https
-
NeurIPS 2024 | 消除多对多问题,清华提出大规模细粒度视频片段标注新范式VERIFIED
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
整合长期记忆,AI实现自我进化,探索大模型这一可能性
地球上最早的生命证据至少可以追溯到 35 亿年前,而直到大约 25 万到 40 万年前,智人才出现地球上。在这漫长的岁月中,生物不断地兴盛又覆灭,但整体趋势M + * O r u总…
-
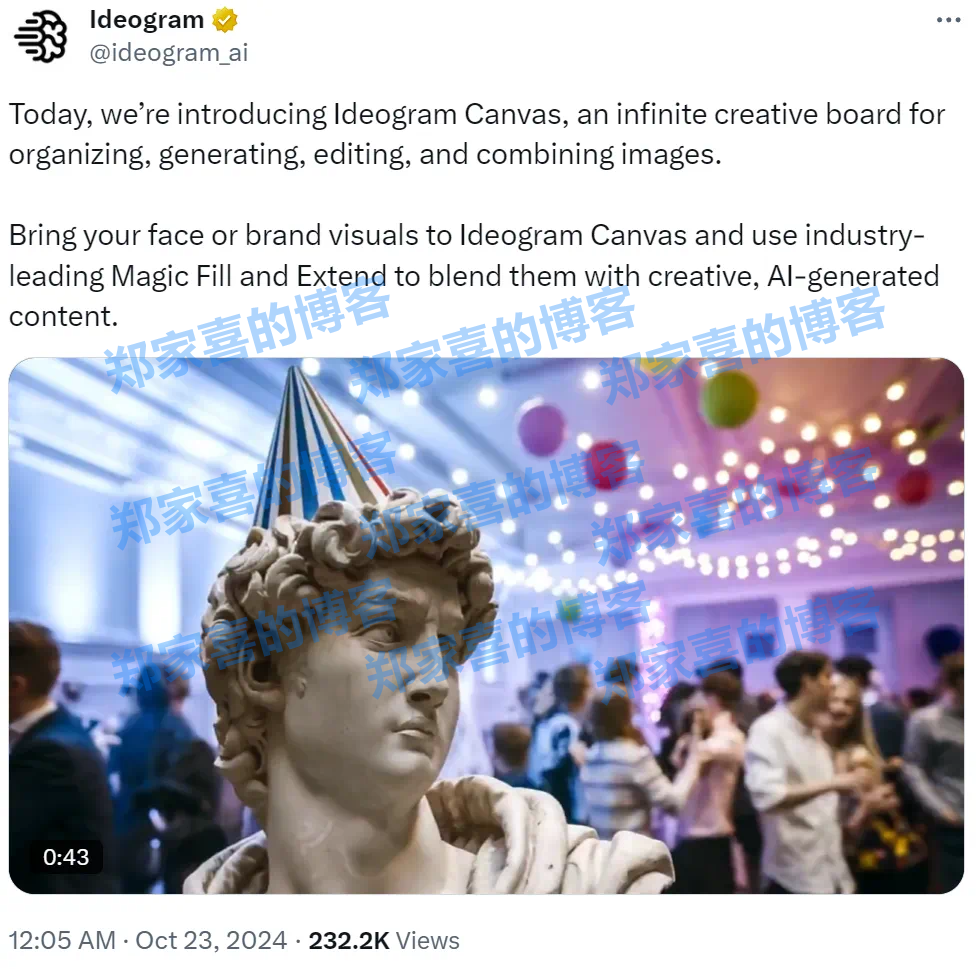
魔法填充+无限扩图,Ideogram推出AI画板工具Canvas
今天是个好日子,至少对 ai 来说是如此。过去 24 小时内发布或更新的 ai 服务包括但不限于 stable diffusion 3.5 最强模型全家桶、能操作用户电脑的 cla…
-
哪个模型擅长调用工具?这个7B模型跻身工具调用综合榜单第一
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
【专利】北方华创“一种进气管的清洗方法及半导体工艺设备”专利公布;华海清科“驱动机构的保湿控制方法、晶圆清洗装置、存储介质”专利公布
1.北方华创“一种进气管的清洗方法及半导体工艺设备”专利公布 2.华海清科“驱动机构的保湿控制方法、晶圆清洗装置、存储介质”专利公布 3.清华大学交叉信息研究院段路明课题组首次在离…
-
MIT韩松团队长上下文LLM推理高效框架DuoAttention:单GPU实现330万Token上下文推理
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进1 L = 9 9 H Q 2了学…
-
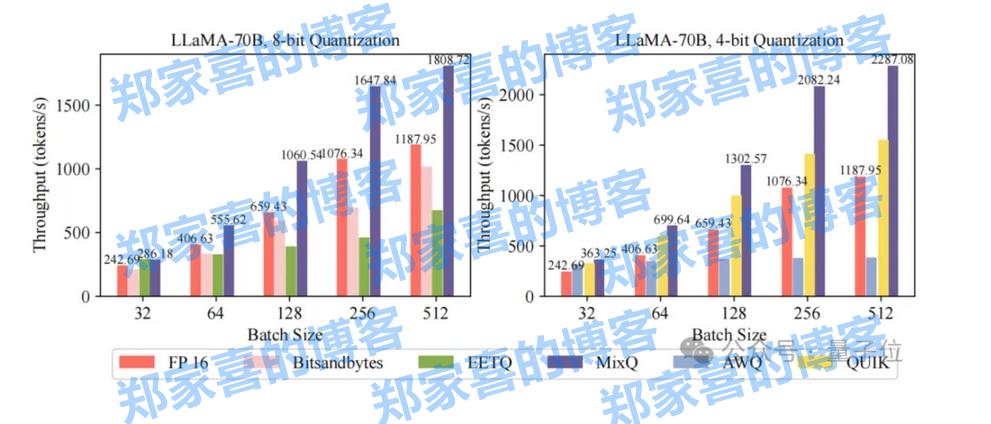
清华开源混合精度推理系统MixQ,实现大模型近无损量化并提升推理吞吐
一键部署llm混合精度推理,端到端吞吐比awq最大提升6倍! 清华大学计算机系PACMAN实验室发布开源混合精度推理系统——MixQ。 MixQ支持8比特和4比特混合精度推理,可实…
-
朱玉可团队新作:看一眼就能模仿,大模型让机器人轻松学会撒盐
在人形机器人领域,有一个非常值钱的问题:既然人形机器人的样子与人类类似,那么它们能使用网络视频等数据进行学习和训练吗? 如果可以,那考虑到网络视频的庞大规模,机器人就再也不用担心没…
-
NeurIPS 2024 | 解锁大模型知识记忆编辑的新路径,浙大用「WISE」对抗幻觉
aixiv专栏是本站发布学术、技术内容的栏目。过去数年,本站aixiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
一夜之间,大模型像人一样操控电脑了!Claude 3.5重磅升级,抢先OpenAI
几个小时前,Claude 3.5 模型迎来了一波大更新。Anthropic 推出了升级版的 Claude 3.5 Sonnet 以及一款新模型 Claude 3.5 Haiku。 …
-
自动化、可复现,基于大语言模型群体智能的多维评估基准Decentralized Arena来了
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术z o 4 T F F h交…
-
132年未解开的李雅普诺夫函数谜题,被Symbolic Transformer攻克了
牛顿没解决的问题,AI给你解决了? AI的推理能力一直是研究的焦点。作为最纯粹、要求最高的推理形式之一,能否解决高级的数学问题,无疑是衡量语言模型推理水平的一把尺。 虽然我们已经见…
-
NeurIPS 2024 | 标签噪声下图神经网络有了首个综合基准库,还开源
aixiv专栏是本站发布学术、技术内容的栏目。过去数年,本站aixiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
还是原装Transformer好!北大清华团队同时揭示Mamba等推理短板
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术7 I + R } R…
-
从结构准确预测蛋白质功能,东北大学「CNN+GCN」统一框架,优于现有方法
编辑 |KX 蛋白质在生物体内扮演着不可或缺的角色,准确预测其功能对于实际应用至关重要。尽管高通量技术促进了蛋白质序列数据的激增,但揭示蛋白质的确切功能仍然需要大量时间和资源。目前…
-
视频生成模型变身智能体:斯坦福Percy Liang等提出VideoAgent,竟能自我优化
现在正是「文本生视频」赛道百花齐放的时代,而且其应用场景非常多,比如生成创意视频内容、创建游戏场景、制作动画和电影。甚至有研究表明还能将视频生成用作真实世界的模拟器,m 0 s f…
-
又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果+ o .您…
-
实测13个类Sora视频生成模型,8000多个案例,一次看个够
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…
-
补齐Transformer规划短板又不放弃快速思考,田渊栋团队的Dualformer融合System 1和2双重优势
一个 token 就能控制模型快些解答或慢点思考。 OpenAI 1 模型的发布掀起了人们对 AI 推理过程的关注,甚至让现在的 AI 行业开始放弃卷越来越大的模型,而是开始针对推…
-
NeurIPS2024 | OCR-Omni来了,字节&华师提出统一的多模态文字理解与生成大模型
研究背景与挑战 在人工智能领域,赋予机器类人的图像文字感知、理解、编辑和生成能力一直是研究热点。目前,视觉文字领域的大模型研究主要聚焦于单模态生成任务。尽管这些模型在某些任务上实现…
-
北大林宙辰团队全新混合序列建模架构MixCon:性能远超Mamba
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工…












{kind=link}