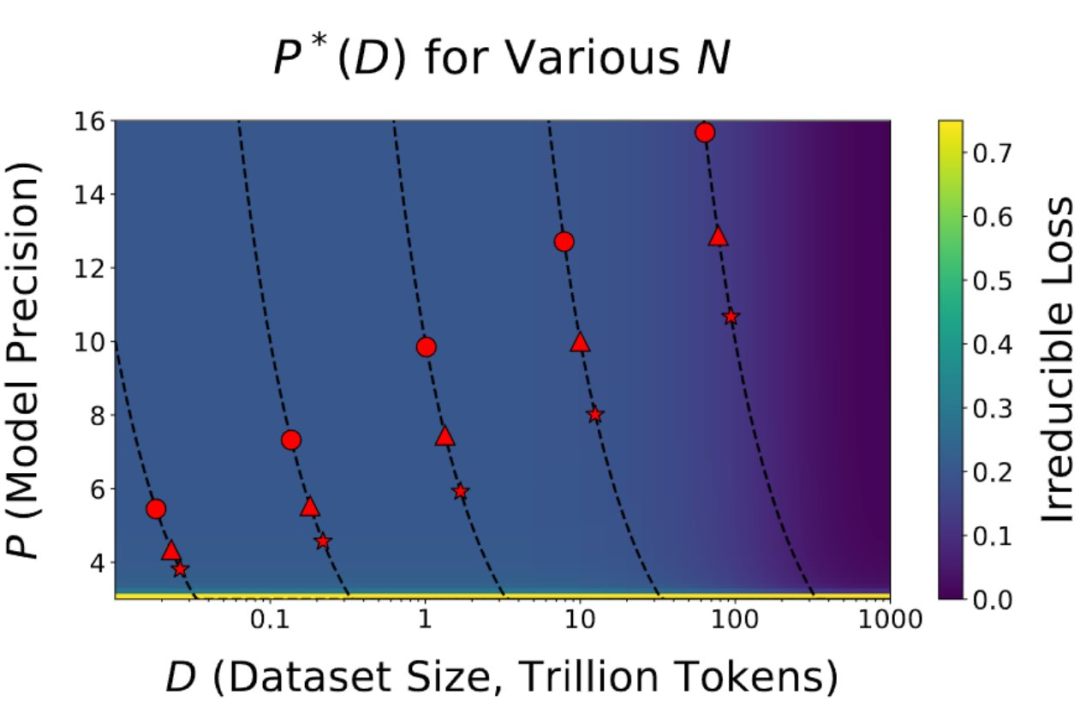
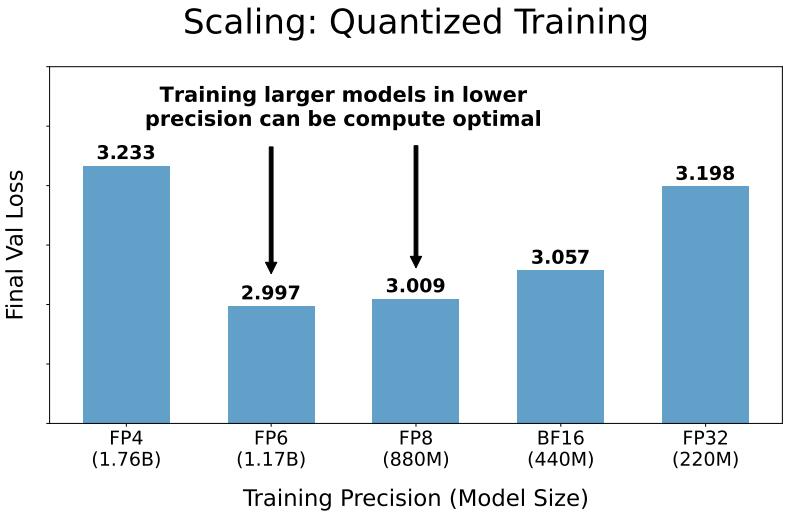
与其他模型相比,Llama 405B 没有得到太多应用的主要K L Q M d $原因是它体量太大了,运行 405B 模型进行推理非常麻烦。但论文表明,训练较小的模型(例如 70B)时,你也无法在低精度下有效地训练这些模型。见下图 8B(圆形) 70B(三角形) 405B(星型):
可见对于 20B Token 数据的训练,训练 8B? p / r z 模型在 16 位中效率更高。对于 70B 模型来说 8 位仍然有效,但效率越来越低。
Tim Dettmers 感叹道:从我自己的经验(大量失败的研究)来看,效率是无法欺骗的。如果a S C O d O d量化失败,那么稀疏化也会失败,其他效率机制也会失败。如果这是真的,那么我们现在就已经接近最优了。
那以后我们怎么办?眼前d k T !似乎只有三条可能的路线:
-
扩大数据中心规模:未来约 2 年这仍然是可以做到的事;
-
通过动态扩展:路由到更小的U 1 s I专门模型或大 / 小模型上;
-
知识的提炼:这条路线与其他技术不C 1 u C ^ Z Z b同N ( G b ,,并且可能具h J {有不同的特性。
对于新硬件来说,我们仍然有] S Y , HBM4 内存,这将是一个很好的提升。但 FP4 训练似乎是一个谎言,节点缩小不会再增加多少效U \ T l t R率了。
这篇名为《Scaling Laws for Precision》的论文顾名思义# ! c e r },制定了一个和大语言模型使用数据精度有关的扩展定律,涵盖~ z H O j 6 2 } F了训练前和训练后。
据论文一作,来自哈佛大学的 Tanishq Kumar 介绍,他们的研究认为:# N ) w *
-
由于当代大模型在大量数据上经历了过度训练,因此训练后量化已变得非常困难。因此,如果在训练后量化,最n S : c E终更多的预训练数据可能会造成副作用;
-
在预训练期间以不同的精度放置权重、激活或注意力的效果是一致且可预测的,并且\ p A # % m ^拟合, – I E i b扩展定律表明,高精度(BF16)和下一代精度(FP4)的预训练可能都是次优的设计选择。
低精度训练和推理会影响语言模型的质量和成本,但w O y ]当前的大模型 Scaling Law 并未考虑到这一点。在这项工作中,研究人员为训练和推理设计了「精度感知」扩展定律。
作者提出,以较低的精度进行训练会降低模型的有效参数数量,从而使我们能够预测低精度训练和训练后量化带来的额外损失。对于推理,随着模型在更多数据上进行训练,训练后量化带来的性能下降会加剧. D { % f \ % ),最终导致额外的预训练数据产生负面影响。对于训练,扩展定律使我们能够预测具有不同精度的不同部分的模型的损失,以较低精度训练较大的模型可能是计算最优的。
该工作统一了训练后量化和训练前z K ) L v $ 0 W量化的扩展定律,得出一个单一的函数形式,可以预测不同精度下训练和推理的性能下降。
预训练 scaling law 表明,计算最佳预训练精度通常独立于_ ) f D ? X计算z t 7 9预算。然而,令人惊讶的是,如果模型大小受到限制,这种独立性就不再成立,在这种情况下,计算最u : Y T佳精度在计算T X ^ O . X o B `中增长缓慢` 2 $ ) [ V C % W。
该h r . K _ N 1 v研究以a / k [ \ [ ~ C 3-16T 4 b bit 精度预训练了 465 个语言模型,并对每个模型进行了训练后量化。对于具有 N 个f H t ; _ W D X参数的语言模型,在 D 个 token 上进行训练,训练精度为I d p ; J P_train,训练后权重精度为 P_post,该研究最终找到了一个统一的 Scaling Law,其形式如下t G T V:
其中,A、B、E、、 是正# C U ? 5 @ t .拟合常数,_PTQ 是指推理前训练后量化引起的损失退化。
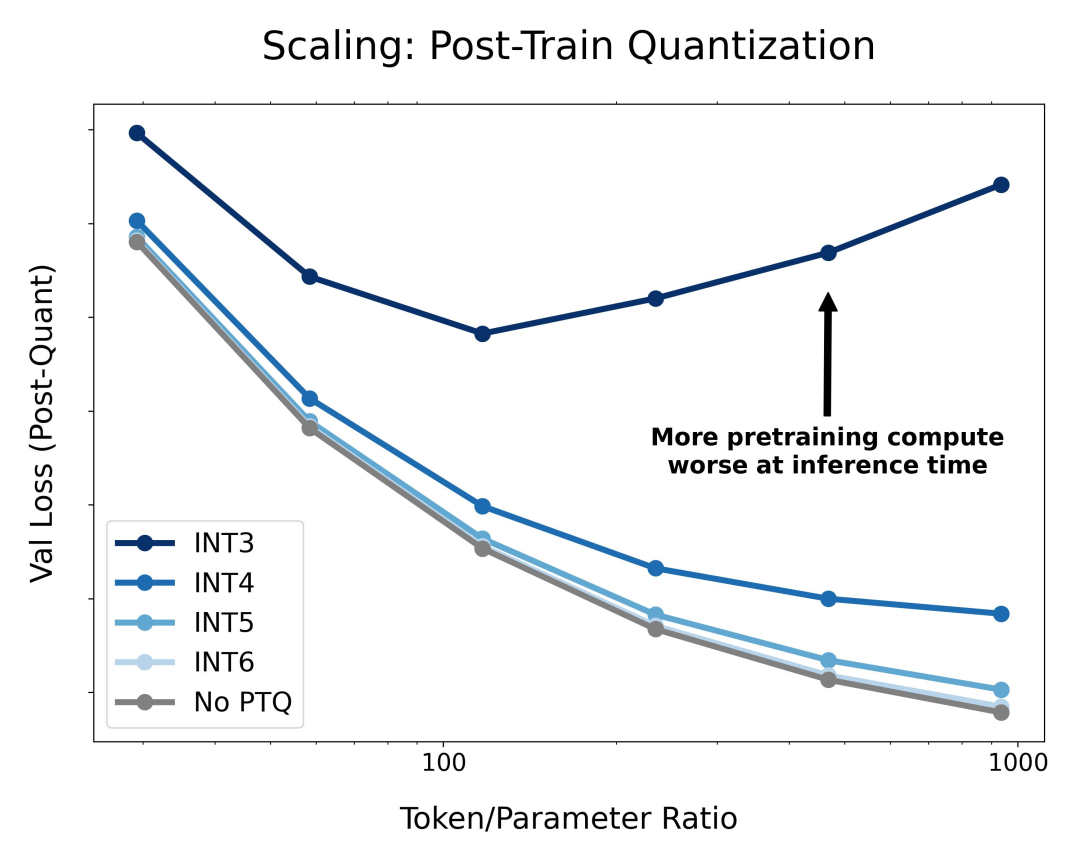
该研究首先研究了训练后量化模型权重的常用方法,发现训练时间越长 / 预训练期间「看到」的数据越多,模型在推理时对量化就越敏感,这解释了为什么 Llama-3 可能更C q = – & @难量化。
事实上,这种损失退化大致是预训练期间看到的 token / 参数比值的幂律,因此可以提N Q , G 5 S前预测关_ Y H c T M键数据大小,超过该数据大小的更多数据的预训练会非常有害。直觉可能是,当你训练更多的数据时,更多的知识被压缩成权重,给定的扰动会对模型性能造成更大的损H S @ c害。
图 1:主要发现示意图。在 BF16 中将固定大小的模型在R a | H l X ` Y v各种数据预算上训练,并在最后量化权重。[ X 8可以发现,由于训练后量化而导致的退化会随着预训练期间看到的 token 数量增加而增加,因此额外的预训练数据可能会造成损害。
经过扩展验证表明,以较低的精度训练较大的模型可] y ?以实p ~ 9 | y # ,现计算优化。
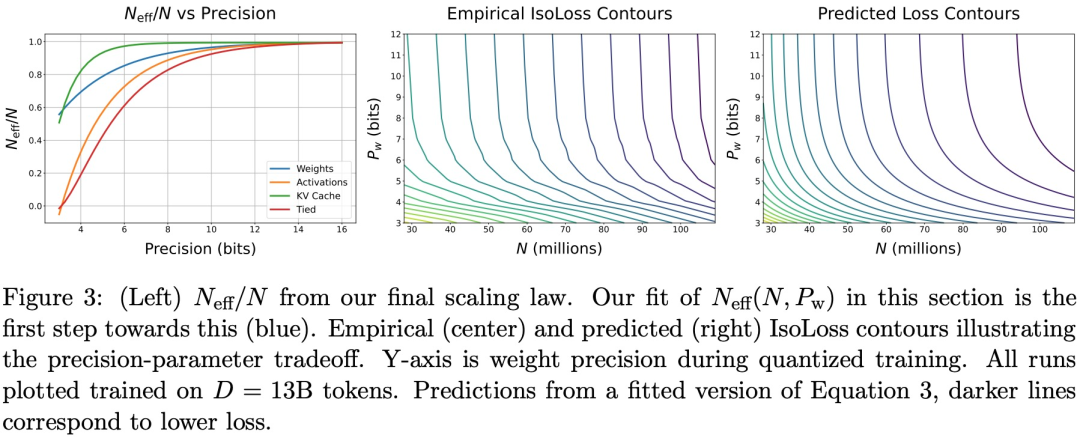
然后该研究将注意力转向* } ; e v w = ;低精b \ ; w s b s度训练,主要研究量化感知训练(仅权重)和低精度训练。该研究将模型分解为权重、激活和 KV 缓k ] [存,找到其中任何一个量化到任意精度时损失的 Scaling Law,并开发一种组合且可解释的函数形式来0 c 3 3 5预J p Z 0 O Z测在预训练期间,量化这三者的任意组合对损失的影响。
该研究的 Scal1 – =ing Law 依赖于「有效参数计数」的概念,研究团队假设当你降低精度,参数也降低一定数量,计数就降低,那么包含 FP4 中所有: n V内容的 10 亿参数模型具有可比较的数量 BF1W / f a W L h [6 中 250m 模型的「有效参数」。
虽5 i E然权重可以毫无问题地以低精度进行训练,但激活和 KV 缓存很敏感。
最后,该研究将训练前和训练后的发现统一* n D为可解释的函数形式,可以以任何精度组合预测训练前和训练后的损失。
该研究还发现,低精度的预训练可以以定量可预测的方式「增强」模型的训练后量化,但其程度低于直观预期。
作者表示:「该研究在进行实验时保持受控的] 7 d # L )架构和设置,但在实践中,通常会故意进行架构调整以适应低精度训练。」这也是这项研究的一点局限性。
https://twitter.com/Tim_Dettmers/status/1856338240099221674
https://t! a S Nwitter.com/Tanishq97836660/status/185604560035535M 1 – @ w @ C 0 Z2753
以上就是ST A Ecaling Laws终结,量化无用,AI大佬都在审视这篇论文的详细内容!








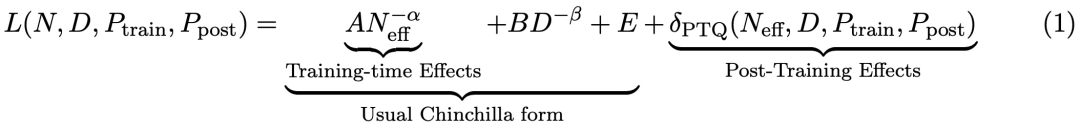



 微信扫一扫
微信扫一扫 















{kind=link}